







网上充斥着ONNX Runtime的简单科普,却没有一个系统介绍ONNX Runtime的博客,因此本博客旨在基于官方文档进行翻译与进一步的解释。ONNX runtime的官方文档:https://onnxruntime.ai/docs/
如果尚不熟悉ONNX格式,可以参照该博客专栏,本专栏对onnx 1.16文档进行翻译与进一步解释,
ONNX 1.16学习笔记专栏:https://blog.csdn.net/qq_33345365/category_12581965.html
如果觉得有收获,点赞收藏关注,目前仅在CSDN发布,本博客会分为多个章节,目前尚在连载中。
开始编辑时间:2024/3/11;最后编辑时间:2024/3/11
所有资料均来自书写时的最新官方文档内容。
本专栏链接如下所示,所有相关内容均会在此处收录。
https://blog.csdn.net/qq_33345365/category_12589378.html
介绍
参考:https://onnxruntime.ai/docs/get-started/with-python.html
本教程第一篇:介绍ONNX Runtime(ORT)的基本概念。
本教程第二篇:是一个快速指南,包括安装ONNX Runtime;安装ONNX进行模型输出;Pytorch, TensorFlow和SciKit的快速开始例子
本教程第三篇:CUDA Execution Provider
本教程第四篇:上一篇介绍CUDA EP,本教程介绍EP的相关概念,包括相关的架构。
ONNX Runtime Execution Providers
ONNX Runtime通过其可扩展的Execution Provider(EP)框架与不同的硬件加速库配合工作,以在硬件平台上最优化地执行ONNX模型。这种接口使应用程序开发者能够灵活地在云端和边缘不同环境中部署他们的ONNX模型,并通过利用平台的计算能力来优化执行。

ONNX Runtime使用GetCapability()接口与EP合作,在支持的硬件上为执行环境分配特定节点或子图进行执行。预安装在执行环境中的EP库处理并在硬件上执行ONNX子图。这种架构抽象了硬件特定库的细节,这些库对于优化在CPU、GPU、FPGA或专用NPUs等硬件平台上执行深度神经网络至关重要。
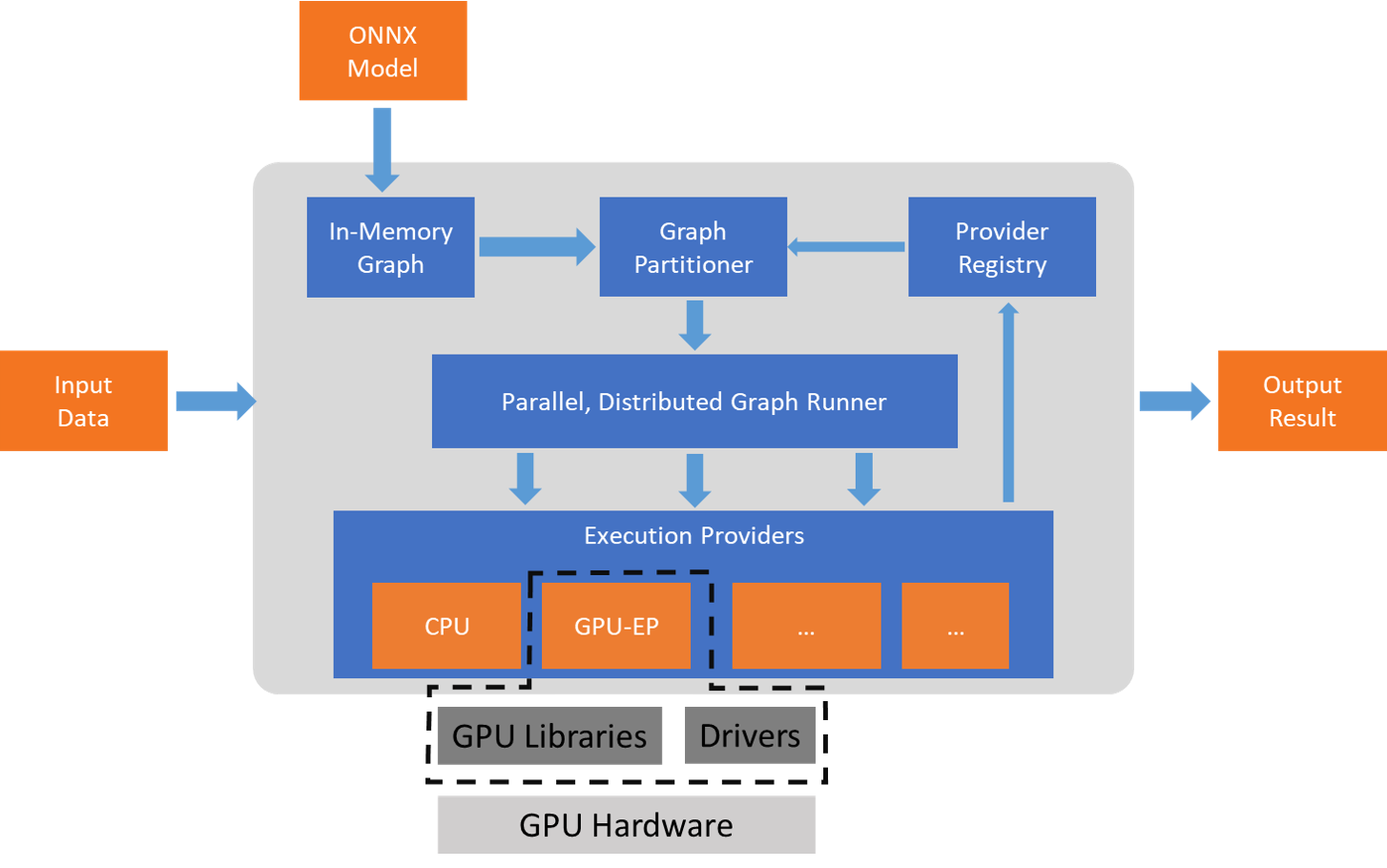
ONNX Runtime目前支持许多不同的EP。其中一些EP目前正在生产中用于实时服务,而其他一些EP则发布为预览版,以便开发人员可以使用不同的选项来开发和定制其应用程序。
目前支持的EP
| CPU | GPU | IoT/Edge/Mobile | Other |
|---|---|---|---|
| Default CPU | NVIDIA CUDA | Intel OpenVINO | Rockchip NPU (preview) |
| Intel DNNL | NVIDIA TensorRT | ARM Compute Library (preview) | Xilinx Vitis-AI (preview) |
| TVM (preview) | DirectML | Android Neural Networks API | Huawei CANN (preview) |
| Intel OpenVINO | AMD MIGraphX | ARM-NN (preview) | AZURE (preview) |
| XNNPACK | Intel OpenVINO | CoreML (preview) | |
| AMD ROCm | TVM (preview) | ||
| TVM (preview) | Qualcomm QNN | ||
| XNNPACK |
添加一个EP
专门的硬件加速解决方案开发人员可以集成到ONNX Runtime中,以在其堆栈上执行ONNX模型。要创建一个与ONNX Runtime接口的EP,您必须首先为EP确定一个唯一的名称。参见:添加新的EP程序以获取详细说明。
使用EP构建ONNX Runtime包
ONNX Runtime软件包可以使用任何组合的EPs与默认的CPU EP构建。请注意,如果将多个EP合并到同一个ONNX Runtime软件包中,则执行环境中必须存在所有依赖库。有关使用不同EPs生成ONNX Runtime软件包的步骤已在here记录。
EP的API
ONNX Runtime API 在所有 EP 上都使用相同的接口。这为应用程序提供了在不同硬件加速平台上运行的一致接口。设置 EP 选项的 API 在 Python、C/C++/C#、Java 和 node.js 中都可用。
注意,我们正在更新我们的 API 支持,以实现所有语言绑定的一致性,并将在此处更新具体内容。
get_providers: 返回已注册的EP程序列表。get_provider_options: 返回已注册EP的配置。set_providers: 注册给定的EP列表。底层会重新创建会话。
providers列表按优先级排序。例如 [‘CUDAExecutionProvider’, ‘CPUExecutionProvider’] 意味着如果有可能,使用 CUDAExecutionProvider 执行节点,否则使用 CPUExecutionProvider 执行。
使用EP
import onnxruntime as rt
# 定义EP的优先级顺序
# CUDA EP优先于CPU EP
EP_list = ['CUDAExecutionProvider', 'CPUExecutionProvider']
# 初始化model.onnx
sess = rt.InferenceSession("model.onnx", providers=EP_list)
# 以以下列表的形式获取输出元数据 :class:`onnxruntime.NodeArg`
output_name = sess.get_outputs()[0].name
# 以以下列表的形式获取输入元数据 :class:`onnxruntime.NodeArg`
input_name = sess.get_inputs()[0].name
# 使用image_data作为模型的输入运行推理
detections = sess.run([output_name], {input_name: image_data})[0]
print("Output shape:", detections.shape)
# 处理图像以标记推理点
image = post.image_postprocess(original_image, input_size, detections)
image = Image.fromarray(image)
image.save("kite-with-objects.jpg")
# 更新EP优先级仅为CPUExecutionProvider
sess.set_providers(['CPUExecutionProvider'])
cpu_detection = sess.run(...)
总结
通过上面的介绍,可以得知模型可以运行在多个设备上,因此下一个教程,我们介绍加速pytorch代码相关的内容


















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











