







 本文介绍了优化算法的基础,包括目标函数、求解方法和评价标准。重点讲解了随机梯度下降(SGD)、SAG、SVRG算法以及在线梯度下降(OGD)的背景和发展,特别是OGD在稀疏性主线上的进展,如简单截断法、TG、FOBOS和RDA。这些算法在大数据和增量学习中的应用和收敛性是讨论的重点。
本文介绍了优化算法的基础,包括目标函数、求解方法和评价标准。重点讲解了随机梯度下降(SGD)、SAG、SVRG算法以及在线梯度下降(OGD)的背景和发展,特别是OGD在稀疏性主线上的进展,如简单截断法、TG、FOBOS和RDA。这些算法在大数据和增量学习中的应用和收敛性是讨论的重点。
1. 优化知识预备
1.1目标函数
首先我们的目标是最小化一个损失函数:
L ( W , Z ) L(W,Z) L(W,Z)
其中 W = ( w 1 , w 2 , . . . , w k ) W=(w_1,w_2,...,w_k) W=(w1,w2,...,wk)是参数, Z = { ( X i , y i , y ^ i ∣ i = 1 , 2 , . . . , n ) } Z=\{(X_i,y_i,\hat y_i|i=1,2,...,n)\} Z={
(Xi,yi,y^i∣i=1,2,...,n)}, y ^ i = f ( W , X i ) \hat y_i=f(W,X_i) y^i=f(W,Xi)是预测的结果。损失函数通常可以写成各个样本损失函数的累加,即 L ( W , Z ) = ∑ i = 1 n L ( W , Z i ) L(W,Z)=\sum_{i=1}^nL(W,Z_i) L(W,Z)=∑i=1nL(W,Zi),在我们们确定函数 f f f的形式下 W W W 就是我们求解的目标,而求解的方式就是寻找能使损失函数最小的 W W W。
W = arg min W L ( W , Z ) W=\argmin_WL(W,Z) W=WargminL(W,Z)
1.2求解方法
对于这样的问题,在问题形式较为简单,我们可以得到问题的解析解,而得到解析解的方法例如拉格朗日乘数法,KKT条件等,但更多的我们还是需要使用数值计算的方式去求解,而梯度下降就是一类经典的数值求解方法,GD算法如下:
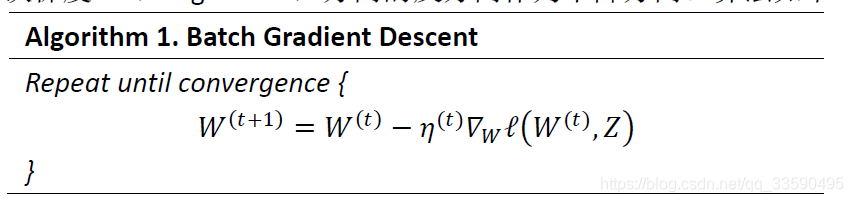
其中Z是全体的数据,而在数据量大的情况下出现了SGD:

每次迭代仅仅根据单个样本更新权重?,这种算法称作随机梯度下降法。
1.3算法的评价
什么样的算法是一个好的算法?
对于一个数值求解算法,我们总是希望在能接受的时间内得到一个满足要求的解,在当今大数据的时代背景下,我们还应考虑算法对机器的考验。
综上适用条件,收敛性和收敛速度和可实现性,我认为从这三个方面对一个算法进行评价是比较完整的。
1.3.1 适用条件
算法能够使用的场合往往是有要求的,比如可微,比如强凸等等,使用算法之前要注意使用的环境的配套。
1.3.2 收敛性和收敛速度
为什么要和算法适用的环境配套就是因为在一些极端情况下算法可能求不到最优值(比如陷入局部最优),这个问题可以通过将目标函数改为强凸函数,或者多设几个初始点去解决。除此以外还有一个问题就是算法的收敛性和收敛速度的问题。
收敛性:
算法产生的迭代点列 { x i } \{x_i\} {
xi}在某种范数的意义下满足:
lim n → ∞ ∥ x n − x ∗ ∥ = 0 \lim_{n\rightarrow\infty}\|x_n-x^*\|=0 n→∞lim∥xn−x∗∥=0
才称算法是收敛的,如果从任意初始点出发都可以收敛到 x ∗ x^* x∗称为是全局收敛,如果仅初始点与 x ∗ x^* x∗足够近的时候才能收敛到 x ∗ x^* x∗称为是局部收敛的。
收敛速度:
在已知收敛的情况下,收敛速度是:
lim n → ∞ ∥ x n + 1 − x ∗ ∥ ∥ x n − x ∗ ∥ k = α \lim_{n\rightarrow\infty}\frac{\|x_{n+1}-x^*\|}{\|x_{n}-x^*\|^k}=\alpha n→∞lim∥xn−x∗∥k∥xn+1−x∗∥=α
如果 α ≥ 1 , k = 1 \alpha\geq1,k=1 α≥1,k=1称为次线性收敛
如果 0 < α < 1 , k = 1 0<\alpha<1,k=1 0<α<1,k=1称为线性收敛
如果 α = 0 , k = 1 \alpha=0,k=1 α=0,k=1称为超线性收敛
如果 0 < α < 1 , k = 2 0<\alpha<1,k=2 0<α<1,k=2称为二阶收敛
2. SGD、SAG、SVRG
SGD类算法的一个问题就是收敛速度不够快,SAG和SVRG是12年13年提出的,作为SGD类算法在收敛速度上的重大突破,下面来介绍这两个算法:
2.1 SAG
在步长为 α k \alpha_k αk的情况下最小化 1 n ∑ i = 1 n f i ( x ) \frac{1}{n}\sum_{i=1}^nf_i(x) n1∑i=1nfi(x)
- d = 0 , y i = 0 d=0,y_i=0 d=0,yi=0,对所有的n ∈ { 1 , 2 , . . . , n } \in\{1,2,...,n\} ∈{
1,2,...,n}
- for k=0,1,…do
- 从 { 1 , 2 , . . . , n } \{1,2,...,n\} { 1,2,...,n}中随机抽取一个 i i i出来
- d = d − y i + f i ′ ( x ) d=d-y_i+f'_i(x) d=d−yi+fi′(x)
- y i = f i ′ ( x ) y_i=f'_i(x) yi=fi′(x)
- x = x − α n d x=x-\frac{\alpha}{n}d x=x−nαd
- end for convergence
- for k=0,1,…do
2.2 SVRG
最小化 1 n ∑ i = 1 n ψ i ( x ) \frac{1}{n}\sum_{i=1}^n\psi_i(x) n1∑i=1nψi(x),更新率 m m m和学习率 η \eta η
- 给定迭代初始值 w ^ 0 \hat w_0 w^0
- 开始迭代:
- for s=0,1,…do
- w ~ = w ^ s − 1 \tilde w=\hat w_{s-1} w~=w^s−1
- μ ~ = 1 n ∑ i = 1 n ∇ ψ i ( w ~ ) \tilde\mu=\frac{1}{n}\sum_{i=1}^n\nabla\psi_i(\tilde w) μ~=n1∑i=1n∇ψi(w~)
- w 0 = w ~ w_0=\tilde w w0=w~
- 迭代:
- for t = 1,2,…,m
- 随机从 { 1 , 2 , . . . , n } \{1,2,...,n\} { 1,2,...,n}中选一个 i t i_t it然后更新权重
- w t = w t − 1 − η ( ∇ ψ i t ( w t − 1 ) − ∇ ψ i t ( w ~ ) + μ ~ ) w_t=w_{t-1}-\eta(\nabla\psi_{i_t}(w_{t-1})-\nabla\psi_{i_t} (\tilde w)+\tilde \mu) wt=wt−1−η(∇ψit(wt−1)−∇ψit(w~)+μ~)
- end
- 选项1:令 w ~ s = w m \tilde w_s=w_m w~s=wm
- 选项2:令 w ~ s = w t \tilde w_s=w_t w~s=wt, t t t是从 { 1 , . . . , m − 1 } \{1,...,m-1\} { 1,...,m−1}中随机选出的。
- for s=0,1,…do
- end for convergence
3. OGD
3.1问题背景
优化问题大数据量并且存在增量学习
3.2 OGD沿着稀疏性主线的发展
3.2.2 简单截断法
3.2.3 TG
3.2.4 FOBOS
3.2.5 RDA
给定一个初始的参数 W 0 W^0 W0,下面开始迭代, W ( t ) W^{(t)} W(t)的更新方式是:
W ( t + 1 ) = arg min W { 1 t ∑ r = 1 t ⟨ G ( r ) , W ⟩ + Ψ ( W ) + β ( t ) t h ( W ) } W^{(t+1)}=\argmin_W\{\frac{1}{t}\sum_{r=1}^t\langle G^{(r)},W\rangle+\Psi(W)+\frac{\beta^{(t)}}{t}h(W)\} W(t+1)=Wargmin{
t1r=1∑t⟨G(r),W⟩+Ψ(W)+tβ(t)h(W)}
其中 G ( r ) G^{(r)} G(r)是第 r r r次迭代中损失函数的梯度(取法是SGD的取法,不是全局的梯度), ⟨ G ( r ) , W ⟩ \langle G^{(r)},W\rangle ⟨G(r),W⟩表示 G ( r ) G^{(r)} G(r)的一个线性函数(对 W W W求一个均值), Ψ ( W ) \Psi(W) Ψ(W)是一个正则项, h ( W ) h(W) h(W)是一个强凸函数(保证迭代的全局最优解唯一), β ( t ) \beta^{(t)} β(t)是一个非负不减的序列决定了收敛速率。
3.2.5.1 L1-RDA
取 Ψ ( x ) \Psi(x) Ψ(x)是L1范数 Ψ ( x ) = λ ∥ W ∥ 1 \Psi(x)=\lambda\|W\|_1 Ψ(x)=λ∥W∥1,在此情况下我们来看看RDA方法的具体步骤:
不妨取 h ( W ) = 1 2 ∥ W ∥ 2 2 h(W)=\frac{1}{2}\|W\|^2_2 h(W)=21∥W∥22, β ( t ) = γ t \beta^{(t)}=\gamma\sqrt{t} β(t)=γt,现在对每个标量进行研究,问题转化为:
arg min W { 1 t ∑ i = 1 t g i ( t ) w i + λ ∣ w i ∣ + γ 2 t ∥ w i ∥ 2 2 } \argmin_W\{\frac{1}{t}\sum_{i=1}^tg_i^{(t)}w_i+\lambda|w_i|+\fra
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









