







文章目录
1.前言
如约来到了第三篇。
感觉最近很浮躁,动不动就打好久农药,心里期盼着快点开学,但是听说开学之后要蹲监狱,emmmmm,我还是宅在家吧。待到娱乐场所都开放之时,应该就没这么无聊了。
老师在上这一章的时候,说这不是重点,然而还是讲了洋洋洒洒4节课吧,而且基本上后面的课都讲得我云里雾里,希望自己整理一遍之后能知道更新过程到底在说啥。
2.更新过程简介
在泊松过程中,我曾经提到过泊松过程的第三定义:
对于一串服从均值为
1
/
λ
1/\lambda
1/λ的指数分布的独立同分布的序列
{
X
n
,
n
≥
1
}
\{X_n,n\geq1\}
{Xn,n≥1},事件n发生在时间
S
n
=
Σ
i
=
1
n
X
i
S_n=\Sigma_{i=1}^{n}X_i
Sn=Σi=1nXi
处。这个计数过程也就是服从参数为
λ
\lambda
λ的泊松过程。
也就是说,间隔时服从独立同分布的泊松分布的计数过程,是泊松过程。现在考虑更一般化的间隔时,间隔时服从分布
F
F
F,且为了让这个分布有意义,
F
(
0
)
<
1
F(0)<1
F(0)<1。同时我们还使用
X
n
X_n
Xn表示间隔时,用
μ
\mu
μ表示间隔时的期望,
S
n
S_n
Sn表示到达时,用
N
(
t
)
N(t)
N(t)表示在时间
t
t
t之前发生的事件总数。也就是如下的数学公式:
到达时:
S
0
=
0
,
S
n
=
Σ
i
=
1
n
X
i
,
n
≥
1
S_0=0,S_n=\Sigma_{i=1}^nX_i,n\geq 1
S0=0,Sn=Σi=1nXi,n≥1
间隔时的期望:
μ
=
E
[
X
n
]
=
∫
0
∞
x
d
F
(
x
)
\mu=E[X_n]=\int_0^\infty xdF(x)
μ=E[Xn]=∫0∞xdF(x)
计数值:
N
(
t
)
=
s
u
p
[
n
:
S
n
≤
t
]
N(t)=sup[n:S_n\leq t]
N(t)=sup[n:Sn≤t]
那么,可以看出,泊松过程只是更新过程的一种。如果使用更新过程的属性来定义泊松过程,那就是说泊松过程是间隔时服从均值为
1
/
λ
1/\lambda
1/λ的指数分布的更新过程。
在更新过程中,我们将无差别地使用“事件”和“更新”两个词,也就是说,发生了一次事件和发生了一次更新,在这一章是等价的。
2.1更新过程的一些简单性质
由间隔时独立同分布可知,每个更新阶段都依概率重复,这一性质和泊松过程是一样的。
有限时间内只会发生有限次更新:
依大数定率可知,
lim
n
→
∞
S
n
/
n
→
E
(
S
n
/
n
)
=
E
(
S
n
)
/
n
\lim_{n\to\infty}S_n/n\to E(S_n/n)=E(S_n)/n
limn→∞Sn/n→E(Sn/n)=E(Sn)/n
E
(
S
n
)
/
n
=
E
(
Σ
i
=
1
n
X
i
)
/
n
=
Σ
i
=
1
n
E
(
X
i
)
/
n
=
n
E
(
X
n
)
/
n
=
μ
E(S_n)/n=E(\Sigma_{i=1}^nX_i)/n=\Sigma_{i=1}^nE(X_i)/n=nE(X_n)/n=\mu
E(Sn)/n=E(Σi=1nXi)/n=Σi=1nE(Xi)/n=nE(Xn)/n=μ
所以也可以写成
lim
n
→
∞
S
n
/
μ
=
n
\lim_{n\to\infty}S_n/\mu=n
limn→∞Sn/μ=n
这里的收敛都是依概率收敛。
可以看到,有限的时间内只可能发生有限次的事件。因此,
N
(
t
)
N(t)
N(t)也是有限的,所以可以将
N
(
t
)
N(t)
N(t)中的
s
u
p
sup
sup换为
m
a
x
max
max,即
N
(
t
)
=
m
a
x
[
n
:
S
n
≤
t
]
N(t)=max[n:S_n\leq t]
N(t)=max[n:Sn≤t]
3.主要符号的引入
这一章用了很多的符号,在简介中已经有不少了。这里先列出来,以达到把书读薄,避免混淆的目的。
间隔时:
X
n
X_n
Xn
间隔时服从的分布:
F
F
F
到达时:
S
0
=
0
,
S
n
=
Σ
i
=
1
n
X
i
,
n
≥
1
S_0=0,S_n=\Sigma_{i=1}^nX_i,n\geq 1
S0=0,Sn=Σi=1nXi,n≥1
到达时服从的分布:
F
n
F_n
Fn
间隔时的期望:
μ
=
E
[
X
n
]
=
∫
0
∞
x
d
F
(
x
)
\mu=E[X_n]=\int_0^\infty xdF(x)
μ=E[Xn]=∫0∞xdF(x)
计数值:
N
(
t
)
=
m
a
x
[
n
:
S
n
≤
t
]
N(t)=max[n:S_n\leq t]
N(t)=max[n:Sn≤t]
计数期望:
m
(
t
)
=
E
[
N
(
t
)
]
m(t)=E[N(t)]
m(t)=E[N(t)]
4. N ( t ) N(t) N(t)的分布
从泊松过程中,我们就知道
P
[
N
(
t
)
=
0
]
=
P
[
X
1
>
t
]
=
1
−
P
[
X
1
≤
t
]
=
1
−
F
(
t
)
P[N(t)=0]=P[X_1> t]=1-P[X_1\leq t]=1-F(t)
P[N(t)=0]=P[X1>t]=1−P[X1≤t]=1−F(t)。这个公式很好理解:t时刻计数为0说明第一个事件发生的事件大于t。从这里出发,我们可以计算出
N
(
t
)
N(t)
N(t)的分布:
N
(
t
)
≥
n
<
=
=
>
S
n
≤
t
N(t)\geq n <==>S_n\leq t
N(t)≥n<==>Sn≤t
P
[
N
(
t
)
=
n
]
=
P
[
N
(
t
)
≥
n
]
−
P
[
N
(
t
)
≥
n
+
1
]
=
P
[
S
n
≤
t
]
−
P
[
S
n
+
1
≤
t
]
=
F
n
(
t
)
−
F
n
+
1
(
t
)
P[N(t)=n]=P[N(t)\geq n]-P[N(t)\geq n+1]=P[S_n\leq t]-P[S_{n+1}\leq t]=F_n(t)-F_{n+1}(t)
P[N(t)=n]=P[N(t)≥n]−P[N(t)≥n+1]=P[Sn≤t]−P[Sn+1≤t]=Fn(t)−Fn+1(t)
令
m
(
t
)
=
E
[
N
(
t
)
]
m(t)=E[N(t)]
m(t)=E[N(t)]
我们称
m
(
t
)
m(t)
m(t)为更新函数。多数更新理论都是关注更新函数的性质。
m
(
t
)
m(t)
m(t)可以唯一地决定一个更新过程,调换顺序也成立,证明略去。
4.1 m ( t ) m(t) m(t)的另一种表示
m
(
t
)
=
Σ
n
=
1
∞
F
n
(
t
)
m(t)=\Sigma_{n=1}^\infty F_n(t)
m(t)=Σn=1∞Fn(t)
证明:令
N
(
t
)
=
Σ
n
=
1
∞
I
n
N(t)=\Sigma_{n=1}^\infty I_n
N(t)=Σn=1∞In,其中
I
n
=
{
1
,
若
第
n
次
更
新
在
[
0
,
t
]
内
发
生
0
,
其
他
情
况
I_n=\begin{cases} 1 ,若第n次更新在[0,t]内发生\\ 0,其他情况 \end{cases}
In={1,若第n次更新在[0,t]内发生0,其他情况
这是一个比较老的手法了,在之前的解题中也用过。
所以有
E
[
N
(
t
)
]
=
E
[
Σ
n
=
1
∞
I
n
]
=
Σ
n
=
1
∞
E
[
I
n
]
=
Σ
n
=
1
∞
P
(
S
n
≤
t
)
=
Σ
n
=
1
∞
F
n
(
t
)
E[N(t)]=E[\Sigma_{n=1}^\infty I_n]=\Sigma_{n=1}^\infty E[I_n]=\Sigma_{n=1}^\infty P(S_n \leq t)=\Sigma_{n=1}^\infty F_n(t)
E[N(t)]=E[Σn=1∞In]=Σn=1∞E[In]=Σn=1∞P(Sn≤t)=Σn=1∞Fn(t)
注意:期望和求合符号需要满足非负才可以互换位置。
4.2 m ( t ) m(t) m(t)是有界的
也就是
m
(
t
)
<
∞
,
0
<
t
<
∞
m(t)<\infty,0<t<\infty
m(t)<∞,0<t<∞
证明:由于
P
(
X
n
=
0
)
<
1
P(X_n=0)<1
P(Xn=0)<1,由概率的连续性可知,
∃
α
>
0
,
P
(
X
n
≥
α
)
>
0
\exist\alpha>0,P(X_n\geq \alpha)>0
∃α>0,P(Xn≥α)>0现在我们定义一个截断的更新过程,其间隔时满足
X
‾
n
=
{
0
,
i
f
X
n
<
α
α
,
i
f
X
n
≥
α
\overline{X}_n= \begin{cases} 0,ifX_n<\alpha \\ \alpha ,ifX_n\geq \alpha \end{cases}
Xn={0,ifXn<αα,ifXn≥α
我们令
N
‾
(
t
)
=
s
u
p
{
X
‾
1
+
.
.
.
+
X
‾
n
≤
t
}
\overline{N}(t)=sup\{\overline{X}_1+...+\overline{X}_n \leq t\}
N(t)=sup{X1+...+Xn≤t}。
也就是说,如果某个更新过程的间隔时大于
α
\alpha
α,我们就把它截断为
α
\alpha
α,如果间隔时小于
α
\alpha
α,我们就把它截断为0。用截断后的间隔时作为与之相关的更新过程的间隔时。
这样我们可以明显看出,事件只有可能发生在
α
\alpha
α的整数倍处!因为间隔时只有可能是
α
\alpha
α或者0!在其它地方,是不可能出现更新的。那么,在每个
α
\alpha
α时间内,发生更新的期望是多少呢?
这个可以看作一个几何分布,也就是只要有一次原更新过程间隔时大于
α
\alpha
α,我们认为这个相关的更新过程产生了一次更新。而间隔时大于
α
\alpha
α的概率是固定的。所以这一相关过程
α
\alpha
α时间内计数的期望为
1
P
{
X
n
>
α
}
\frac{1}{P\{X_n>\alpha\}}
P{Xn>α}1
所以
E
[
N
(
t
)
]
≤
E
[
N
‾
(
t
)
]
≤
t
/
α
+
1
P
{
X
n
≥
α
}
≤
∞
E[N(t)]\leq E[\overline{N}(t)]\leq \frac{t/\alpha+1}{P\{X_n\geq\alpha\}}\leq\infty
E[N(t)]≤E[N(t)]≤P{Xn≥α}t/α+1≤∞
第一个等号是由于,间隔时
X
‾
n
≤
X
n
\overline{X}_n\leq X_n
Xn≤Xn,因此相同时间内,截断后的事件计数会更多,就好像效率提高了,相同时间做的事情就多了。因此
N
(
t
)
≤
N
‾
(
t
)
N(t)\leq \overline{N}(t)
N(t)≤N(t)。也就证明了更新函数,即计数值的期望是有界的。
5 一些极限理论
复习到这里,我还是对更新理论没有什么整体的把握。这一节的名字更是差,简直就像是凑数的嘛!
5.1 N ( t ) N(t) N(t)趋向无穷的速率
我们知道,
t
→
∞
,
N
(
t
)
→
∞
t\to\infty, N(t)\to\infty
t→∞,N(t)→∞。现在我们关心
N
(
t
)
N(t)
N(t)以什么样的方式趋向无穷,是线性的,指数的,还是二次的?
N
(
t
)
/
t
=
1
/
μ
,
t
→
∞
N(t)/t=1/\mu,t\to\infty
N(t)/t=1/μ,t→∞
证明:
S
N
(
t
)
/
N
(
t
)
≤
t
/
N
(
t
)
≤
S
N
(
t
)
+
1
/
N
(
t
)
S_{N(t)}/N(t) \leq t/N(t)\leq S_{N(t)+1}/N(t)
SN(t)/N(t)≤t/N(t)≤SN(t)+1/N(t)
而
S
N
(
t
)
/
N
(
t
)
→
μ
,
t
→
∞
S_{N(t)}/N(t)\to \mu, t\to\infty
SN(t)/N(t)→μ,t→∞
S
N
(
t
)
+
1
/
N
(
t
)
=
S
N
(
t
)
+
1
N
(
t
)
+
1
×
N
(
t
)
+
1
N
(
t
)
S_{N(t)+1}/N(t)=\frac{S_{N(t)+1}}{N(t)+1}\times \frac{N(t)+1}{N(t)}
SN(t)+1/N(t)=N(t)+1SN(t)+1×N(t)N(t)+1
N
(
t
)
+
1
N
(
t
)
→
1
,
t
→
∞
\frac{N(t)+1}{N(t)}\to1,t\to\infty
N(t)N(t)+1→1,t→∞
因此
S
N
(
t
)
+
1
/
N
(
t
)
→
μ
S_{N(t)+1}/N(t)\to \mu
SN(t)+1/N(t)→μ
因此根据夹逼定理,命题得证。
Example3.3A 一个罐子有有无限枚硬币,但是每一枚硬币都有自己的正面朝上的概率。这个概率服从(0,1)之间的均匀分布。假如我们在任意时刻,都有权选择继续投当前的硬币或拿一枚新的硬币。如果不停地抛掷硬币,而且我们的目标是为了最大化的正面朝上的比率,我们应该怎么怎么做?
这个题目有点意思。命运无常,但是我们可以自己选择继续当前的路或者选择一条新路。从这道题的答案可以看出,人的主观能动性是可以排除命运干扰,走出自己的阳关大道的!!!
好了,鸡汤喝完了,我们解题,解完题还有一口毒鸡汤。
我先给出答案中的策略:如果翻到正面,那就继续使用这枚硬币;如果出现反面,我们就换新的。
可以看到,采用这种策略,我们就可以定义一个更新过程:以拿新硬币为一个更新过程的开始,抛到反面为更新过程的结尾。因此每枚硬币的抛掷过程,都是完全重复的。我们定义某一枚硬币正面朝上的概率为p,在前n次抛掷中,出现了N(n)次反面。那么我们的正面朝上比率为
P
h
=
1
−
l
i
m
n
→
∞
N
(
n
)
/
n
P_h=1-lim_{n\to\infty}N(n)/n
Ph=1−limn→∞N(n)/n
从刚刚的定理可以知道
l
i
m
n
→
∞
N
(
n
)
/
n
=
1
/
E
(
每
次
更
新
的
时
间
间
隔
)
lim_{n\to\infty}N(n)/n=1/E(每次更新的时间间隔)
limn→∞N(n)/n=1/E(每次更新的时间间隔)
而我们的策略,对于每一枚硬币来说,投掷硬币的次数是服从几何分布的。因此
E
(
每
次
更
新
的
时
间
间
隔
)
=
E
(
抛
出
反
面
之
前
抛
出
的
正
面
次
数
+
1
)
=
E
(
1
/
(
1
−
p
)
)
=
∞
E(每次更新的时间间隔)=E(抛出反面之前抛出的正面次数+1)=E(1/(1-p))=\infty
E(每次更新的时间间隔)=E(抛出反面之前抛出的正面次数+1)=E(1/(1−p))=∞
最后的无穷是由对概率进行积分得出的期望。
因此
P
h
=
1
−
l
i
m
n
→
∞
N
(
n
)
/
n
=
1
−
1
/
∞
=
1
P_h=1-lim_{n\to\infty}N(n)/n=1-1/\infty=1
Ph=1−limn→∞N(n)/n=1−1/∞=1
也就是我们依概率稳赢。
当然啦,(回到刚刚的鸡汤)人生不是无限的,无法尝试每一种可能,所以我们也没法一定能遇到贼tm好的机会,牢牢把握住,获得赢家人生;我们也没法每次都这么理性的采取这种策略,人还是贪心的,或者舍不得自己的付出;而且命运给的机会,好坏也不全是均匀分布的,一般来说高斯分布比较符合吧!所以这道题可以是甜鸡汤,也能是一碗毒鸡汤。
5.2 Wald方程
5.2.1 停止时的概念
我们首先引入停止时的概念:对于一个整数变量N,如果它只和序列
{
X
1
,
.
.
.
,
X
n
,
X
n
+
1
,
.
.
.
}
\{X_1,...,X_n,X_{n+1},...\}
{X1,...,Xn,Xn+1,...}中的
{
X
1
,
.
.
.
X
n
}
\{X_1,...X_n\}
{X1,...Xn}有关,而且独立于
{
X
n
+
1
,
.
.
.
}
\{X_{n+1},...\}
{Xn+1,...},那么我们称
{
N
=
n
}
\{N=n\}
{N=n}是一个停止时。
再直观一点解释,就是说,只要观察前N部分就能判断停止时的发生了。再举个例子说,就是比方说我们打游戏的时候,说:
赢
一
把
就
不
玩
了
!
赢一把就不玩了!
赢一把就不玩了!
如果观测到第n把的时候,赢了,那我们就停止游戏,理想情况下我们不会再打第n+1把了,所以可以说n是一个停止时。虽然一般来说还会忍不住接着往下打,理由也很多,赢得太简单啊,没打C位啊,队友太强啊。
还可以比方说,我们立一个flag:
今
天
11
点
就
睡
!
今天11点就睡!
今天11点就睡!
后面的就不说了,大家都懂
5.2.2 Wald方程
若
X
n
X_n
Xn表示独立同分布的,期望有限的变量,且
N
N
N为这个序列的停止时。那么我们有:
E
[
Σ
1
N
X
n
]
=
E
[
N
]
E
[
X
]
E[\Sigma_1^NX_n]=E[N]E[X]
E[Σ1NXn]=E[N]E[X]
证明:令
I
n
=
{
1
,
N
≥
n
0
,
N
<
n
=
=
>
Σ
1
N
X
n
=
Σ
1
∞
X
n
I
n
I_n=\begin{cases} 1 ,N\geq n\\ 0,N<n \end{cases} ==>\Sigma_1^N X_n=\Sigma_1^\infty X_nI_n
In={1,N≥n0,N<n==>Σ1NXn=Σ1∞XnIn
所以
E
[
Σ
1
N
X
n
]
=
Σ
1
∞
E
[
X
n
I
n
]
E[\Sigma_1^NX_n]=\Sigma_1^\infty E[X_nI_n]
E[Σ1NXn]=Σ1∞E[XnIn]
由于
I
n
I_n
In只决定于
X
i
X_i
Xi的前
n
−
1
n-1
n−1项。因为如果
I
n
=
0
I_n=0
In=0,说明停止时至少在
n
−
1
n-1
n−1处已经发生了!
n
n
n是停止时之后的第一项!这点很重要,这说明了,
I
n
I_n
In和
X
n
X_n
Xn是相互独立的,期望可以拆开。
E
[
Σ
1
N
X
n
]
=
Σ
1
∞
E
[
X
n
]
E
[
I
n
]
=
E
[
X
]
Σ
1
∞
E
[
I
n
]
=
E
[
X
]
E
[
Σ
1
∞
I
n
]
=
E
[
N
]
E
[
X
]
E[\Sigma_1^NX_n]=\Sigma_1^\infty E[X_n]E[I_n]= E[X]\Sigma_1^\infty E[I_n]=E[X] E[\Sigma_1^\infty I_n]=E[N]E[X]
E[Σ1NXn]=Σ1∞E[Xn]E[In]=E[X]Σ1∞E[In]=E[X]E[Σ1∞In]=E[N]E[X]
证毕。
Example3.3如果我们抛掷一枚均匀的硬币,正面得分1,反面得分0,令N表示我们第一次累计得分为10的抛掷次数,请问N的期望是多少?如果正面得分1,反面得分-1呢?
这道题很明显,N是一个停止时。所以直接用上面的公式,先看反面得分为0的情况:
10
=
E
[
Σ
1
N
X
n
]
=
E
[
N
]
E
[
X
]
=
0.5
E
(
N
)
=
>
E
(
N
)
=
20
10=E[\Sigma_1^NX_n]=E[N]E[X]=0.5E(N)=>E(N)=20
10=E[Σ1NXn]=E[N]E[X]=0.5E(N)=>E(N)=20
再看反面得分为-1的情况:
10
=
E
[
Σ
1
N
X
n
]
=
E
[
N
]
E
[
X
]
=
0
E
(
N
)
=
>
E
(
N
)
=
∞
10=E[\Sigma_1^NX_n]=E[N]E[X]=0E(N)=>E(N)=\infty
10=E[Σ1NXn]=E[N]E[X]=0E(N)=>E(N)=∞
竟然出来了个无穷?我们先放着无穷的不管,有穷的结果还是令人满意的,求解过程挺简洁。
5.2.3 更新过程中的停止时
假如我们在时间t后发生第一次更新时停止。那么
N
(
t
)
+
1
N(t)+1
N(t)+1就是一个停止时。原因:
N
(
t
)
+
1
=
n
<
=
=
>
N
(
t
)
=
n
−
1
<
=
=
>
X
1
+
.
.
.
+
X
n
−
1
≤
t
而
且
X
1
+
.
.
.
+
X
n
>
t
N(t)+1=n<==>N(t)=n-1<==>X_1+...+X_{n-1}\leq t而且X_1+...+X_{n}>t
N(t)+1=n<==>N(t)=n−1<==>X1+...+Xn−1≤t而且X1+...+Xn>t
只有在t之后第一件事发生,才能断定是停止时。为什么不是t之前的最后一件事呢?因为在t过完之前,我们不可能知道这是最后一件事啊!就好像我们在人生起起落落落落落落落落时,总想着,
这
回
倒
霉
之
后
肯
定
要
转
运
了
!
这回倒霉之后肯定要转运了!
这回倒霉之后肯定要转运了!
但是不到真的某一次碰到好运的时候,你能说自己真的转运了吗!即使好运一次之后,又是不断地落落落,那也算是一个倒霉过程停止了(只不过另一个倒霉过程又开始了)。
回到正题。这说明:
E
[
S
N
(
t
)
+
1
]
=
E
[
X
1
+
.
.
.
+
X
N
(
t
)
+
1
]
=
E
[
X
]
E
[
N
(
t
)
]
=
μ
[
m
(
t
)
+
1
]
E[S_{N(t)+1}]=E[X_1+...+X_{N(t)+1}]=E[X]E[N(t)]=\mu [m(t)+1]
E[SN(t)+1]=E[X1+...+XN(t)+1]=E[X]E[N(t)]=μ[m(t)+1]
5.2.4 初等更新定理
看这题目就觉得很NB,这一章叫做更新过程,那更新定理岂不是其中最重要的东西了?
说实话,上课老师提到更新定理的时候,我蒙圈了好久,不知道更新定理是什么定理。结果就是下面这个公式??
m
(
t
)
/
t
→
1
/
μ
,
t
→
∞
m(t)/t\to 1/\mu,t\to\infty
m(t)/t→1/μ,t→∞
定理的证明过程我不想抄了,主要就是利用了上一节的
E
[
S
N
(
t
)
+
1
]
=
μ
[
m
(
t
)
+
1
]
E[S_{N(t)+1}]=\mu [m(t)+1]
E[SN(t)+1]=μ[m(t)+1]这个结论,并且利用
S
N
(
t
)
+
1
≥
t
S_{N(t)+1}\geq t
SN(t)+1≥t,两边取期望,可以得到我们想证明的极限的下界。然后再利用它的相关过程:截断过程
S
‾
N
(
t
)
+
1
≤
t
+
M
\overline{S}_{N(t)+1}\leq t+M
SN(t)+1≤t+M,取期望,得到极限的上界。
我们看着这个定理。我再把这两个符号解释一下:
μ
=
E
[
X
n
]
\mu=E[X_n]
μ=E[Xn]
m
(
t
)
=
E
[
N
(
t
)
]
m(t)=E[N(t)]
m(t)=E[N(t)]
把它们带入,得到
E
[
N
(
t
)
]
/
t
→
1
/
μ
,
t
→
∞
E[N(t)]/t\to 1/\mu,t\to\infty
E[N(t)]/t→1/μ,t→∞
我们再回到上面的一个极限的结论:
N
(
t
)
/
t
→
1
/
μ
,
t
→
∞
N(t)/t\to 1/\mu,t\to\infty
N(t)/t→1/μ,t→∞
欸,证明了这么久的定理,怎么和这个似曾相识?拿之前的结论两边直接取极限不完就了吗!
这是不对的。我们可以把这个问题抽象为逐点收敛和积分收敛的问题。
一个函数收敛到0,那它的积分也能收敛到0吗?考虑一个函数,其中U为(0,1)间均匀分布
Y
n
=
{
0
,
U
>
1
/
n
n
,
U
≤
1
/
n
Y_n=\begin{cases} 0,U>1/n \\ n,U\leq 1/n \end{cases}
Yn={0,U>1/nn,U≤1/n
它是收敛到0的。但是它的期望
E
(
Y
n
)
=
n
P
[
U
≤
1
/
n
]
=
1
E(Y_n)=nP[U\leq 1/n]=1
E(Yn)=nP[U≤1/n]=1
说明函数收敛到0和期望收敛到0并不能等价。
5.2.5 N ( t ) N(t) N(t)的中心极限分布
当 t → ∞ t\to\infty t→∞时, N ( t ) → ( t / μ , t σ 2 / μ 3 ) N(t)\to (t/\mu,t\sigma^2/\mu^3) N(t)→(t/μ,tσ2/μ3)的正态分布。其中 μ , σ 2 \mu,\sigma^2 μ,σ2分别表示间隔时的均值和方差。证明略去(懒)
6 关键更新定理及其应用
首先解释“格”的概念:
如果
Σ
n
=
0
∞
P
[
X
=
n
d
]
=
1
\Sigma_{n=0}^\infty P[X=nd]=1
Σn=0∞P[X=nd]=1
也就是,更新只可能发生在d的整数倍的点上,那么我们称这种更新过程是带格的。反之,则说它是不带格的。
sorry,这一节后面的我看吐了,竟然有卷积,暂且跳过
20200521:昨天上了复习课之后,对关键更新定理有了更好的理解,因此删去这句不成熟的话。
6.1 Blackwell定理
i)如果F不是带格的,那么
t
→
∞
,
m
(
t
+
a
)
−
m
(
t
)
→
a
/
μ
t\to\infty,m(t+a)-m(t)\to a/\mu
t→∞,m(t+a)−m(t)→a/μ
ii)如果F周期为d,那么
n
→
∞
,
E
[
n
d
处
发
生
更
新
的
次
数
]
→
d
/
μ
n\to\infty,E[nd处发生更新的次数]\to d/\mu
n→∞,E[nd处发生更新的次数]→d/μ
6.2 关键更新定理
如果F是非周期的,
h
(
t
)
h(t)
h(t)是直接黎曼可积的,那么有:
lim
t
→
∞
=
∫
0
t
h
(
t
−
x
)
d
m
(
x
)
=
1
/
μ
∫
0
t
h
(
x
)
d
x
\lim_{t\to\infty}=\int _0^th(t-x)dm(x)=1/\mu\int _0^th(x)dx
t→∞lim=∫0th(t−x)dm(x)=1/μ∫0th(x)dx
其中
m
(
x
)
,
μ
m(x),\mu
m(x),μ的定义是本章的惯用符号,而
h
(
x
)
h(x)
h(x)只需要满足直接黎曼可积的条件下,任意都可。
我们从Blackwell定理出发,可以推导出关键更新定理:
lim
t
→
∞
m
(
t
+
a
)
−
m
(
t
)
=
a
/
μ
=
>
lim
t
→
∞
lim
a
→
0
[
m
(
t
+
a
)
−
m
(
t
)
]
/
a
=
lim
t
→
∞
d
m
(
t
)
/
d
t
=
1
/
μ
\lim_{t\to\infty}m(t+a)-m(t)= a/\mu=>\lim_{t\to\infty}\lim_{a\to0}[m(t+a)-m(t)]/a=\lim_{t\to\infty}dm(t)/dt= 1/\mu
t→∞limm(t+a)−m(t)=a/μ=>t→∞lima→0lim[m(t+a)−m(t)]/a=t→∞limdm(t)/dt=1/μ
也就是说,关键更新定理说明了一件事,那就是
t
→
∞
,
m
′
(
t
)
=
1
/
μ
t\to\infty,m'(t)=1/\mu
t→∞,m′(t)=1/μ
6.3 关键更新定理的应用
上面的结论要在下面的交替更新过程的推导中用到。
在这之前,给出一个概率分布。这个概率解释为,在当前时间之前发生的最后一件事的到达时的分布。
P
[
S
N
(
t
)
≤
s
]
=
Σ
n
=
0
∞
P
[
S
n
≤
s
,
S
n
+
1
>
s
]
=
F
‾
(
t
)
+
Σ
n
=
1
∞
P
[
S
n
≤
s
,
S
n
+
1
>
s
]
=
F
‾
(
t
)
+
Σ
n
=
1
∞
∫
0
s
P
[
S
n
≤
s
,
S
n
+
1
>
s
∣
S
n
=
y
]
P
[
S
n
=
y
]
d
y
=
F
‾
(
t
)
+
Σ
n
=
1
∞
∫
0
s
P
[
S
n
≤
s
,
S
n
+
1
>
s
∣
S
n
=
y
]
d
F
n
(
y
)
=
F
‾
(
t
)
+
∫
0
s
P
[
X
n
+
1
>
s
−
y
]
Σ
n
=
1
∞
d
F
n
(
y
)
=
F
‾
(
t
)
+
∫
0
s
F
‾
(
s
−
y
)
d
m
(
y
)
\begin{aligned} P[S_{N(t)}\leq s]&=\Sigma_{n=0}^\infty P[S_n\leq s,S_{n+1}>s] \\ &= \overline F(t)+ \Sigma_{n=1}^\infty P[S_n\leq s,S_{n+1}>s] \\ &=\overline{F}(t)+ \Sigma_{n=1}^\infty\int_0^s P[S_n\leq s,S_{n+1}>s|S_n=y]P[S_n=y]dy\\ &=\overline{F}(t)+ \Sigma_{n=1}^\infty\int_0^s P[S_n\leq s,S_{n+1}>s|S_n=y]dF_n(y)\\ &=\overline{F}(t)+ \int_0^s P[X_{n+1}>s-y]\Sigma_{n=1}^\infty dF_n(y)\\ &=\overline{F}(t)+\int_0^s \overline{F}(s-y)dm(y) \\ \end{aligned}
P[SN(t)≤s]=Σn=0∞P[Sn≤s,Sn+1>s]=F(t)+Σn=1∞P[Sn≤s,Sn+1>s]=F(t)+Σn=1∞∫0sP[Sn≤s,Sn+1>s∣Sn=y]P[Sn=y]dy=F(t)+Σn=1∞∫0sP[Sn≤s,Sn+1>s∣Sn=y]dFn(y)=F(t)+∫0sP[Xn+1>s−y]Σn=1∞dFn(y)=F(t)+∫0sF(s−y)dm(y)
7 交替更新过程
交替更新过程是关键更新定理的应用
考虑这样一种系统:它拥有两个状态,开或者关。我们默认它初始是开的状态,它开了
Z
1
Z_1
Z1时间,然后关。它关了
Y
1
Y_1
Y1时间,然后又开
Z
2
Z_2
Z2时间,然后又关,又开,……
我们先做一个假设:每个开过程的时间分布,都是独立同分布的;关也一样。但是在一个开关周期内(先开,后关),开、关的时间可以是不独立的。同时,我们用
H
,
G
H,G
H,G表示
Z
n
,
Y
n
Z_n,Y_n
Zn,Yn的分布,
F
F
F表示间隔时,也就是
Z
n
+
Y
n
Z_n+Y_n
Zn+Yn的分布。
7.1 开、关概率的极限分布
说实话,我不知道该怎么概括这个定理。但是这个定理我觉得是这一节最重要的东西,简单又好用。
若
E
(
Z
n
+
Y
n
)
<
∞
E(Z_n+Y_n)<\infty
E(Zn+Yn)<∞且F不是带格的,那么有
lim
t
→
∞
P
(
t
)
=
E
(
Z
n
)
/
[
E
(
Z
n
)
+
E
(
Y
n
)
]
\lim_{t\to\infty} P(t)=E(Z_n)/[E(Z_n)+E(Y_n)]
t→∞limP(t)=E(Zn)/[E(Zn)+E(Yn)]
其中,
P
(
t
)
P(t)
P(t)代表在t时刻,这个系统处于‘开’状态的概率。
定理很好理解,我也懒得证明了。
比方说上课40分钟,下课5分钟,无限循环。假如某天我们没有带表,请问我们走进教室,正在上课的概率是?
但是为什么t要趋向于无穷啊啊啊啊啊啊啊?!!
接下来现在的我还是证明一下这个曾经的我不太理解的定理。
首先我们将t时刻为on分为两种情况:处于第一次更新过程,已经经历过至少一次完整的更新过程:
P
(
t
)
=
P
[
o
n
∣
S
N
(
t
)
=
0
]
P
[
S
N
(
t
)
=
0
]
+
∫
0
t
P
[
o
n
∣
S
N
(
t
)
=
y
]
d
F
S
N
(
t
)
(
y
)
=
H
‾
(
t
)
/
F
‾
(
t
)
×
F
‾
(
t
)
+
∫
0
t
H
‾
(
t
−
y
)
/
F
‾
(
t
−
y
)
×
F
‾
(
t
−
y
)
d
m
(
y
)
=
H
‾
(
t
)
+
∫
0
t
H
‾
(
t
−
y
)
d
m
(
y
)
\begin{aligned} P(t)&=P[on|S_{N(t)}=0]P[S_{N(t)}=0]+\int_0^tP[on|S_{N(t)}=y]dF_{S_{N(t)}}(y)\\ &=\overline{H}(t)/\overline{F}(t)\times\overline{F}(t)+\int_0^t \overline{H}(t-y)/\overline{F}(t-y)\times \overline{F}(t-y)dm(y)\\ &=\overline{H}(t)+\int_0^t \overline{H}(t-y)dm(y) \end{aligned}
P(t)=P[on∣SN(t)=0]P[SN(t)=0]+∫0tP[on∣SN(t)=y]dFSN(t)(y)=H(t)/F(t)×F(t)+∫0tH(t−y)/F(t−y)×F(t−y)dm(y)=H(t)+∫0tH(t−y)dm(y)
第二行的后半段,是利用了
P
[
S
N
(
t
)
≤
s
]
=
F
‾
(
t
)
+
∫
0
s
F
‾
(
s
−
y
)
d
m
(
y
)
P[S_{N(t)}\leq s]=\overline{F}(t)+\int_0^s \overline{F}(s-y)dm(y)
P[SN(t)≤s]=F(t)+∫0sF(s−y)dm(y)对s的导数。
此时,我们令
t
→
∞
t\to\infty
t→∞,再采用关键更新定理,就能得到:
lim
t
→
∞
P
(
t
)
=
H
‾
(
∞
)
+
1
/
μ
∫
0
∞
H
‾
(
y
)
d
y
=
0
+
E
(
Z
)
/
μ
=
E
(
Z
)
/
[
E
(
Z
)
+
E
(
Y
)
]
\lim_{t\to\infty} P(t)=\overline{H}(\infty)+1/\mu\int_0^\infty \overline{H}(y)dy=0+E(Z)/\mu=E(Z)/[E(Z)+E(Y)]
t→∞limP(t)=H(∞)+1/μ∫0∞H(y)dy=0+E(Z)/μ=E(Z)/[E(Z)+E(Y)]
原命题得证。
一开始我看着关键更新定理这个卷积公式就头疼,但是后来发现,并非它以卷积形式定义,而是它就写成这种形式,并且有的时候我们恰好就会得到这种形式的式子,因此可以套进去解答。从证明过程中可以看到,的确用到了关键更新定理。
7.2 年龄和剩余寿命的分布
假如我们定义年龄
A
(
t
)
A(t)
A(t)为当前更新阶段,经过的时间,也就是
A
(
t
)
=
t
−
S
N
(
t
)
A(t)=t-S_{N(t)}
A(t)=t−SN(t)
我们希望得到
A
(
t
)
A(t)
A(t)的分布。
这个又是什么意思呢!我们说一个看电影的例子。假如电影院接连不断地放电影,每一部电影时间长度也不一定一样。我是一个白嫖党,偷偷蹲在厕所里,假装是出来上厕所回影厅的观众。我还比较希望能完整地看完一部电影,所以开场30分钟以上的电影我就不想看了。我比较关心某个时刻,我从厕所出来进入影厅,当前电影开映小于30分钟的概率。
这个概率要分为两部分求。假如这部电影本身就小于30分钟,那我任意时刻进去都满足我的要求(虽然不是很符合我的本意);假如这部电影大于30分钟,那我就不一定能在想要的时间进入影厅了。我们把这个过程看作一个交替更新过程,开表示进去之后电影开映小于等于30分钟,关表示进去之后电影开映大于30分钟。利用上面一节求出的概率分布
lim
t
→
∞
P
[
Y
(
t
)
≤
x
]
=
E
[
min
(
X
,
x
)
]
/
E
[
X
]
=
∫
0
∞
P
[
min
(
X
,
x
)
>
y
]
d
y
/
μ
=
∫
0
x
P
[
X
>
y
]
d
y
/
μ
\lim_{t\to\infty} P[Y(t)\leq x]=E[\min(X,x)]/E[X]=\int_0^\infty P[\min(X,x)>y]dy/\mu=\int_0^x P[X>y]dy/\mu
t→∞limP[Y(t)≤x]=E[min(X,x)]/E[X]=∫0∞P[min(X,x)>y]dy/μ=∫0xP[X>y]dy/μ
第一个等号的含义我之前已经解释过了;第二个等号是用一个比较老的手法,令
I
y
=
0
,
1
I_y=0,1
Iy=0,1,其中1表示当前更新阶段经过的时间不到y;第三个等号,首先看积分上限,是由于
x
≥
min
(
X
,
x
)
>
y
x\geq \min(X,x)>y
x≥min(X,x)>y,所以如果
y
>
x
y>x
y>x,这个概率直接清零,因此丢弃
y
>
x
y>x
y>x的部分,而在
x
>
y
x>y
x>y的前提下,
min
(
X
,
x
)
>
y
\min(X,x)>y
min(X,x)>y的概率就是
X
>
y
X>y
X>y的概率。
Example3.4A.假如顾客到达某个商店的间隔时服从 F F F分布,每位顾客买商品的个数服从分布 G G G,且顾客的数量和单个顾客购买的商品数量相互独立。这个商店只有一个货架。商店采用如下的补货策略:当货架上的货少于 s s s个时,直接补满到 S S S个。补货是立即完成的。起始时刻,货架是满的。我们想知道货架上货物个数在时间 t → ∞ t\to\infty t→∞时的分布。
当然,我觉得这道题还得假设一下,顾客是不可能把商品上的货物买到断货(负数)的。
我们先用上上面的结论,把补货过程看作一个更新过程,用
X
(
t
)
X(t)
X(t)表示t时刻货架上剩下的货物数量,写出第一个等式:
lim
t
→
∞
P
[
X
(
t
)
≥
x
]
=
E
[
货
架
上
货
物
多
于
x
的
时
间
]
/
E
[
补
货
周
期
的
长
度
]
\lim_{t\to\infty} P[X(t)\geq x]=E[货架上货物多于x的时间]/E[补货周期的长度]
t→∞limP[X(t)≥x]=E[货架上货物多于x的时间]/E[补货周期的长度]
由于买货是顾客的行为,一位顾客进来,买一次商品。所以补货周期等于从货架为满时开始算,到第一位把货架上的货消耗到小于
s
s
s的顾客到来所经过的时间。而货架上货物多于x的时间,等于从货架为满时开始算,到第一位把货架上的货消耗到小于
s
s
s的顾客到来所经过的时间。所以
补货周期=
Σ
1
N
s
X
i
\Sigma_1^{N_s}X_i
Σ1NsXi
货架上多于x个货物的时间=
Σ
1
N
x
X
i
\Sigma_1^{N_x}X_i
Σ1NxXi
其中
N
s
,
N
x
N_s,N_x
Ns,Nx分别表示从货架为满时开始算,到第一位把货架上的货消耗到小于
s
,
x
s,x
s,x的序号。
由于单个顾客买货物的数量与顾客到来是相互独立的,取期望之后可以作简化。
E
[
货
架
上
货
物
多
于
x
的
时
间
]
/
E
[
补
货
周
期
的
长
度
]
=
E
[
Σ
1
N
s
X
i
]
/
E
[
Σ
1
N
x
X
i
]
=
E
(
N
x
)
E
(
X
)
/
[
E
(
N
s
)
E
(
X
)
]
=
E
(
N
x
)
/
E
(
N
s
)
E[货架上货物多于x的时间]/E[补货周期的长度]=\\E[\Sigma_1^{N_s}X_i]/E[\Sigma_1^{N_x}X_i]=E(N_x)E(X)/[E(N_s)E(X)]=E(N_x)/E(N_s)
E[货架上货物多于x的时间]/E[补货周期的长度]=E[Σ1NsXi]/E[Σ1NxXi]=E(Nx)E(X)/[E(Ns)E(X)]=E(Nx)/E(Ns)
接下来我们啃这俩N的期望。我们把顾客买商品的过程,也看成一个更新过程——只考虑买,不考虑补货,把每位顾客买走的商品个数看作间隔时,把顾客买走的商品总数看作到达时。这样,就可以使用计数期望:
m
(
t
)
=
E
[
N
(
t
)
]
m(t)=E[N(t)]
m(t)=E[N(t)]来求解了!
首先弄清两个事情:如果t时刻,某位顾客买完商品之后,货架上只剩下
x
x
x件商品,这时的情况符合我们要求的情况吗?符合!由于数量是整数,所以下一位顾客来了
X
(
t
)
≥
x
X(t)\geq x
X(t)≥x的状态才终结!
同样的,如果某位顾客买完商品之后,货架上只剩下
s
s
s件商品,我们需要补货吗?不需要!补货是下一位顾客来了之后才要做的!
所以,我们搬出
m
(
t
)
=
E
[
N
(
t
)
]
m(t)=E[N(t)]
m(t)=E[N(t)]可以有:
E
[
N
x
−
1
]
=
m
(
S
−
x
)
,
E
[
N
s
−
1
]
=
m
(
S
−
s
)
E[N_x-1]=m(S-x),E[N_s-1]=m(S-s)
E[Nx−1]=m(S−x),E[Ns−1]=m(S−s)
把1挪到右边去,就可以得出我们想要的概率:
lim
t
→
∞
P
[
X
(
t
)
≥
x
]
=
m
(
S
−
x
)
+
1
m
(
S
−
s
)
+
1
,
s
≤
x
≤
S
\lim_{t\to\infty} P[X(t)\geq x]=\frac{m(S-x)+1}{m(S-s)+1},s\leq x \leq S
t→∞limP[X(t)≥x]=m(S−s)+1m(S−x)+1,s≤x≤S
8 延时更新过程和简单随机游走
这两个知识分别对应书上的5和7节,理论上是应该分开的,但是老师是让我们课后学习,而且后续马尔可夫过程的时候也有用到,所以就简单提一下。
8.1 延时更新过程
延时更新过程的定义是,从第二次更新开始,间隔时都是独立同分布的随机变量;第一次更新可能遵循不同的分布。举个例子,就像任意一个时刻开始,观察一个更新过程,由于进入的时间是任意的,所以第一次观察到的更新间隔时可能会更短一点。
8.2 对称简单随机游走
首先介绍一下简单随机游走。这里以一维的为例讲解。
在一个数轴上,某质点以0为起点,任意时刻都随机向左或者向右走一步,这一过程可以抽象成简单随机游走过程。
如果向左或者向右走的概率相同,那么就称之为对称简单随机游走。
比方说,赌徒抛硬币,正面得一分,反面得-1分,这个得分的轨迹就是个对称简单随机游走的过程。
接下来,研究简单随机游走的几个性质:
质点某一时刻处于原点的概率
质点某一时刻第一次回到原点的概率
质点某一时刻从未回到原点的概率
质点回到原点之后的行为
质点到某一时刻之前,处于正半轴和负半轴的时间长度分布
8.2.1 质点某一时刻第一次回到原点的概率
首先,我们计算一下质点某一时刻处于原点的概率。这个概率很简单:奇数次游走,一定不可能回到原点,那么在某个偶数
2
n
2n
2n次时,如果回到原点,等同于一共抛出了n个正面和n个反面。我们把当前的积分记作
Z
2
n
Z_{2n}
Z2n,它的概率记作
u
n
u_n
un,得到:
u
n
=
P
(
Z
2
n
=
0
)
=
C
2
n
n
(
1
/
2
)
2
n
u_n=P(Z_{2n}=0)=C_{2n}^n(1/2)^{2n}
un=P(Z2n=0)=C2nn(1/2)2n
这个结果是比较容易就能得到的。接下来我们考虑质点某一时刻第一次回到原点的概率。可以考虑如下的场景(来自于第一章的一个例题):
Example 1.5E 考虑一个选举场景,有两个候选人A和B。假如最终A得了n票,B得了m票,且n>m。假设每位选民投给俩人的概率都相等,求证A一直领先B的概率为(n-m)/(n+m)
首先将情况分为A得到了最后一张票和B得到了最后一张票。那么这个概率(其实是已知A得了n票,B得了m票的条件概率)可以写为:
P
(
A
一
直
到
t
时
刻
都
领
先
B
)
=
P
(
A
一
直
到
t
−
1
时
刻
都
领
先
B
,
A
得
最
后
一
票
)
+
P
(
A
一
直
到
t
−
1
时
刻
都
领
先
B
,
B
得
最
后
一
票
)
P(A一直到t时刻都领先B)=P(A一直到t-1时刻都领先B,A得最后一票)+P(A一直到t-1时刻都领先B,B得最后一票)
P(A一直到t时刻都领先B)=P(A一直到t−1时刻都领先B,A得最后一票)+P(A一直到t−1时刻都领先B,B得最后一票)
用条件概率展开第一项,由于已知每个人的票数,所以最后一票投给A的概率为n/(m+n)。将时间回溯到t-1时刻,相当于A得了n-1票,B还是m票
P
(
A
一
直
到
n
−
1
时
刻
都
领
先
B
∣
A
得
最
后
一
票
)
P
(
A
得
最
后
一
票
)
=
P
(
A
领
先
∣
A
得
n
−
1
票
,
B
得
m
票
)
∗
n
/
(
m
+
n
)
P(A一直到n-1时刻都领先B|A得最后一票)P(A得最后一票)=P(A领先|A得n-1票,B得m票)*n/(m+n)
P(A一直到n−1时刻都领先B∣A得最后一票)P(A得最后一票)=P(A领先∣A得n−1票,B得m票)∗n/(m+n)
这下子,可以把题目里需要求证的带进去了,得到这个概率为:
(
n
−
1
−
m
)
/
(
n
−
1
+
m
)
∗
n
/
(
m
+
n
)
(n-1-m)/(n-1+m)*n/(m+n)
(n−1−m)/(n−1+m)∗n/(m+n)
同理,如果是B得了最后一票,这个概率为
(
n
−
m
+
1
)
/
(
n
+
m
−
1
)
∗
m
/
(
m
+
n
)
(n-m+1)/(n+m-1)*m/(m+n)
(n−m+1)/(n+m−1)∗m/(m+n)
把他们加起来,就可以得到:
P
(
A
一
直
到
t
时
刻
都
领
先
B
∣
A
得
了
n
票
,
B
得
了
m
票
)
=
(
n
+
m
−
1
)
(
n
−
m
)
/
(
m
+
n
)
/
(
m
+
n
−
1
)
=
(
n
−
m
)
/
(
n
+
m
)
P(A一直到t时刻都领先B|A得了n票,B得了m票)=(n+m-1)(n-m)/(m+n)/(m+n-1)=(n-m)/(n+m)
P(A一直到t时刻都领先B∣A得了n票,B得了m票)=(n+m−1)(n−m)/(m+n)/(m+n−1)=(n−m)/(n+m)
而t=1时刻,A领先,只有A得一票这种情况,可以验证
P
(
A
一
直
到
t
=
1
时
刻
都
领
先
B
∣
A
得
了
1
票
,
B
得
了
0
票
)
=
1
/
(
1
+
0
)
=
1
=
(
n
−
m
)
/
(
n
+
m
)
P(A一直到t=1时刻都领先B|A得了1票,B得了0票)=1/(1+0)=1=(n-m)/(n+m)
P(A一直到t=1时刻都领先B∣A得了1票,B得了0票)=1/(1+0)=1=(n−m)/(n+m)
满足等式
也就是说,我们用数学归纳法,把题目证明完了。接下来,我们可以得到质点某一时刻第一次回到原点的概率了。
第一次回到原点,等同于求(第2n张票时,A,B各得了n张票)且(一直到2n-1张票时,A一直领先)的联合概率。后边这个条件,在给定前边的条件时,就等同于(A得了n票,B得了n-1票时,A一直领先)的概率。那么我们可以得到这个概率为:
P
(
Z
2
≠
0
,
Z
4
≠
0
,
.
.
.
Z
2
n
−
2
≠
0
,
Z
2
n
=
0
)
=
(
n
−
(
n
−
1
)
)
/
(
n
+
n
−
1
)
∗
u
n
=
u
n
/
(
2
n
−
1
)
P(Z_2\neq 0, Z_4\neq 0,...Z_{2n-2}\neq 0,Z_{2n}= 0)=(n-(n-1))/(n+n-1)*u_{n}=u_{n}/(2n-1)
P(Z2=0,Z4=0,...Z2n−2=0,Z2n=0)=(n−(n−1))/(n+n−1)∗un=un/(2n−1)
8.2.2 质点某一时刻从未回到原点的概率
有了上面的铺垫,我们可以求取这个概率了。这个概率等同于求
Z
1
≠
0
,
Z
2
≠
0
,
.
.
.
,
Z
2
n
−
2
≠
0
,
Z
2
n
≠
0
Z_1\neq0,Z_2\neq0,...,Z_{2n-2}\neq0,Z_{2n}\neq0
Z1=0,Z2=0,...,Z2n−2=0,Z2n=0的概率。
我们先求在t=2时刻,未回到原点的概率(因为奇数时间肯定不回到原点)。
P
[
Z
1
≠
0
,
Z
2
≠
0
]
=
1
−
P
[
Z
1
≠
0
,
Z
2
=
0
]
P[Z_1\neq0,Z_2\neq0]=1-P[Z_1\neq0,Z_2=0]
P[Z1=0,Z2=0]=1−P[Z1=0,Z2=0]
同理,t=4时刻未回到原点的概率,等同于上面的概率再减去
Z
1
≠
0
,
Z
2
≠
0
,
Z
3
≠
0
,
Z
4
=
0
Z_1\neq0,Z_2\neq0,Z_3\neq0,Z_4=0
Z1=0,Z2=0,Z3=0,Z4=0的概率。实在不理解,可以画个集合的示意图看看。
因此,我们要求取的概率就为:
P
[
Z
1
≠
0
,
Z
2
≠
0
,
.
.
.
,
Z
2
n
−
2
≠
0
,
Z
2
n
≠
0
]
=
1
−
Σ
k
=
1
n
P
[
Z
1
≠
0
,
.
.
,
Z
2
k
−
1
≠
0
,
Z
2
k
=
0
]
=
1
−
Σ
k
=
1
n
u
k
/
(
2
k
−
1
)
=
1
−
Σ
k
=
1
n
−
1
u
k
/
(
2
k
−
1
)
−
u
k
/
(
2
n
−
1
)
=
u
k
−
1
−
u
k
/
(
2
n
−
1
)
=
u
k
\begin{aligned} P[Z_1\neq0,Z_2\neq0,...,Z_{2n-2}\neq0,Z_{2n}\neq0]&=1-\Sigma_{k=1}^nP[Z_1\neq0,..,Z_{2k-1}\neq0,Z_{2k}=0]\\ &=1-\Sigma_{k=1}^nu_k/(2k-1)\\ &=1-\Sigma_{k=1}^{n-1}u_k/(2k-1)-u_k/(2n-1)\\ &=u_{k-1}-u_k/(2n-1)\\ &=u_k \end{aligned}
P[Z1=0,Z2=0,...,Z2n−2=0,Z2n=0]=1−Σk=1nP[Z1=0,..,Z2k−1=0,Z2k=0]=1−Σk=1nuk/(2k−1)=1−Σk=1n−1uk/(2k−1)−uk/(2n−1)=uk−1−uk/(2n−1)=uk
最后一个等于号,可以自己根据
u
k
u_k
uk的定义计算一下,
u
k
=
(
2
k
−
1
)
u
k
−
1
/
2
k
u_k=(2k-1)u_{k-1}/2k
uk=(2k−1)uk−1/2k
8.2.3 质点回到原点之后的行为
只要质点回到原点,后面的过程就和从原点开始的过程的概率分布一模一样了,这是很好理解的。这样,简单随机游走可以看作是更新过程,每次从原点出发再回到原点,就是一次更新过程。
8.2.4 质点到某一时刻之前,处于正半轴和负半轴的时间长度分布
这里先贴一张书上的图,不然感觉不好解释了。首先,随机游走每个时刻距离原点的距离可能会是这样的。如下图,这个质点在8个单位时间内,处于正半轴6个时间单位,处于负半轴两个时间单位。注意,这里说的是整段时间都在正或者负半轴的情况,不是说某个时间点处于正半轴或者负半轴!换句话说,是看线段而不是看点!那么,我们想知道,在某个时间之前,质点处于正半轴和负半轴各多长时间的分布。要注意的是,这里的图虽然是穿过了原点一次,但是实际上,很可能质点从未穿越原点(也就是一直为正或者一直为负),也可能穿越了多次。穿越指的是从正进入负或者反之,单纯到达到零点不算穿越。
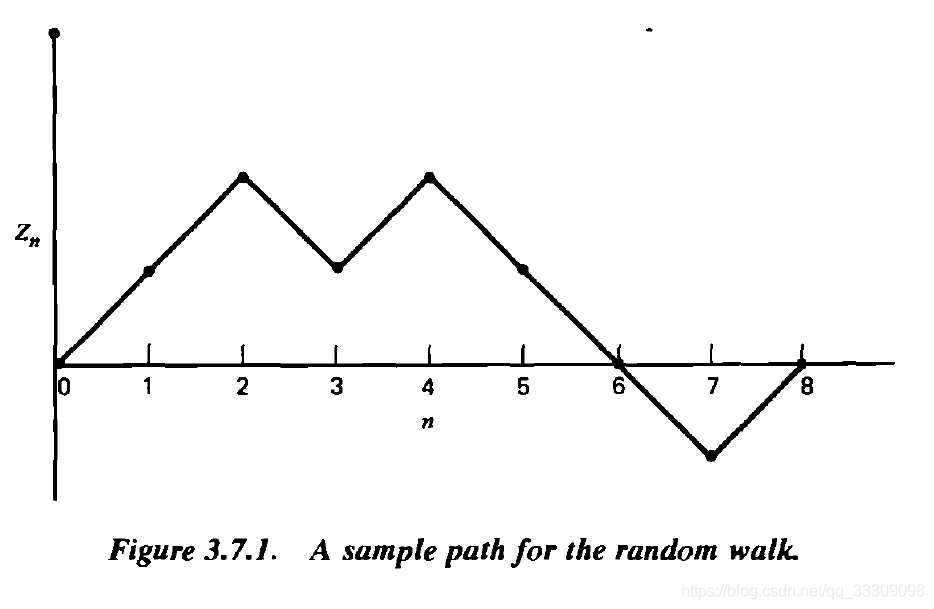
这里用
E
k
,
n
E_{k,n}
Ek,n表示在前2n步中,处于正半轴2k个单位时间长度。那么处于负半轴的时间就是2n-2k。我们再用
b
k
,
n
b_{k,n}
bk,n表示
P
(
E
k
,
n
)
P(E_{k,n})
P(Ek,n)。那么,我们有:
b
k
,
n
=
u
k
u
n
−
k
b_{k,n}=u_ku_{n-k}
bk,n=ukun−k
说实话,接下来又是数学归纳法证明定理了,感觉挺无聊的,还是推导更有意思一点。
所以我索性不证明了!这个定理也叫Arc Sine Laws,是由于时间无穷长的时候,这个概率的分布和arcsin有关系,感兴趣的可以查查,我这里懒得打一堆我自己都不怎么的东西了~
9 一点课后习题
Problem 3.11 一个矿工被困在一个房间里,这个房间有三扇门。第一扇门可以使这个矿工2天后脱离房间;第二扇门可以使他原地消耗4天;第三扇门使他原地消耗8天。假设他每次都等概率地挑选任意一扇门,用 T T T表示矿工脱离房间所消耗的总时间。
a)定义一个独立同分布的随机变量序列 X 1 , X 2 , . . . X_1,X_2,... X1,X2,...和停止时间 N N N,使得 T = Σ 1 N X i T=\Sigma_1^N X_i T=Σ1NXi
b)使用Wald方程计算 E [ T ] E[T] E[T]
c)计算 E [ Σ 1 N X i ∣ N = n ] E[\Sigma_1^N X_i|N=n] E[Σ1NXi∣N=n],注意 E [ Σ 1 N X i ∣ N = n ] ≠ E [ Σ 1 N X i ] E[\Sigma_1^N X_i|N=n]\neq E[\Sigma_1^N X_i] E[Σ1NXi∣N=n]=E[Σ1NXi]
d)用c中的结果,使用于b中不同的方式计算 E [ T ] E[T] E[T]
a)
X
n
=
2
,
4
,
8
X_n=2,4,8
Xn=2,4,8且取三个值的概率都为1/3,停止时为
N
=
m
i
n
{
k
,
X
k
=
2
}
N=min\{k,X_k=2\}
N=min{k,Xk=2}
b)由于N是停止时,所以用Wald方程得到
E
[
T
]
=
E
[
Σ
1
N
X
i
]
=
E
(
N
)
E
(
X
)
E[T]=E[\Sigma_1^N X_i]=E(N)E(X)
E[T]=E[Σ1NXi]=E(N)E(X)
c)如果已知N=n,说明前n-1次都没选中门1,因此前n-1次等概率选中门2、3
E
[
Σ
1
N
X
i
∣
N
=
n
]
=
2
+
(
n
−
1
)
(
4
+
8
)
/
2
=
6
n
−
4
E[\Sigma_1^N X_i|N=n]=2+(n-1)(4+8)/2=6n-4
E[Σ1NXi∣N=n]=2+(n−1)(4+8)/2=6n−4
d)
E
[
Σ
1
N
X
i
]
=
E
[
E
(
Σ
1
N
X
i
∣
N
=
n
)
]
=
E
(
6
n
−
4
)
=
6
E
(
n
)
−
4
=
6
×
3
−
4
=
14
E[\Sigma_1^N X_i]=E[E(\Sigma_1^N X_i|N=n)]=E(6n-4)=6E(n)-4=6\times 3-4=14
E[Σ1NXi]=E[E(Σ1NXi∣N=n)]=E(6n−4)=6E(n)−4=6×3−4=14
假设顾客来到银行的人数服从参数 λ \lambda λ的泊松过程,这家银行只有一个业务员。我们再假设,顾客不愿意排队,如果顾客来的时候发现业务员正忙,他就直接离开。我们还假设每位顾客的服务时间是服从期望为 μ \mu μ的分布G的随机变量。
a)请问相邻两位顾客进入银行的间隔的期望是多少?
b)请问进入银行的顾客人数占来银行顾客的总人数的比例是多少?
a)我们定义如下的更新过程:从上一位顾客开始服务的时候算起,到下一个顾客开始接受服务为一次更新。如果已知顾客的服务时间为
x
x
x,那么我们把停止时定义为:上一次服务结束后来的第一位顾客。这样,在这位顾客的服务时间内,一共来了
N
(
x
)
N(x)
N(x)位顾客,然后又来了一位顾客,终结了这次更新,因此一次更新,一共来了
N
(
x
)
+
1
N(x)+1
N(x)+1位顾客。而在已知停止时的情况下,通过Wald
方程可以很简单地算出这次更新的间隔时期望。再把所有的
x
x
x进行积分,可以得到
∫
0
∞
E
[
S
N
(
x
)
+
1
]
d
G
(
x
)
=
∫
0
∞
E
(
N
(
x
)
+
1
)
E
(
X
)
d
G
(
x
)
=
∫
0
∞
(
λ
x
+
1
)
∗
(
1
/
λ
)
d
G
(
x
)
=
∫
0
∞
(
x
+
1
/
λ
)
d
G
(
x
)
=
E
(
G
)
+
1
/
λ
=
μ
+
1
/
λ
\int_0^\infty E[S_{N(x)+1}]dG(x)=\int_0^\infty E(N(x)+1)E(X)dG(x)=\int_0^\infty (\lambda x+1)*(1/\lambda) dG(x)\\=\int_0^\infty (x+1/\lambda) dG(x)=E(G)+1/\lambda=\mu+1/\lambda
∫0∞E[SN(x)+1]dG(x)=∫0∞E(N(x)+1)E(X)dG(x)=∫0∞(λx+1)∗(1/λ)dG(x)=∫0∞(x+1/λ)dG(x)=E(G)+1/λ=μ+1/λ
b)我们定义如下的交替更新过程:在一次更新中,上一位顾客还在服务中为“开”;上一位顾客走了,下一位顾客还没来的空档期为“关”。我们可以很轻松的算出,顾客来时为“关”的概率为
P
(
t
时
刻
为
关
)
=
E
(
关
的
时
间
)
/
E
(
间
隔
时
)
=
1
/
λ
/
(
μ
+
1
/
λ
)
=
1
/
(
μ
λ
+
1
)
P(t时刻为关)=E(关的时间)/E(间隔时)=1/\lambda/(\mu+1/\lambda)=1/(\mu\lambda+1)
P(t时刻为关)=E(关的时间)/E(间隔时)=1/λ/(μ+1/λ)=1/(μλ+1)
这个概率也就是顾客进银行的比例
10 后记
写了好几天,最终其实还是不太知道更新过程想干啥。尤其不太理解为什么各个定理,尤其是后面的定理,都是
t
→
∞
t\to\infty
t→∞的极限?还好看了看老师布置的作业,还是有思路的。下一章的马尔可夫过程又开始了,加油!
20200429:由于马尔可夫过程中,用到了一些简单随机游走的知识,因此补上这一部分。

















 5201
5201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









