







Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting
作者 | Zili Yi, Qiang Tang, Shekoofeh Azizi, Daesik Jang, Zhan Xu
单位 | 华为技术有限公司(加拿大)
代码 | https://github.com/Ascend-Huawei/Ascend-Canada/tree/master/Models/Research_HiFIll_Model
论文地址|https://arxiv.org/abs/2005.09704
备注 | CVPR 2020 Oral
图像修复
自动填充图像中缺失部分
应用
- 调整目标位置
- 移除不想要的元素
- 修复损坏的图像

当前的方法
-
通过复制来填充
-
从缺失部分附近“借”像素来进行填充
-
e.g., PatchMatch, diffusion-based
-
-
通过建模来填充
- 数据驱动的方式来学习缺失的像素
- e.g., PixelRNN,FCN
-
结合上面两种
- e.g., DeepFill, Patch-Swap
- 这篇文章的方法
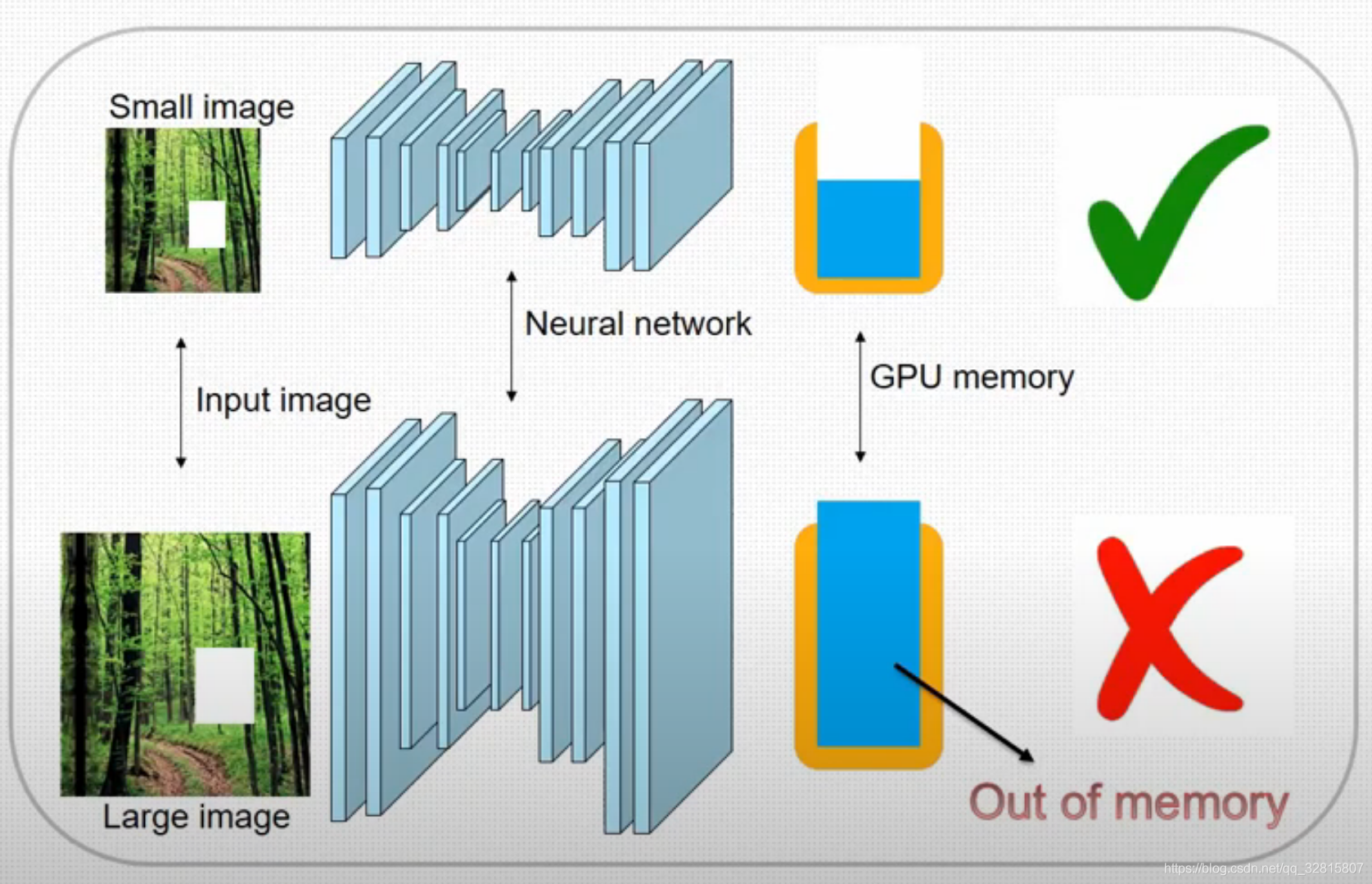
当前基于学习的方法的不足
- 不能够去处理高分辨率图像
- 训练困难
- GPU/NPU内存的限制
- 缺少高分辨率的训练数据集
论文方法
提出了一种上下文残差聚合(CRA)机制,该机制可以通过对上下文补丁中的残差进行加权聚合来生成丢失内容的高频残差,因此网络的训练仅需要低分辨率即可
由于神经网络的卷积层仅需要在低分辨率的输入和输出上进行操作,因此降低了内存和计算能力的成本
此外,还减轻了对高分辨率训练数据集的需求
通过3阶段的pipeline实现高分辨率图像的修复
-
由生成器(Generator)得到低分辨率的修补好的图像
-
通过残差聚合模块得到高频残差
-
合并高频残差和低分辨率修补结果得到高分辨率修补图像
网络结构
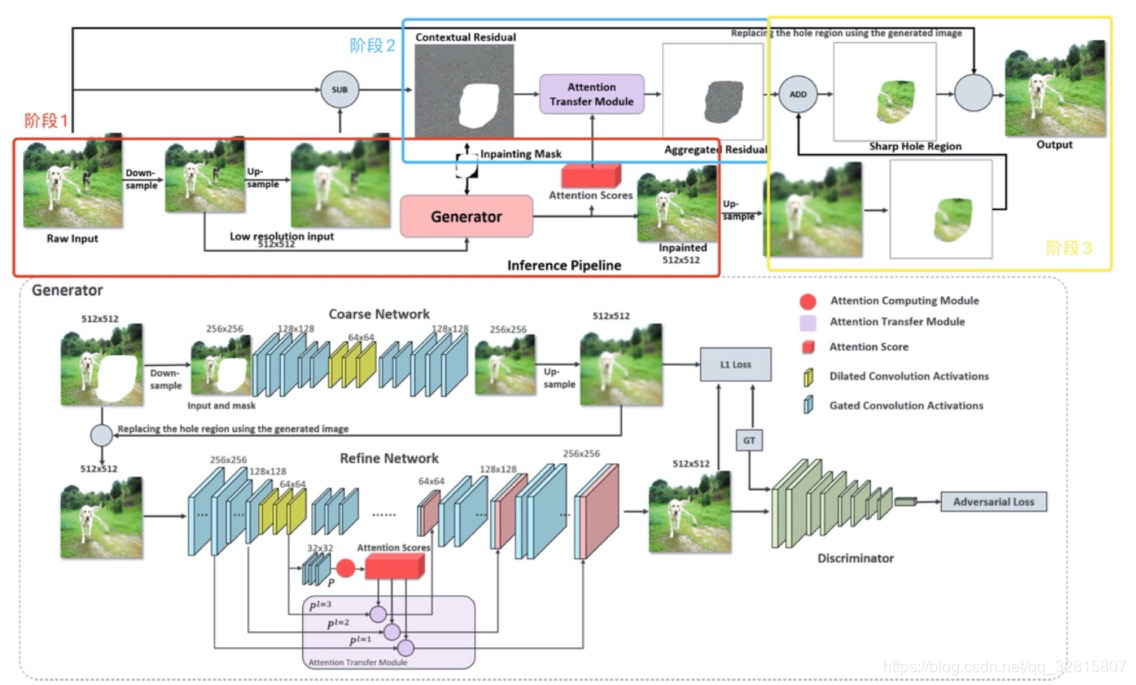
生成器(Generator)
两阶段的coarse-to-fine网络
coarse network输入下采样到256×256的带mask图像,会产生粗略的缺失内容
fine network 通过**Attention Computing Module (ACM)和Attention Transfer Module (ATM)**得到缺失部分内外的关系得分,输出512×512的修复结果
实验

这篇论文的方法在图片分辨率大于1K的情况下修复效率和质量达到了最好

使用预训练好模型的测试结果
结果在缺失部分很大,且上下文环境复杂的情况下,效果看起来并没有很好
在背景单一的风景照中效果很不错

总结
-
提出了一种新颖的上下文残留聚合技术,可对超高分辨率图像进行更高效和高质量的修复
-
把大图下采样到 512×512 ,在分辨率为512×512的小图像上进行图像修复,然后在高分辨率图像上进行推理得到修复效果良好的大图
-
与其他数据驱动方法不同,分辨率和孔尺寸的增加不会降低修补质量,也不会显着增加我们框架中的处理时间
-
到目前为止,是唯一能够在超高分辨率图像(4K至8K)上进行端到端修复的基于学习的技术














 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









