









CornerNet
CornerNet是比较具有开创性的目标检测方法.他是通过两个对角点的坐标和两个对角点所属的类别来进行目标检测的。
传统的anchor-based方法在一些问题:
- 如果使用场景和训练集差距大那么效果是将很不理想
- 存在正负样本严重不平衡问题,而这种正负样本不均衡问题至今并没有得到了一个很好的解决
- 网络收敛慢,尤其是数据集质量不佳的情况下
所以作者抛弃了anchor的做法,以下为大致流程:

网络架构

主干网络用的是Hourglass,FPN输出为两个部分,一个负责左上角点的预测,一个负责右下角点的预测。
Heatmaps: heatmaps一共n_cls(类别数)个通道,值是0或者1,表示是否为该类,这一点和mask-cnn一样,既将一个任务分解为多个任务又减弱了多标签的竞争关系
Embeddings: Embeddings表示每个点的一维特征向量,作者通过Embeddings将heatmaps输出的点划分为哪一个类。如果一个左上角点和一个右下角点来自同一个bounding box,那它们 embedding vector之间的距离应该很小
Offsets:由于网络经过了几次下采样,通过heatmaps重映射回原图时,会损失一些位置精度(尤其是对于小目标检测)
所以添加一个offset来微调角点的位置。
Corner Pooling
backbone中作者使用了一个特殊的pooling方式,下图为左上角corner pooling方法:

步骤就是先按从右往左每个像素改为以这个像素往右所有像素的极大值,逐行这样去做,然后按从下往上每个像素改为以这个像素往下所有像素的极大值,每一行都这样。最后,将两个特征图相加。这么做更有利于提取角点的特征。原理就是将比较重要的特征在空间上按一定的方向做延申,从而让特征的形状更接近于边界框的形状。预测左上角的用左上corner pooling否则用右下corner pooling.
角点检测
对每个gt正样本位置,作者会画一个圈, 圈的半径要满足在这个圈中采样的点组成的框要和边界框的iou至少为t(t默认为0.3)。对圈内的负样本给予'奖励', 这个奖励服从中心点为正样本位置方差为1/9的二维高斯分布
角点分类
对于一场图检测出的多个角点,我们需要找到哪些左上角点和右下角点是属于同一个边界框的。通过预测对角点的特征向量的距离来区分哪两个角点属于同一个框。
损失设计
heatmap损失:
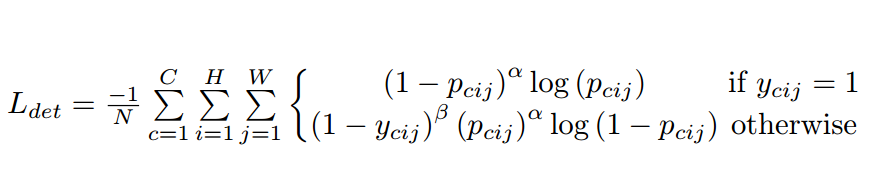
采用了BCELoss, 并加入了重新设计的focalloss,如果圈中里角点越远的点他的损失削弱的越小,越近损失削弱越厉害。
N为一张照片上的目标个数,alpha默认为2,beta默认为4
offset损失:
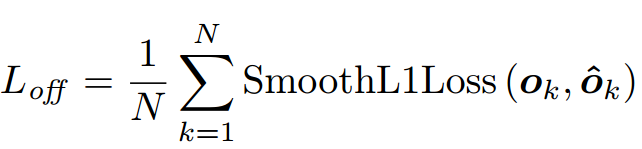
使用了soomthL1损失, 偏移量计算公式为: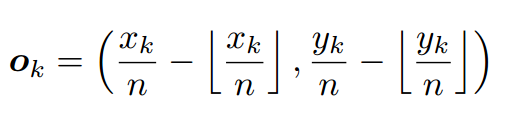
embedding损失:

embedding损失分为pull部分和push部分,etk和ebk分别是目标K的左上角和右下角的embedding输出,ek为其平均值,该损失是为了让一个目标的两个角点的特征向量更加相近。push损失中如果两个角点相差过于大损失就为0,这一点类似于偏移量损失,只计算相差不远的特征向量的损失,delta默认为1
缺点
未完待续。。。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









