







 本文介绍了一种结合自注意力机制(Self-Attention)与卷积LSTM(ConvLSTM)的模型SA-ConvLSTM,用于改善时空预测中的长期空间依赖建模。研究指出,传统的卷积方法仅能捕获局部空间依赖,而通过堆叠卷积层的方式效率不高。作者提出Self-Attention Memory (SAM) 模块,用以增强模型的全局时空特征表示能力。实验结果显示,SA-ConvLSTM在多个数据集上的表现优于现有方法,尤其是在多帧预测和交通流量预测任务中。尽管注意力计算的高复杂度可能限制其在大规模数据上的应用,但该工作仍为时空预测提供了一种有效的新途径。
本文介绍了一种结合自注意力机制(Self-Attention)与卷积LSTM(ConvLSTM)的模型SA-ConvLSTM,用于改善时空预测中的长期空间依赖建模。研究指出,传统的卷积方法仅能捕获局部空间依赖,而通过堆叠卷积层的方式效率不高。作者提出Self-Attention Memory (SAM) 模块,用以增强模型的全局时空特征表示能力。实验结果显示,SA-ConvLSTM在多个数据集上的表现优于现有方法,尤其是在多帧预测和交通流量预测任务中。尽管注意力计算的高复杂度可能限制其在大规模数据上的应用,但该工作仍为时空预测提供了一种有效的新途径。
作者 | Subranium
学校 | 东北大学
研究 | 城市计算
出品 | AI蜗牛车
一、 Address
来自于清华大学的一篇文章,收录于AAAI 2020的论文:Self-Attention ConvLSTM for Spatiotemporal Prediction。
论文地址:https://aaai.org/ojs/index.php/AAAI/article/view/6819
二、 Introduction
对于时空预测来说如何对复杂的动态时空依赖关系建模是一项很具有挑战性的工作,而且现有的一些方法通过卷积的方式只能捕获局部的空间依赖关系,要想捕获长期的空间依赖关系一般是通过堆叠卷积层的方式,这样的方法效果并不好。所以如何才能更好的对长期的空间依赖进行建模是本篇论文要解决的主要问题。
2.1 Related Work
自从ConvLSTM提出以后产生了许多变种,例如PredRNN,PredRNN++和MIM。其中Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spatiotemporal Dynamics(MIM)是之前的SOTA。下图是MIM的模型结构。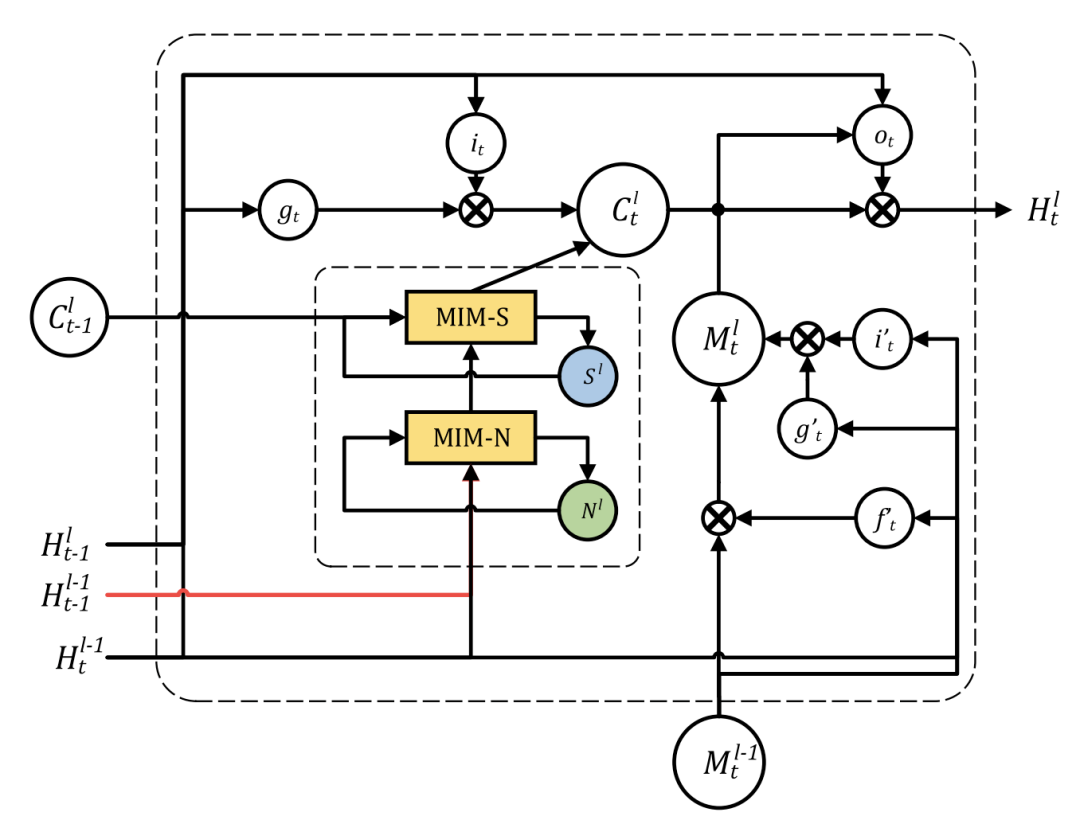
2.2 self-attention
注意力机制自从被提出就受到了很好的反响,而且近些年自注意力机制因其良好的效果也被广泛应用。本篇论文就是在自注意力机制的基础上提出了self-attention memory (SAM)用于解决上面提出的长期空间依赖问题。
基础的self-attention模块结构如下: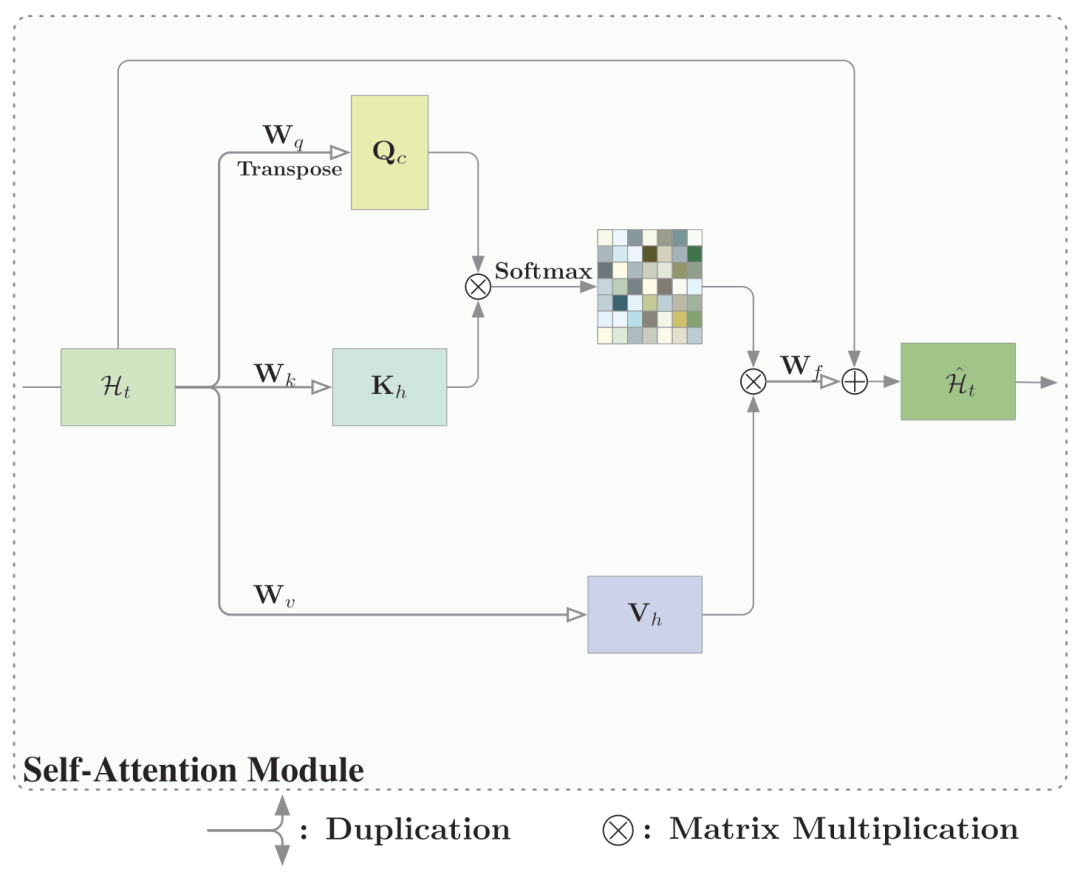 通过定义三个的卷积核的方式,将输入的原始特征图映射到不同的特征空间。
通过定义三个的卷积核的方式,将输入的原始特征图映射到不同的特征空间。
之后可以通过下面的公式来计算不同位置的相似性分数。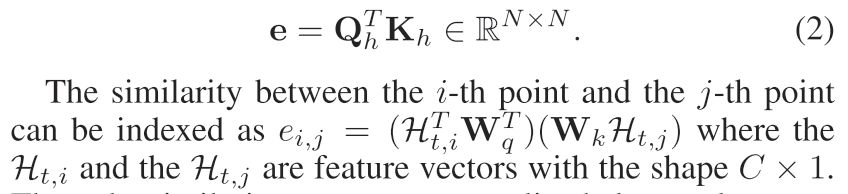
三、Model
本篇论文通过将提出的SAM模块嵌入到ConvLSTM中构建为SA-ConvLSTM,模型的整体架构如下图所示。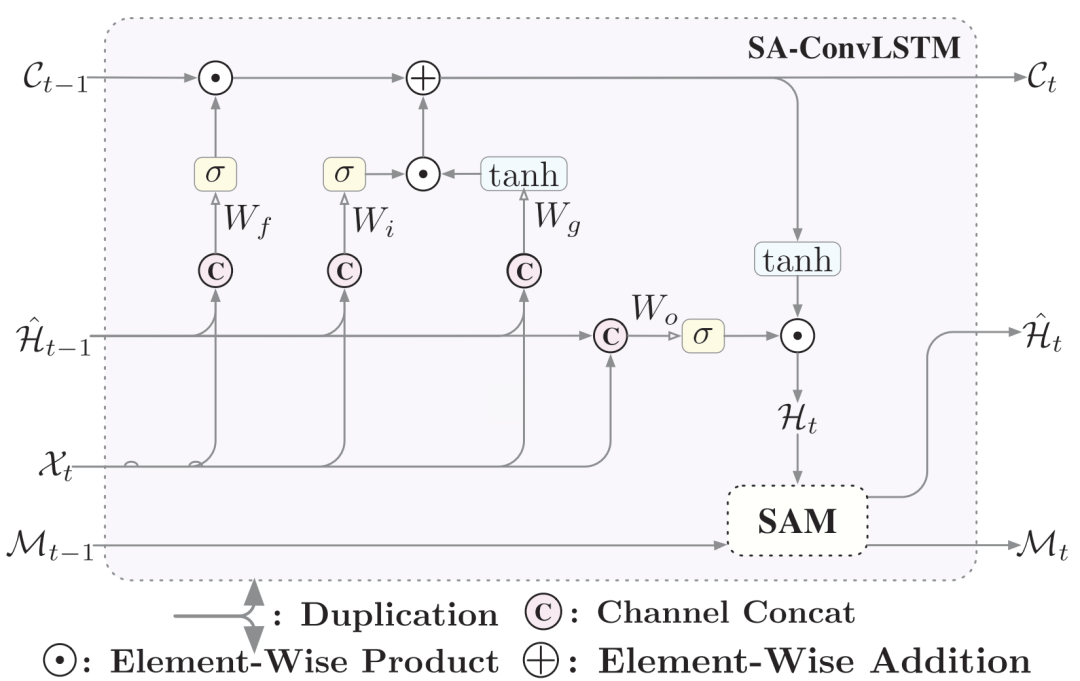
3.1 基础模型
基础模型是将self-attention和ConvLSTM做简单的拼接,其中SA代表self-attention model用公式表示如下: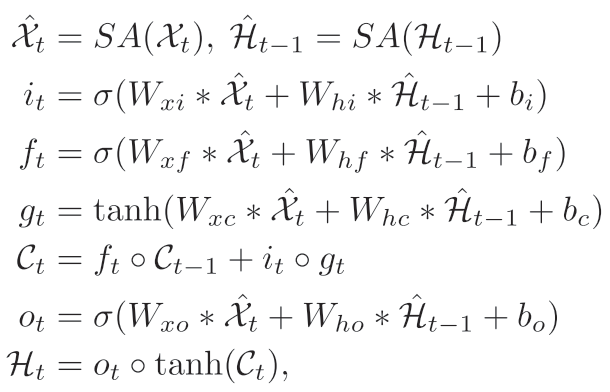 下图是ConvLSTM中的公式,大家可以对照的来看一下这两个组公式
下图是ConvLSTM中的公式,大家可以对照的来看一下这两个组公式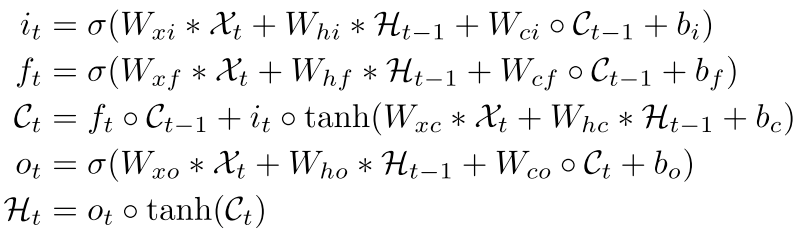
3.2 Self-Attention Memory Module
作者认为利用过去的相关特征来预测当前时间步是很有帮助的,所以作者设计了一种新的记忆单元用于表示全局的时空特征。设计的结构如下图所示: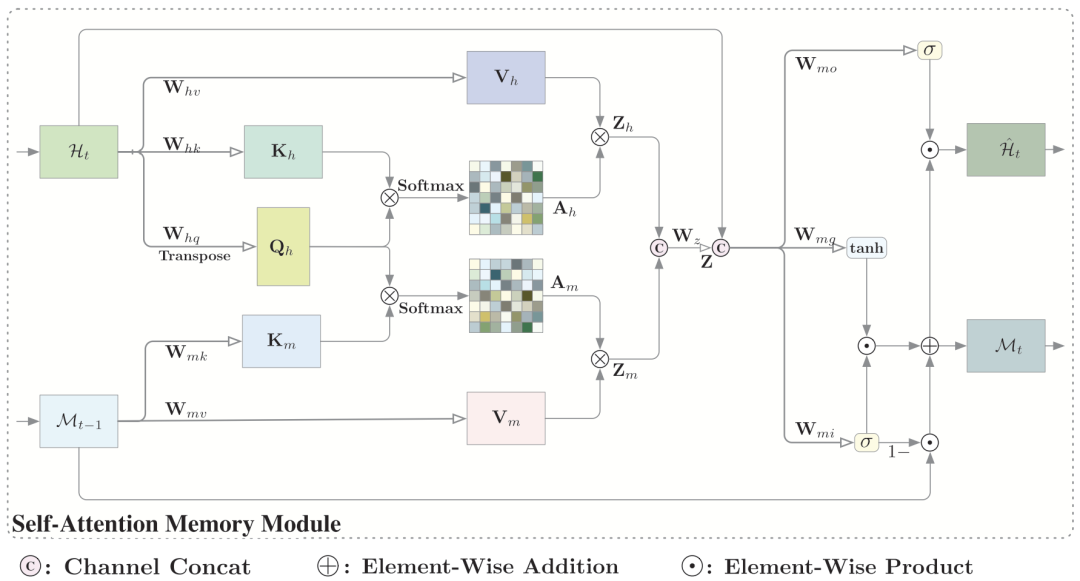 从图中可以看到self-attention memory接收两个输入分别是当前时间步的特征和上一步的记忆。模块的整个架构可以分为以下三个部分:1.feature aggregation 2.memory updating 3.output
从图中可以看到self-attention memory接收两个输入分别是当前时间步的特征和上一步的记忆。模块的整个架构可以分为以下三个部分:1.feature aggregation 2.memory updating 3.output
3.2.1 Feature Aggregation
在每一个时间步的聚合特征是由和融合而成。其中就是之前提到的self-attention的输出,是当前时间步的特征与记忆单元的特征计算相似性得到的。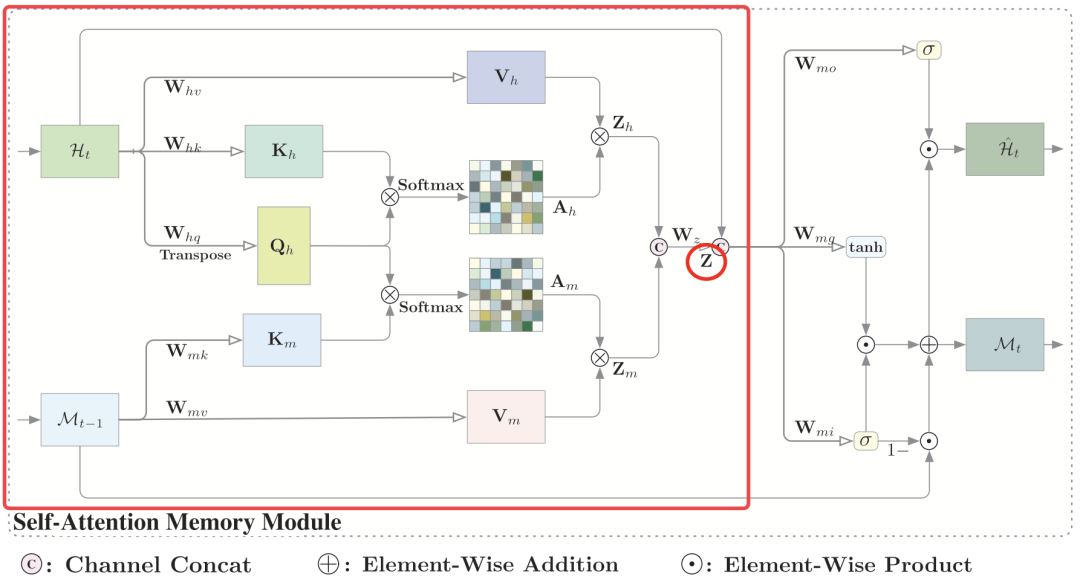 具体的操作步骤与self-attention类似,最终通过将和的通道拼接得到最后的聚合特征。
具体的操作步骤与self-attention类似,最终通过将和的通道拼接得到最后的聚合特征。
3.2.2 Memory Updating
作者采用门控机制来动态的更新记忆单元,聚合特征和原始输入用于生成输入门和聚合特征。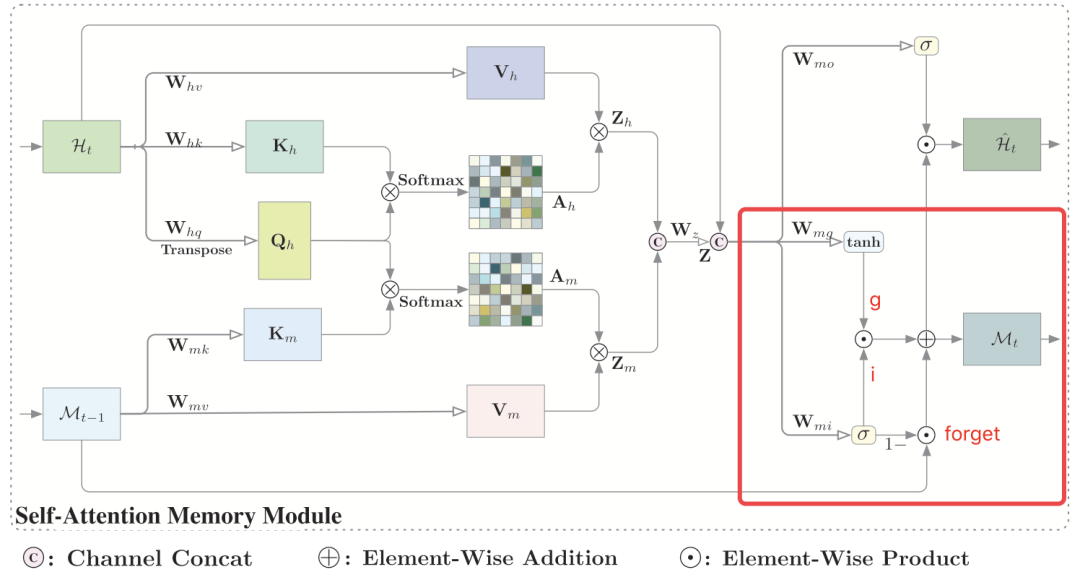 计算公式如下
计算公式如下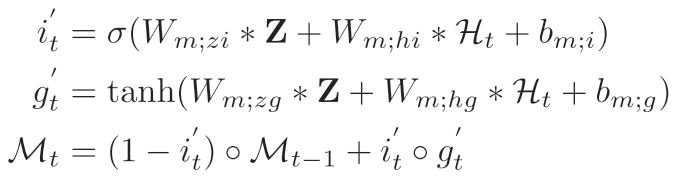 为了进一步减少参数和计算量作者使用深度可分离卷积来代替标准的卷积操作。
为了进一步减少参数和计算量作者使用深度可分离卷积来代替标准的卷积操作。
3.3.3 Output
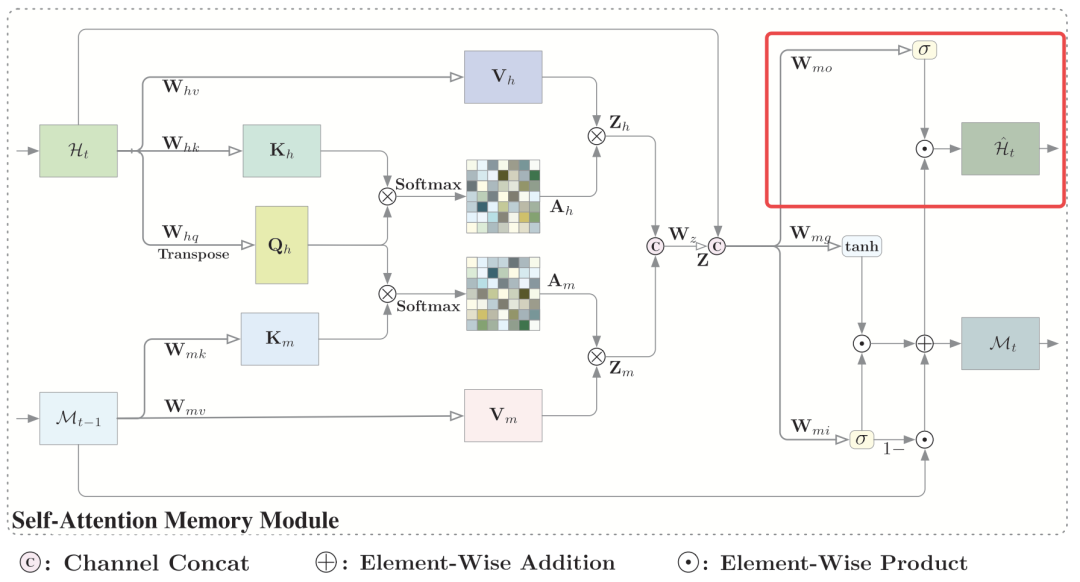 输出模块将聚合特征,原始输入以及记忆整合称最后的输出,公式如下:
输出模块将聚合特征,原始输入以及记忆整合称最后的输出,公式如下:
四、 Experiments
作者将提出的模型应用到了三个数据集,分别是:MovingMNIST和KTH用于多帧预测,TexiBJ用于交通流量预测。作者为了验证设计模型的有效性作者做了许多消融实验。 通过逐渐增加模型的结构可以看到模型最终的效果如下图所示。
通过逐渐增加模型的结构可以看到模型最终的效果如下图所示。 而且通过对比实验可以发现,本篇论文提出的模型取得了比较好的效果,下图是模型在MovingMNIST上的结果。
而且通过对比实验可以发现,本篇论文提出的模型取得了比较好的效果,下图是模型在MovingMNIST上的结果。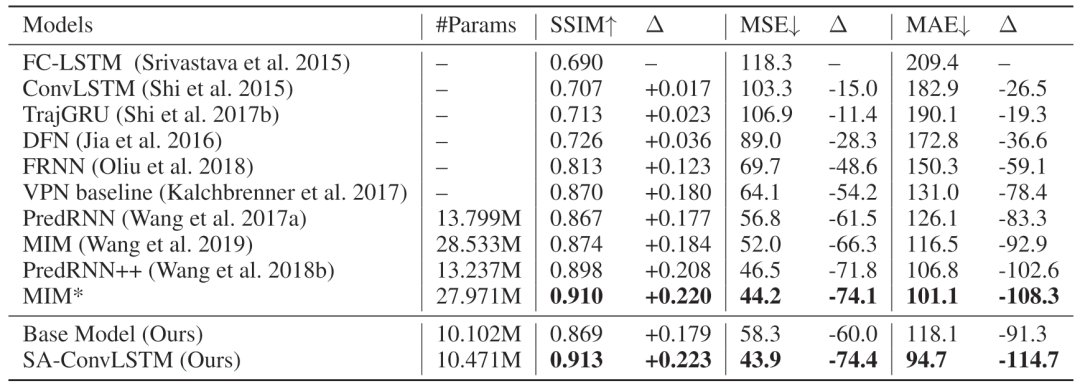
五、 Conclusion
本片论文提出用self-attention的方法来捕获长期的空间依赖性,虽然取得了很好的效果,但是论文中也提到对于注意力的计算复杂度是很高的,所以本篇论文中实验采用的图像的尺寸比较小,可以忽略注意力的计算,对于大范围的数据来说这点可能也会成为一个限制因素。
更多精彩内容(请点击图片进行阅读)



公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

个人微信
备注:昵称+学校/公司+方向
如果没有备注不拉群!
拉你进AI蜗牛车交流群



















 5308
5308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









