






摘要:大型基础模型在视觉和语言领域的复杂问题上展现出强大的开放世界泛化能力,但在机器人领域,类似水平的泛化能力尚未实现。一个根本挑战在于缺乏机器人数据,这些数据通常需要通过昂贵的机器人实际操作来获取。一种有前景的解决方法是利用更廉价的 “域外” 数据,如无动作视频、手绘草图或模拟数据。在这项工作中,我们提出,分层视觉 - 语言 - 动作(VLA)模型在利用域外数据方面,比直接对视觉 - 语言模型(VLMs)进行微调以预测动作的标准整体式 VLA 模型更有效。具体而言,我们研究了一类分层 VLA 模型,其中高层 VLM 经过微调,能够根据 RGB 图像和任务描述生成表示期望机器人末端执行器轨迹的粗略 2D 路径。这个中间 2D 路径预测结果随后作为指导,提供给能够进行精确操作的底层 3D 感知控制策略。这样做减轻了高层 VLM 进行细粒度动作预测的负担,同时降低了底层策略在复杂任务级推理上的压力。我们发现,通过这种分层设计,高层 VLM 能够跨越域外微调数据与真实机器人测试场景之间的显著领域差距,包括在实体、动力学、视觉外观和任务语义等方面的差异。在真实机器人实验中,我们观察到,与 OpenVLA 相比,HAMSTER 在七个不同的泛化维度上平均成功率提高了 20%,相对增益达到 50%。视觉结果可在以下网址查看:https://hamster-robot.github.io/
1. 引言
开发通用的机器人操作策略一直极具挑战性。随着大型视觉 - 语言模型(VLMs)的出现,其展现出令人瞩目的泛化能力,人们期望同样的方法能直接应用于机器人操作。此前有一系列工作(Brohan 等人,《Rt-2: Vision-language-action models transfer web knowledge to robotic control》;Kim 等人,《Openvla: An open-source vision-language-action model》;Black 等人,《pi 0: A vision-language-action flow model for general robot control》)通过对现成的预训练 VLMs 进行微调,构建开放世界视觉 - 语言 - 动作模型(VLAs),使其直接生成机器人动作。在本工作中,我们将这些 VLA 模型称为整体式 VLA 模型 monolithic VLA models,它们严重依赖大型机器人数据集,这些数据集包含机器人的观测数据,如图像和本体感受状态,以及动作。然而,机器人数据获取成本高昂,因为端到端的观测 - 动作对通常需要通过如远程操作等方式在机器人硬件上收集。尽管最近学术界在构建大规模机器人数据集方面做出了努力(Collaboration 等人,《Open X-Embodiment: Robotic learning datasets and RT-X models》;Khazatsky 等人,《Droid: A large-scale in-the-wild robot manipulation dataset》),但现有机器人数据集在规模、质量和多样性方面仍然有限,整体式 VLA 模型尚未展现出与其他研究领域中的 VLMs 和大语言模型(LLMs)相媲美的涌现能力。此外,整体式 VLA 模型的推理频率限制了它们在实现灵巧和动态操作任务方面的能力(Brohan 等人,《Rt-2: Vision-language-action models transfer web knowledge to robotic control》;Kim 等人,《Openvla: An open-source vision-language-action model》)。
另一方面,相对小型的机器人策略模型展现出了令人印象深刻的灵巧性和鲁棒性。这些模型在一系列涉及丰富接触操作和 3D 推理的复杂任务中表现出潜力,涵盖从桌面操作(Shridhar 等人,《Perceiver-actor: A multi-task transformer for robotic manipulation》;Goyal 等人,《Rvt: Robotic view transformer for 3d object manipulation》;《Rvt2: Learning precise manipulation from few demonstrations》;Ke 等人,《3d diffuser actor: Policy diffusion with 3d scene representations》)到精细灵巧操作(Chi 等人,《Diffusion policy: Visuomotor policy learning via action diffusion》;Zhao 等人,《Learning fine-grained bimanual manipulation with low-cost hardware》)等领域。这些模型在相对较小的数据集上进行训练,表现出局部鲁棒性,能够实现灵巧和高精度的控制。然而,它们在面对环境或任务语义描述的剧烈变化时往往较为脆弱(Pumacay 等人,《The colosseum: A benchmark for evaluating generalization for robotic manipulation》)。由于模拟环境与现实在视觉外观和系统动力学方面存在差异,这些模型在将模拟数据有效应用于现实世界操作任务时也面临困难(Li 等人,《Evaluating real-world robot manipulation policies in simulation》;Mandlekar 等人,《What matters in learning from offline human demonstrations for robot manipulation》)。
在本研究中,我们思考:如何将大型 VLMs 的泛化优势与小型策略模型的效率、局部鲁棒性和灵巧性相结合呢?我们的关键见解是,VLMs 不应直接预测机器人动作,而是可以通过微调生成中间表示,以此作为解决机器人操作任务的高级指导。然后,中间表示可被底层策略模型用于生成动作,从而减轻底层策略在长期规划和复杂语义推理方面的负担。此外,如果选择的中间表示具备以下特性:
1)易于从图像序列中获取;
2)在很大程度上与具体实体无关;
3)对动力学的细微变化具有足够的鲁棒性,那么 VLM 就可以在机器人动作不可用或不准确的域外数据上进行微调。
这种域外数据无需在实际机器人硬件上收集,例如无动作视频数据、模拟数据、人类视频以及不同实体机器人的视频等。这些域外数据通常更容易收集,并且在现有数据集中可能已经大量存在。我们假设并通过实验(见图 8)证明,这种分层结构能够使 VLA 模型更有效地弥合域外数据与域内机器人操作之间的领域差距。
为此,我们提出了一种用于视觉 - 语言 - 动作(VLA)模型的分层架构 ——HAMSTER(具有分离路径表示的分层动作模型)。在该架构中,经过大量微调的视觉语言模型(VLMs)通过 2D 路径表示与底层策略模型相连 。2D 路径是机器人末端执行器在 2D 图像平面上的粗略轨迹,同时也包含抓手状态变化(即打开和关闭)的位置信息(见图 2)。
图 2:HAMSTER 的执行过程示意图。高层 VLM 被调用一次以生成 2D 路径。底层策略以 2D 路径为条件,与环境进行顺序交互以执行底层动作。VLM 预测的路径增强了底层策略的泛化能力
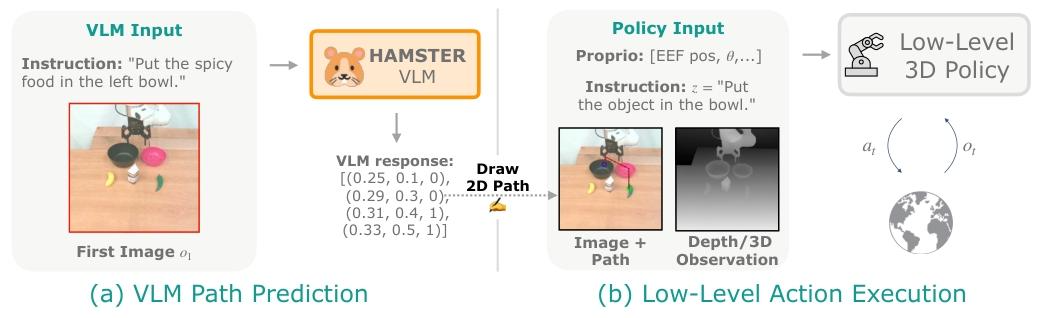
这些 2D 路径可以通过点跟踪(Doersch 等人,2023;Karaev 等人,2025)、手绘(Gu 等人,2023)或本体感受投影等方法,从无动作视频或物理模拟等数据源中低成本且自动地获取。这使得 HAMSTER 在微调高层 VLM 时,能够有效利用这些丰富且廉价的域外数据。HAMSTER 的分层设计还通过解耦 VLM 训练和底层动作预测带来了额外优势。具体而言,高层 VLM 从单目 RGB 相机输入中预测具有语义意义的轨迹,而底层策略模型则可以利用丰富的 3D 和本体感受输入进行操作。通过这种方式,HAMSTER 既继承了 VLM 的语义推理优势,又具备 3D推理和空间感知优势(Goyal 等人,2024;Ke 等人,2024)。此外,高层 VLM 和底层策略模型可以以不同的频率进行查询。
总之,我们研究了一系列分层 VLA 模型 HAMSTER,其中经过微调的 VLMs 与底层 3D 策略模型(Goyal 等人,2024;Ke 等人,2024)相连。高层 VLM 生成的 2D 路径为基于丰富 3D 和本体感受输入进行操作的底层策略提供指导,使底层策略能够专注于稳健地生成精确、具有空间感知的动作。在我们的实验中,与 OpenVLA(Kim 等人,2024)相比,HAMSTER 在七个不同的泛化维度上平均成功率提高了 20%,这相当于相对增益 50%,如表 6 所示。由于 HAMSTER 是基于开源 VLMs 和底层策略构建的,它可以为社区构建视觉 - 语言 - 动作模型提供一个完全开源的工具。需要注意的是,虽然我们肯定不是第一个提出分层 VLA 模型的(Gu 等人,2023;Nasiriany 等人,2024a),但我们提出了一种新颖的观点,即这种分层分解使这些模型能够利用丰富的域外数据来改进现实世界的控制。这为使用更廉价和更丰富的数据源训练大型视觉 - 语言 - 动作模型开辟了新途径。
2. 相关工作
2.1 用于机器人的大语言模型(LLMs)和视觉语言模型(VLMs)
早期在机器人领域利用大语言模型(LLMs)和视觉语言模型(VLMs)的尝试是通过预训练的语言(Jang 等人,《Bc-z: Zero-shot task generalization with robotic imitation learning》;Shridhar 等人,《Perceiver-actor: A multi-task transformer for robotic manipulation》;Singh 等人,《Progprompt: Generating situated robot task plans using large language models》)和视觉(Shah 和 Kumar,《Rrl: Resnet as representation for reinforcement learning》;Parisi 等人,《The unsurprising effectiveness of pre-trained vision models for control》;Nair 等人,《R3m: A universal visual representation for robot manipulation》;Ma 等人,《Vip: Towards universal visual reward and representation via value-implicit pre-training》)表征。然而,这些方法不足以进行复杂的语义推理以及对开放世界的泛化(Brohan 等人,《Do as i can, not as i say: Grounding language in robotic affordances》;Zitkovich 等人,《Rt-2: Vision-language-action models transfer web knowledge to robotic control》)。最近的研究主要集中在直接利用大语言模型(LLMs)和视觉语言模型(VLMs)的开放世界推理和泛化能力,通过提示或微调它们来生成计划(Huang 等人,《Language models as zero-shot planners: Extracting actionable knowledge for embodied agents》;《Inner monologue: Embodied reasoning through planning with language models》;Lin 等人,《Text2motion: From natural language instructions to feasible plans》;Liang 等人,《Code as policies: Language model programs for embodied control》;Singh 等人,《Progprompt: Generating situated robot task plans using large language models》;Brohan 等人,《Do as i can, not as i say: Grounding language in robotic affordances》)、构建价值(Huang 等人,《Voxposer: Composable 3d value maps for robotic manipulation with language models》)和奖励函数(Kwon 等人,《Reward design with language models》;Sontakke 等人,《Roboclip: One demonstration is enough to learn robot policies》;Yu 等人,《Language to rewards for robotic skill synthesis》;Ma 等人,《Eureka: Human-level reward design via coding large language models》;Wang 等人,《Rl-vlm-f: Reinforcement learning from vision language foundation model feedback》)。我们的工作与下面总结的视觉语言动作(VLA)模型的文献更相关。
整体式 VLA 模型作为语言条件机器人策略
整体式 VLA 模型旨在根据任务描述和图像观测直接生成机器人动作(Brohan 等人,《Rt-1: Robotics transformer for real-world control at scale》;Jiang 等人,未提及具体论文标题;Zitkovich 等人,《Rt-2: Vision-language-action models transfer web knowledge to robotic control》;Team 等人,未提及具体论文标题;Kim 等人,《Openvla: An open-source vision-language-action model》;Radosavovic 等人,《Robot learning with sensorimotor pre-training》)。整体式 VLA 模型通常由视觉语言模型(VLMs)构建而成(Liu 等人,《Visual instruction tuning》;Bai 等人,《Qwen-vl: A frontier large vision-language model with versatile abilities》;Driess 等人,《Palm-e: An embodied multimodal language model》;Lin 等人,《Vila: On pretraining for visual language models》),并在大规模机器人数据上进行训练(Brohan 等人,《Rt-1: Robotics transformer for real-world control at scale》;Collaboration 等人,《Open X-Embodiment: Robotic learning datasets and RT-X models》;Khazatsky 等人,《Droid: A large-scale in-the-wild robot manipulation dataset》),以文本或特殊标记的形式预测动作。然而,由于现有机器人数据集的覆盖范围不足,它们必须在昂贵的机器人域内数据上进行微调。此外,它们的动作频率还受到推理频率的限制,这制约了它们完成灵巧且动态任务的能力。与我们工作最相关的整体式 VLA 模型是 LLARVA(Niu 等人,《LLARVA: Vision-action instruction tuning enhances robot learning》),它除了预测机器人动作外,还能预测末端执行器的轨迹。然而,LLARVA 并不利用轨迹预测来控制机器人,而是将其作为一项辅助任务来改进动作预测。因此,LLARVA 仍然受到整体式 VLA 模型的局限性制约。相比之下,我们的工作采用分层方法,使我们能够使用专门的底层策略。这些底层策略可以接受 VLMs 无法支持的额外输入,如 3D 点云,从而实现更好的模仿学习。我们预测的路径进而使这些底层策略能够更有效地进行泛化。
2.3 VLMs 用于预测中间表示
我们的工作与先前使用视觉语言模型预测中间表示的方法存在联系。这些方法可依据预测表示的选择进行分类:
- 基于点的预测:一种常见的中间预测接口是关键点可供性(Stone 等人,《Open-world object manipulation using pre-trained vision-language models》;Sundaresan 等人,《Kite: Keypoint-conditioned policies for semantic manipulation》;Nasiriany 等人,《Rt-affordance: Affordances are versatile intermediate representations for robot manipulation》;Yuan 等人,《Robopoint: A vision-language model for spatial affordance prediction in robotics》;Kuang 等人,《Ram: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation》)。关键点可供性可以通过使用开放词汇检测器(Minderer 等人,《Simple open-vocabulary object detection》)、对 VLMs 进行迭代提示(Nasiriany 等人,《Rt-affordance: Affordances are versatile intermediate representations for robot manipulation》),或者微调检测器以按语义识别物体的特定部分(Sundaresan 等人,《Kite: Keypoint-conditioned policies for semantic manipulation》)来获取。与我们的工作最为相关的是,Yuan 等人(《Robopoint: A vision-language model for spatial affordance prediction in robotics》)对 VLM 进行微调,以预测感兴趣的物体以及放置物体的自由空间,而 Liu 等人(《未提及具体论文标题》)提出了一种基于标记的视觉提示过程,用于预测关键点可供性以及固定数量的路标点。与这些方法不同,我们的工作对 VLM 模型进行微调,使其不仅能预测点,还能预测完整的 2D 路径,这使得该模型在机器人任务中具有更广泛的适用性。
- 基于轨迹的预测:RT-trajectory(Gu 等人,《Rt-trajectory: Robotic task generalization via hindsight trajectory sketches》)提出了使用基于轨迹的任务规范来为底层策略提供条件的想法,这主要是从灵活任务规范的角度出发。该工作还简要讨论了将轨迹条件模型与预训练 VLM 生成的轨迹草图相结合的可能性。与 RT-Trajectory 互补的是,我们工作的重点并非使用轨迹草图进行任务规范,而是 VLA 的分层设计,这使得高层 VLM 可以在相对廉价和丰富的数据源上进行微调。这些数据源可以包括无动作视频或与现实世界看起来差异很大的模拟数据。我们展示了 VLM 从网络规模的预训练中获得的涌现泛化能力,使其能够转移到具有显著视觉和语义变化的感兴趣测试场景中。虽然 RT-trajectory 使用人工或现成的预训练 VLMs 来生成轨迹,但我们表明,在廉价数据源上对 VLM 模型进行微调可以生成更准确、更具泛化性的轨迹(见表 5)。此外,与单目 2D 策略(Gu 等人,《Rt-trajectory: Robotic task generalization via hindsight trajectory sketches》)相比,我们这种架构的实例能够纳入丰富的 3D 和本体感受信息。
2.4 利用仿真数据训练机器人策略
在利用仿真进行机器人学习方面已经有了大量的工作。仿真数据在强化学习(RL)中很受欢迎,因为在真实机器人系统上进行 RL 通常由于样本复杂度高和安全问题而不切实际(Lee 等人,《Learning quadrupedal locomotion over challenging terrain》;Handa 等人,《Dextreme: Transfer of agile in-hand manipulation from simulation to reality》;Torne 等人,《Reconciling reality through simulation: A real-to-sim-to-real approach for robust manipulation》)。最近,仿真也被用于直接生成(Fishman 等人,《Motion policy networks》)或引导(Mandlekar 等人,《Mimicgen: A data generation system for scalable robot learning using human demonstrations》)大规模的模仿学习数据集,以减少所需的昂贵机器人远程操作数据量。我们的工作采用了不同的方法 —— 使用仿真数据对 VLM 进行微调,并表明 VLM 能够将从仿真数据中学到的知识转移到真实机器人系统中,尽管存在显著的视觉差异。最近(Yuan 等人,《Robopoint: A vision-language model for spatial affordance prediction in robotics》)也有类似的观察,但他们使用关键点可供性作为 VLM 和底层策略之间的接口,而不是更通用的表达性 2D 路径表示。
3. 背景
3.1 通过监督学习进行模仿学习
模仿学习从专家演示中训练策略![]() ,其中s表示本体感受输入,o包括感知观测(如 RGB 图像、深度信息),z提供任务指令。给定一个专家数据集
,其中s表示本体感受输入,o包括感知观测(如 RGB 图像、深度信息),z提供任务指令。给定一个专家数据集![]() ,通过最大似然估计来优化策略,即最大化
,通过最大似然估计来优化策略,即最大化![]() 。尽管在 3D 策略表示等架构方面取得了进展(Goyal 等人,《Rvt: Robotic view transformer for 3d object manipulation》;《Rvt2: Learning precise manipulation from few demonstrations》;Ke 等人,《3d diffuser actor: Policy diffusion with 3d scene representations》),但对新颖的语义或视觉变化进行泛化仍然具有挑战性。我们探索视觉语言模型(VLMs)如何增强模仿学习模型以实现更好的泛化。
。尽管在 3D 策略表示等架构方面取得了进展(Goyal 等人,《Rvt: Robotic view transformer for 3d object manipulation》;《Rvt2: Learning precise manipulation from few demonstrations》;Ke 等人,《3d diffuser actor: Policy diffusion with 3d scene representations》),但对新颖的语义或视觉变化进行泛化仍然具有挑战性。我们探索视觉语言模型(VLMs)如何增强模仿学习模型以实现更好的泛化。
3.2 视觉 - 语言模型
视觉语言模型(VLMs)(Lin 等人,《Vila: On pretraining for visual language models》;Liu 等人,《Visual instruction tuning》)是大型 Transformer 模型(Vaswani 等人,《Attention is all you need》),能够接受视觉和文本标记以生成文本响应。它们在广泛的多模态数据集上进行预训练(Zhu 等人,《Multimodal C4: An open, billion-scale corpus of images interleaved with text》;Byeon 等人,《Coyo-700m: Image-text pair dataset》),随后在高质量的特定任务数据上进行微调(Shen 等人,《Incorporating visual layout structures for scientific text classification》;Lu 等人,《Learn to explain: Multimodal reasoning via thought chains for science question answering》)。通过将每个模态标记化为共享空间,这些模型根据图像和先前的标记自回归地生成文本标记序列。在我们的工作中,我们假设可以使用这样一个预训练的、处理文本和图像的视觉语言模型(VLM)(Lin 等人,《Vila: On pretraining for visual language models》;Liu 等人,《Visual instruction tuning》),并通过监督损失进一步微调,该损失最小化目标标记的负对数似然。
4. HAMSTER:用于机器人学习的分层动作模型
在这项工作中,我们研究视觉语言动作(VLA)模型如何利用相对丰富的数据并展示跨域转移能力,而不是仅仅依赖在机器人上收集的昂贵的观测 - 语言 - 动作数据。HAMSTER 是一类为实现此目的而设计的分层 VLA 模型,展现出可泛化且稳健的操作能力。它由两个相互连接的模型组成:首先,一个高层视觉语言模型(VLM)在大规模域外数据上进行微调,以生成中间 2D 路径指导(详见 4.1 节);其次,一个底层策略根据 2D 路径生成动作(详见 4.2 节)。
与整体式模型(Kim 等人,《Openvla: An open-source vision-language-action model》;Zitkovich 等人,《Rt-2: Vision-language-action models transfer web knowledge to robotic control》;Black 等人,《pi 0: A vision-language-action flow model for general robot control》)直接生成动作a不同,微调这种生成中间表示的分层视觉语言模型(VLM)主要有三个优点:
1. 我们的分层 VLM 可以利用缺乏精确动作的域外数据集,如模拟数据和视频;
2. 我们通过实验发现,生成 2D 路径的分层视觉语言模型(VLMs)在跨域泛化方面比整体式 VLA 模型更有效;
3. 分层设计在感官模态上提供了更大的灵活性,并允许对大型高层 VLA 模型和小型底层策略模型进行异步查询。
4.1 HAMSTER 的 VLM:从域外数据训练生成 2D 路径
HAMSTER 的高层 VLM 根据单目 RGB 图像 img 和语言指令 z 预测一条粗略的 2D 路径 p 以完成任务,即![]() 。2D 路径 p 描述了机器人末端执行器(在人类视频的情况下为人类手部)在输入相机图像上的粗略轨迹,它还包含抓取器状态的信息。正式地,2D 路径被定义为
。2D 路径 p 描述了机器人末端执行器(在人类视频的情况下为人类手部)在输入相机图像上的粗略轨迹,它还包含抓取器状态的信息。正式地,2D 路径被定义为![]() ,其中xt,yt∈[0,1]是步骤 t 时末端执行器(或手部)位置的归一化像素位置,gripper_opent是一个二进制值,表示抓取器的状态(即打开或关闭)。
,其中xt,yt∈[0,1]是步骤 t 时末端执行器(或手部)位置的归一化像素位置,gripper_opent是一个二进制值,表示抓取器的状态(即打开或关闭)。
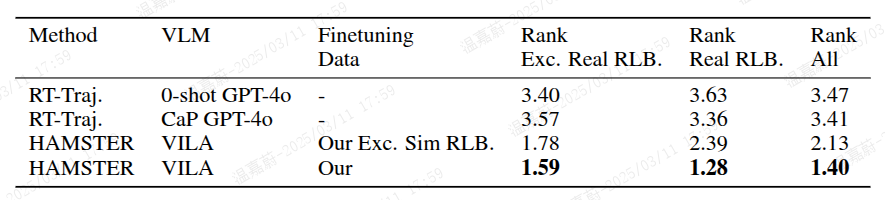
尽管任何预训练的文本和图像输入 VLM(Lin 等人,2024;Liu 等人,2024c;Achiam 等人,2023)都可以通过设置适当的提示来预测这样的 2D 路径,但我们发现预训练的 VLM 在零样本情况下难以预测这样的路径(见表 5)。
表5:不同视觉语言模型(VLMs)基于排名的人工评估结果,这些结果是在各种真实世界评估任务上的平均值。结果表明,包含模拟数据的HAMSTER模型最为有效,因为它能够从RLBench的各种任务中捕捉空间和语义信息。这明显优于Gu等人(2023年)所述的基于零样本VLM的轨迹生成方法。
因此,我们在将 VLM 与机器人场景相关联并从更易获取的来源收集路径预测的数据集上对预训练的 VLM 进行微调,这些来源即互联网视觉问答数据、其他模态的机器人数据和模拟数据。这与 Gu 等人(2023)的工作形成对比,在他们的工作中,预训练的 VLM 被要求直接执行与空间相关的路径生成任务。
我们使用 VILA-1.5-13b(Lin 等人,2024)作为基础 VLM,这是一个具有 130 亿参数的视觉语言模型,在交错的图像文本数据集和视频字幕数据上进行训练。虽然可以整理一个路径预测数据集![]() 并仅在该数据集上训练 VLM,但文献(Brohan 等人,2023a;Yuan 等人,2024)表明,在各种相关任务(均构建为视觉问答任务)上对 VLM 进行联合训练,有助于保留 VLM 的泛化能力。为此,我们整理了一个多域数据集来对该模型进行微调,以实现有效的 2D 路径预测。
并仅在该数据集上训练 VLM,但文献(Brohan 等人,2023a;Yuan 等人,2024)表明,在各种相关任务(均构建为视觉问答任务)上对 VLM 进行联合训练,有助于保留 VLM 的泛化能力。为此,我们整理了一个多域数据集来对该模型进行微调,以实现有效的 2D 路径预测。
4.1.1 微调目标和数据集
预测末端执行器的 2D 路径需要理解在给定任务中要操作的对象在像素位置方面的信息,同时还需要推断机器人应如何执行任务。为了实现这种理解,我们从广泛的模态中整理了一个多样的域外数据集Doff,包括真实世界数据、视觉问答数据和模拟数据。重要的是,用于训练 VLM 的这些域外数据都不是来自部署环境,从而强调了泛化性。
我们组装了一个数据集![]() ,其中包含图像输入imgi、语言提示zi和答案ansi,这些数据由三种类型的域外数据组成:
,其中包含图像输入imgi、语言提示zi和答案ansi,这些数据由三种类型的域外数据组成:
(1)像素点预测任务(“是什么”);
(2)模拟机器人任务(“是什么” 和 “如何做”);
(3)由轨迹组成的真实机器人数据集(“是什么” 和 “如何做”)。
我们在下面详细介绍每个数据集;有关每个数据集的提示和相应答案的可视化,请参见图 3。
图 3:域外训练数据:Doff包含(a)像素点预测:来自 RoboPoint 的 770k 个对象定位任务。(b)模拟机器人数据:来自 RLBench 环境的 320k 个 2D 末端执行器路径。(c)真实机器人数据:来自 Bridge 和 DROID 轨迹的 110k 个 2D 末端执行器路径
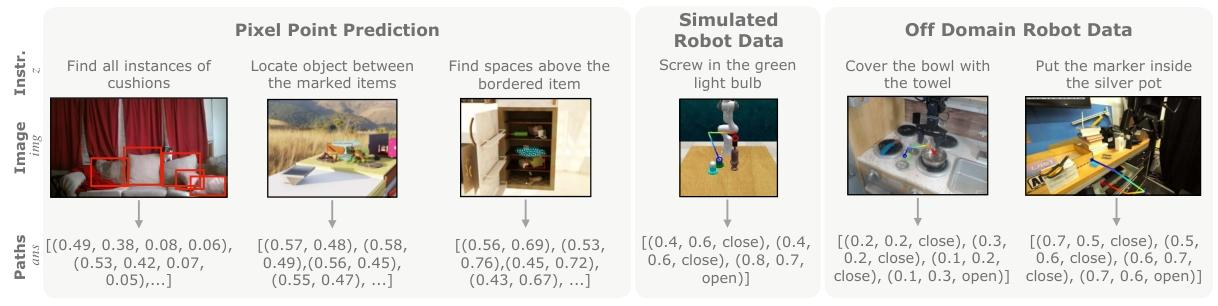
- 像素点预测:对于像素点预测,我们使用 RoboPoint 数据集(Yuan 等人,2024),其中包含 770k 个像素点预测任务,大多数答案表示为与图像上位置对应的 2D 点列表。一个样本由一个提示z(如 “Locate object between the marked items”)、一个输入图像img和一个答案ans(如[(0.25,0.11),(0.22,0.19),(0.53,0.23)] )组成 。见图 3 左侧的示例。该数据集由在模拟中自动生成并从现有真实世界数据集收集的数据组成;其多样的任务使 HAMSTER VLM 能够在不同场景中推断像素与对象之间的关系,同时保留其语义泛化能力。
- 模拟机器人数据:我们还从 RLBench(James 等人,2020)中生成了一个模拟机器人任务数据集,RLBench 是一个模拟 Franka 机器人进行各种抓取和非抓取桌面操作任务的模拟器。我们使用模拟器的内置规划算法自动生成成功的操作轨迹。给定一个轨迹,我们使用前摄像头的第一帧作为图像输入img。我们构建提示z,指示 VLM 提供一系列点来表示机器人抓手为实现给定语言指令的轨迹(见图 2)。真实的 2D 路径p=[(xt,yt,gripper_opent)]t通过使用正向运动学和相机参数的本体感受投影获得。我们为 RLBench 中的 81 个机器人操作任务中的每个任务生成 1000 个情节,每个情节有 4 个语言指令,总共约有 320k 个(img,z,ans)元组,其中ans=p 。见图 3 中间的示例。
- 真实机器人数据:使用真实机器人数据可以确保 VLM 在基于场景(包括真实机器人手臂)进行条件设定时,能够推断对象和机器人抓手的路径。我们使用来自非部署环境的现有在线机器人数据集来实现 VLM 的这种能力。我们从 Bridge 数据集(Walke 等人,《Bridgedata v2: A dataset for robot learning at scale》;Collaboration 等人,《Open X-Embodiment: Robotic learning datasets and RT-X models》)中获取 10k 个轨迹,该数据集由一个 WidowX 手臂(与测试机器人的实体不同)执行操作任务,以及从 DROID(Khazatsky 等人,《Droid: A large-scale in-the-wild robot manipulation dataset》)中获取约 45k 个轨迹。我们以与模拟 RL-Bench 数据类似的方式,将这两个数据集转换为视觉问答数据集,其中 2D 路径是从本体感受和相机参数中提取的(见图 3 右侧的示例)。需要注意的是,我们本质上是将机器人数据用作视频数据,通过随时间跟踪末端执行器来获取路径。原则上,也可以在原始视频上使用任何数量的点跟踪方法(Doersch 等人,《Tapir: Tracking any point with per-frame initialization and temporal refinement》)来实现这一点,而无需动作或本体感受标签。
我们通过从整个数据集中以相等的权重随机采样,对 HAMSTER VLM 在所有这三种类型的数据上进行微调。我们还纳入了一个包含 660k 样本的视觉问答数据集(Liu 等人,《Improved baselines with visual instruction tuning》)用于联合训练,以保留世界知识。我们使用标准化的监督预测损失来最大化答案ans的对数似然,即![]()
注:模拟数据和真实机器人数据存在的一个问题是,提取的 2D 路径p可能会非常长,例如超过一百步。由于我们希望 HAMSTER VLM 在高层次上进行推理,而不是与底层控制策略在相同的尺度上,因此我们使用 Ramer-Douglas-Peucker 算法(Ramer,《An iterative procedure for the polygonal approximation of plane curves》;Douglas & Peucker,《Algorithms for the reduction of the number of points required to represent a digitized line or its caricature》)对路径po进行简化,该算法可以将由线段组成的曲线简化为点数更少的相似曲线。有关消融研究的内容,请读者参考附录 G。
4.2 路径引导的底层策略学习
HAMSTER 的底层策略![]() 以本体感受和感知观测、(可选的)语言指令以及重要的 2D 路径为条件。虽然底层控制策略可以在没有 2D 路径的情况下学习解决任务,但路径使底层策略能够省去长期规划和语义推理,专注于局部和几何预测以生成机器人动作。正如我们通过实验发现的(见图 4),2D 路径显著提高了底层策略在视觉和语义方面的泛化能力。
以本体感受和感知观测、(可选的)语言指令以及重要的 2D 路径为条件。虽然底层控制策略可以在没有 2D 路径的情况下学习解决任务,但路径使底层策略能够省去长期规划和语义推理,专注于局部和几何预测以生成机器人动作。正如我们通过实验发现的(见图 4),2D 路径显著提高了底层策略在视觉和语义方面的泛化能力。
HAMSTER 的通用路径条件框架允许底层策略接收本体感受和感知(例如深度图像)观测,这些观测不会输入到高层 VLM 中。我们考虑基于 3D 感知信息的底层策略,即![]() ,在配备标准深度相机的机器人平台上,这些信息在测试时是可用的。我们研究了两种策略架构选择,RVT-2(Goyal 等人,《Rvt2: Learning precise manipulation from few demonstrations》)和 3D-DA(Ke 等人,《3d diffuser actor: Policy diffusion with 3d scene representations》),后者在流行的机器人操作基准测试(James 等人,《Rlbench: The robot learning benchmark & learning environment》)中展示了最先进的结果。
,在配备标准深度相机的机器人平台上,这些信息在测试时是可用的。我们研究了两种策略架构选择,RVT-2(Goyal 等人,《Rvt2: Learning precise manipulation from few demonstrations》)和 3D-DA(Ke 等人,《3d diffuser actor: Policy diffusion with 3d scene representations》),后者在流行的机器人操作基准测试(James 等人,《Rlbench: The robot learning benchmark & learning environment》)中展示了最先进的结果。
基于路径的条件设定:大多数策略架构采用![]() 的形式,不包含 2D 路径输入。一种简单的方法是将路径与本体感受或语言输入连接起来。然而,由于 2D 路径的长度会有所不同,架构必须处理可变长度的输入。为了在不进行重大修改的情况下纳入来自 VLM 的 2D 路径p^,我们选择将 2D 路径叠加到图像观测上(Gu 等人,《Rt-trajectory: Robotic task generalization via hindsight trajectory sketches》)。我们的实现遵循这种方法,在轨迹
的形式,不包含 2D 路径输入。一种简单的方法是将路径与本体感受或语言输入连接起来。然而,由于 2D 路径的长度会有所不同,架构必须处理可变长度的输入。为了在不进行重大修改的情况下纳入来自 VLM 的 2D 路径p^,我们选择将 2D 路径叠加到图像观测上(Gu 等人,《Rt-trajectory: Robotic task generalization via hindsight trajectory sketches》)。我们的实现遵循这种方法,在轨迹![]() 中的所有图像上绘制彩色轨迹:每个(xt,yt)点用线段连接,通过颜色渐变表示时间顺序(见图 2 (b)),并用圆圈标记抓取器状态的变化(例如,绿色表示关闭,蓝色表示打开)。如果策略架构允许图像有三个以上的通道,我们也可以将路径绘制作为单独的通道,而不是叠加在 RGB 通道上。我们在 5.3 节中对叠加和通道连接这两种绘制策略进行了实证研究。
中的所有图像上绘制彩色轨迹:每个(xt,yt)点用线段连接,通过颜色渐变表示时间顺序(见图 2 (b)),并用圆圈标记抓取器状态的变化(例如,绿色表示关闭,蓝色表示打开)。如果策略架构允许图像有三个以上的通道,我们也可以将路径绘制作为单独的通道,而不是叠加在 RGB 通道上。我们在 5.3 节中对叠加和通道连接这两种绘制策略进行了实证研究。
- 策略训练:为了训练策略,我们在机器人硬件上收集了一个相对小规模的特定任务数据集D={(si,oi,zi,ai)}i=1N。在训练过程中,我们使用通过本体感受投影构建的 “神谕” oracle 2D 路径,类似于为 VLM 训练数据构建 2D 路径的方式,并构建带有路径标签的数据集Dpath={(si,oi,zi,pi,ai)}i=1N。我们使用标准的监督模仿学习目标在Dpath上训练策略πθ(a∣s,o,z,p),以最大化数据集中动作的对数似然:E(si,oi,zi,pi,ai)∼Dpilogπθ(ai∣si,oi,zi,pi)。有关更多实现细节,请参见附录 B。
- 推理速度:整体式 VLA 模型在每个动作步骤都查询 VLM(Kim 等人,《Openvla: An open-source vision-language-action model》;Brohan 等人,《Rt-2: Vision-language-action models transfer web knowledge to robotic control》),对于大型 VLM 来说,这可能非常耗时。例如,OpenVLA 的 70 亿参数 VLA 模型在 RTX 4090 上的运行频率仅为 6Hz(Kim 等人,《Openvla: An open-source vision-language-action model》)。相比之下,HAMSTER 的分层设计允许我们在一个情节中仅查询 VLM 一到几次,以生成 2D 路径P^,底层策略可以跟随这些路径执行多个步骤。因此,HAMSTER 可以扩展到大型 VLM 骨干网络,而无需终端用户担心推理速度。
5. 实验评估
我们在模拟环境和现实世界中都进行了实证评估。实验旨在回答以下问题:
1)分层 VLA 模型能否实现对未见场景的行为泛化?
2)分层 VLA 模型是否比整体式 VLA 模型或底层模仿学习方法表现出更有效的跨域泛化能力?
3)分层 VLA 模型学习到的行为对显著的视觉和语义变化是否具有鲁棒性?
4)分层 VLA 模型能否实现非抓取和长期任务的学习?
5)对高层 VLM 进行明确的微调是否在空间和语义推理方面有优势?
5.1 桌面操作的现实世界评估
为了回答问题1,我们的现实世界评估实验旨在测试分层视觉-语言-动作(VLA)模型在显著的语义和视觉变化情况下的泛化能力。具体而言,我们考虑一种 HAMSTER 的变体,它使用在 4.1 节中的混合数据上进行微调的视觉语言模型(VLM)(VILA-1.5-13b(林等人,2024 年))作为高层预测器,并采用两种底层 3D 策略架构 ——RVT-2(戈亚尔等人,2024 年)和 3D 扩散执行者(3D-DA)(柯等人,2024 年)作为 4.2 节中所述的底层策略选项。底层 3D 策略使用通过远程操作收集的 320 个情节进行训练,如图 3 所示。重要的是,高层 VLM 没有见过任何域内数据,仅在 4.1 节中描述的域外数据上进行了微调。这表明 VLM 所展现出的任何泛化能力都源自跨域迁移。
- **基线比较**。为了回答问题2,我们将HAMSTER与最先进的整体式视觉-语言-动作模型(VLA)OpenVLA(金等人,2024年),以及非视觉语言模型的3D策略RVT-2(戈亚尔等人,2024年)和3D-DA(柯等人,2024年)进行比较。为了进行公平比较,我们在上述收集的域内数据上对OpenVLA进行微调,因为OpenVLA在零样本泛化方面表现不佳。3D策略(RVT-2、3D-DA)基线使用与训练HAMSTER底层策略相同的远程操作数据进行训练,但没有来自HAMSTER的视觉语言模型(VLM)的中间2D路径表示。
- 使用 RLBench 对 OpenVLA 进行微调
为确保我们的方法相较于 OpenVLA(Kim 等人,2024 年)的优势并非仅仅源于 RLBench 数据,我们在与 HAMSTER 的视觉语言模型(VLM)所用的相同 RLBench 数据集上对 OpenVLA 进行微调。该数据集涵盖 81 个任务,每个任务有 1000 个情节(仅选用前摄像头视野良好的情节),直至标记准确率超过 90%(Kim 等人,2024 年)。随后,我们依据附录 C.2 中的流程,在我们的任务上对该模型进一步微调。
在现实世界的拾取和放置实验中(对表 4 所示的 6 个 “基础” 任务进行 6 次试验),经 RLBench 微调后的 OpenVLA 平均成功得分是 0.54,而未经 RLBench 微调的模型平均成功得分是 0.58。这表明,像 OpenVLA 这类整体式视觉 - 语言 - 动作(VLA)架构从 RLBench 数据中获益甚微,这可能是因为其动作和观测空间与现实世界的设置不匹配。 - 定量结果
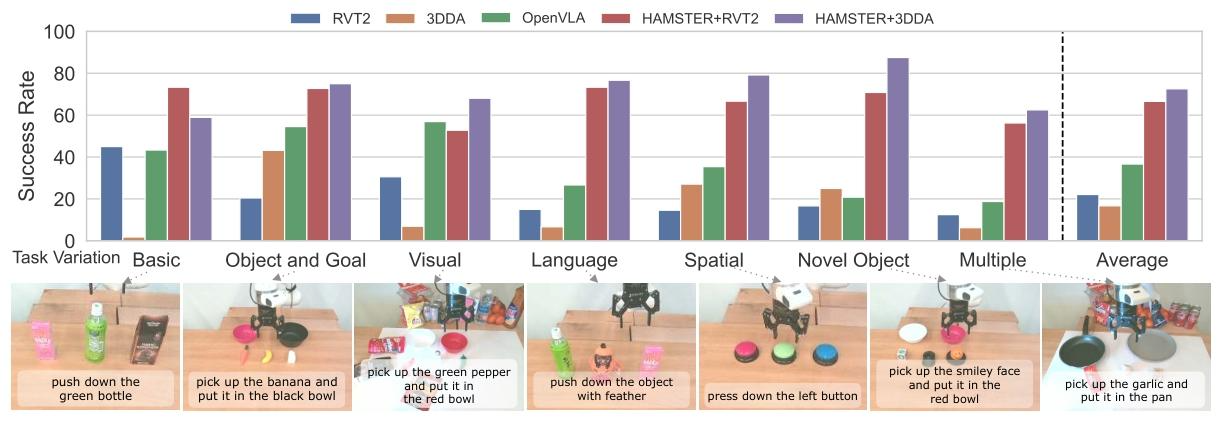
图 4 总结了我们在现实世界中的实验结果。为了回答问题 3,我们对多种任务类型进行了评估,包括 “拾取与放置”,以及 “按下按钮” 和 “撞倒物体” 等非抓取任务。我们还从多个维度(问题 1)测试了模型的泛化能力 —— 对象与目标:未见过的对象 - 目标组合;视觉:桌面纹理、光照以及干扰物体方面的视觉变化;语言:未见过的语言指令(例如,将 “candy” 替换为 “sweet object”);空间:指令中未见过的对象空间关系;新对象:未见过的对象;最后,多重变化:多种变化的组合。总的来说,我们在 74 个任务上对每个模型进行了评估,总共进行了 222 次评估。详细结果和成功分数指标见附录表 4。 - 对各类任务的定性评估
除了为与 OpenVLA 进行比较而开展的定量评估之外,我们还给出了定性结果,这些结果展示了 HAMSTER 的分层结构是如何使底层策略模型能够泛化到更复杂的任务上的。图 5 展示了 HAMSTER 能够处理的各种不同任务,包括展开毛巾、打开和关闭抽屉、按下按钮、擦拭表面以及清理桌子。这些任务带来了诸如光照条件变化、背景杂乱以及需要外部世界知识的语义理解等方面的挑战。此外,HAMSTER 还展示了执行长期任务的能力,而这些任务都不在用于训练策略模型的域内训练集当中。
总体而言,我们发现 HAMSTER 的平均表现显著优于整体式视觉 - 语言 - 动作(VLA)模型和(非视觉语言模型的)3D 策略,分别超出两倍和三倍以上。这一点意义重大,因为这种性能提升是在测试环境中存在显著的视觉和语义变化的情况下实现的,这表明 HAMSTER 比整体式 VLA 模型或非 VLM 基础模型具有更强的泛化能力。我们在表 6 中进一步按任务类型对结果进行了分类,从中可以看出,在所有任务类型(拾取和放置、按下按钮以及撞倒物体)上,HAMSTER 的表现均优于 OpenVLA。有关评估条件、任务列表和其他实验细节,请参见附录 C,有关失败模式的内容,请参见附录 E。
5.2 模拟评估
总体结果
为了进一步探究问题 1、问题 2 和问题 3,我们使用了 Colosseum(普马凯等人,2024 年)进行了一项受控模拟评估。Colosseum 在拾取放置任务和非抓取任务中提供了显著的视觉和语义变化。我们将我们的高层视觉语言模型(VLM)与 RLBench 上最先进的 3D 扩散执行者(3D-DA)(柯等人,2024 年)策略相结合,将 HAMSTER 与没有路径引导的普通 3D-DA 实现进行了比较。如表 3 所示,在 5 次随机种子实验中,HAMSTER 的平均表现比普通方法高出 31%。这种性能提升源于使用绘制了路径的图像进行训练,这促使策略专注于路径,而非无关的视觉特征,从而增强了对视觉变化的鲁棒性。有关变化的详细信息,读者可参考普马凯等人(2024 年)的研究,有关进一步的模拟实验细节,请参见附录 F。
Table 1: Results on Colosseum demonstrate that HAMSTER is data efficient,achieving 2X the success score of 3D-DA with just 50% of the data

使用较少演示数据的HAMSTER。为了回答问题4,我们还测试了HAMSTER在有限演示数据情况下良好运行的能力。我们在Colosseum的5个子任务上进行了测试,具体是:将方块滑动到目标位置、把酒放置在酒架处、插入方栓、堆叠杯子、摆放国际象棋。表1中的结果表明,仅使用50%数据的HAMSTER + 3D-DA的成功率仍是标准3D-DA的两倍,这证明了HAMSTER在下游的模仿学习任务中,在演示数据的利用上效率很高。
5.3 泛化和消融研究
最后,我们进行了额外的实验,以回答关于HAMSTER的分层结构是否能实现更出色的视觉和语义推理能力的问题5。
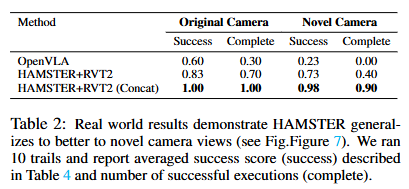
### 相机视角不变性
我们从新的相机角度(图7)对HAMSTER + RVT2和OpenVLA进行测试,通过使用6个训练对象和3个训练容器进行10次拾取和放置试验,来检验HAMSTER的视觉空间推理能力。

表2中的结果表明,HAMSTER的表现显著优于OpenVLA,并且对新的相机角度具有鲁棒性,这得益于其视觉语言模型(VLM)是在跨越各种视角的不同域外任务上进行训练的。 此外,我们比较了HAMSTER + RVT2(连接方式),在这种方式中,我们不是将路径叠加在输入的RGB图像上,而是对RVT2进行修改,使其通过将原始RGB图像与一张仅包含绘制路径的独立RGB图像相连接,来接受6通道的输入。由于HAMSTER的分层特性,我们能够轻松应用这种方法。 实际上,连接方式的路径实现了最佳性能,这证明了这种路径表示方式的有效性,尽管它的通用性较差,并且并不与所有的模仿学习策略架构都兼容(比如3D-DA,因为它使用的是一个期望3通道输入的预训练图像编码器)。一种可能的解释是,当2D路径直接绘制在图像上时,RVT2的虚拟重投影可能会使该路径变得碎片化,从而增加了RVT2对其进行解码的难度。而通过提供一个专门的路径通道(通过连接的方式),路径引导能够更有效地得以保留。
### 视觉语言模型(VLM)的泛化能力
我们进一步展示了HAMSTER分层结构的优势,具体表现为其视觉语言模型由于经过了域外微调,能够很好地泛化到在视觉上独特且在语义上具有挑战性的任务中。我们在图8中可视化呈现了HAMSTER路径绘制的示例,这表明HAMSTER的视觉语言模型本身能够针对未曾见过的任务,有效地进行语义和视觉方面的推理。
图8:HAMSTER的视觉语言模型(VLM)展现出了对未见过场景的强大泛化能力。从左至右:(a)利用世界知识来完成用户指定的任务,(b)处理像手绘草图这样的域外输入,以及(c)从多样的模拟场景迁移到在视觉上截然不同的现实世界任务。蓝到红的线条表示运动轨迹,蓝色圆圈和红色圆圈分别标记抓取点和释放点。

我们在附录D.1中进一步研究了视觉语言模型的性能,结果发现:(1)HAMSTER的表现优于从闭源视觉语言模型中进行的零样本路径生成(顾等人,2023年;梁等人,2023年);(2)纳入模拟数据能够提升HAMSTER在现实世界中的性能。这两个结果都指向了显式分层结构的优势:即通过对域外视觉语言模型进行微调来提升其性能。更多详细信息请参见附录D.1。
6. 结论与局限
总之,HAMSTER 研究了分层 VLA 模型的潜力,在机器人操作中实现了强大的泛化能力。它由一个经过微调的 VLM 和一个底层策略组成,前者能够准确预测机器人操作的 2D 路径,后者则学习使用这些 2D 路径生成动作。这种两步式架构实现了跨显著领域转移的视觉泛化和语义推理,同时使基于 3D 输入等条件的高效专业策略能够执行底层动作。
这项工作是朝着开发通用分层 VLA 方法迈出的第一步,未来有许多改进和扩展的机会。所提出的工作仅在 2D 空间中生成点,没有进行原生 3D 预测。这使得 VLM 无法拥有真正的 3D 空间理解能力。此外,仅使用 2D 路径的接口带宽有限,无法传达诸如力或旋转等细微信息。未来,研究可学习的中间接口是一个有前景的方向。而且,直接从大规模人类视频数据集训练这些 VLM 也很有前景。
A、视觉语言模型(VLM)微调数据集详情
像素点预测数据
我们的点预测数据集来自于Robopoint(袁等人,2024年)。我们的点预测数据集中有77万个样本,其包含的标签是以一组无序点的形式给出的,例如![]() ,或者是
,或者是![]() 格式的边界框。除此之外,参照Robopoint(袁等人,2024年)的做法,我们使用了包含66万个样本的视觉问答(VQA)数据集(刘等人,2024b),该数据集中的样本以自然语言回答诸如“这个人在喂猫吃什么?”这样的视觉问答查询。我们保留这些数据的原样,因为这些视觉问答查询很可能有助于提升视觉语言模型(VLM)的语义推理和视觉泛化能力;我们按照给定的完整Robopoint数据集对HAMSTER的视觉语言模型进行微调。
格式的边界框。除此之外,参照Robopoint(袁等人,2024年)的做法,我们使用了包含66万个样本的视觉问答(VQA)数据集(刘等人,2024b),该数据集中的样本以自然语言回答诸如“这个人在喂猫吃什么?”这样的视觉问答查询。我们保留这些数据的原样,因为这些视觉问答查询很可能有助于提升视觉语言模型(VLM)的语义推理和视觉泛化能力;我们按照给定的完整Robopoint数据集对HAMSTER的视觉语言模型进行微调。
模拟数据。我们从RLBench的103个任务中选取了81个任务来生成数据,剔除了那些在RLBench中前摄像头视野可见性较差的任务。我们将每个情节中的第一张图像与每条语言指令相结合。最终的数据集包含大约32万条轨迹。
真实机器人数据。对于仅提供RGB图像的Bridge(瓦尔克等人,2023年)数据集,我们通过迭代估计每个情节的外参矩阵来提取轨迹。在每个场景中,我们随机采样几帧图像,并手动标记夹爪手指的中心位置。利用相应的末端执行器姿态,我们使用透视n点(PnP,Perspectiven-Point)方法计算三维到二维的投影矩阵。然后,我们将这个投影矩阵应用于各个情节,并手动检查投影的夹爪与实际夹爪之间是否存在任何偏差。存在显著偏差的情节将被过滤掉,然后开始新一轮的操作来估计它们的外参矩阵。
对于DROID(哈扎茨基等人,2024年)来说,该数据集的很大一部分包含有噪声的相机外参信息,这些信息无法实现良好的深度对齐。因此,我们根据投影深度图像与RGB图像之间的对齐情况,筛选掉了外参质量较差的轨迹。这样筛选后得到了约4.5万条轨迹(约2.2万条不同的轨迹,因为每条轨迹有2个不同的相机视角),我们用这些轨迹来构建第4.1节中所述的视觉语言模型(VLM)数据集\(Doff\) 。
B IMPLEMENTATION AND ARCHITECTURE DETAILS
B.1 VLM IMPLEMENTATION DETAILS
视觉语言模型(VLM)提示词。我们在图10中列出了用于在模拟数据和真实机器人数据上进行微调以及评估的提示词。除了在对像素点预测数据(即来自Robopoint(袁等人,2024年)的数据)进行训练时使用数据集中给定的提示词外,我们让模型以一张图像和提示词为条件进行运算。请注意,我们要求模型将夹爪的状态变化以独立的语言标记形式输出,例如“打开夹爪”/“关闭夹爪”,而不是像图2这样的简化图示中以数值的形式呈现。

视觉语言模型(VLM)轨迹处理。如第4.1节所述,直接使用路径标签\(p^{o}\)进行训练存在的一个问题是,许多路径可能会极长。因此,我们使用拉默-道格拉斯-普克算法(Ramer,1972年;Douglas和Peucker,1973年)对路径\(p^{o}\)进行简化,该算法能将由线段组成的曲线简化为点数更少的相似曲线。我们对模拟数据和真实机器人数据所生成的路径运行此算法,以便为\(D_{off}\)生成标签\(p^{o}\) 。我们使用的容差\(\epsilon = 0.05\),这样一来,每个短视距任务的路径大约由2到5个点组成。
视觉语言模型(VLM)训练细节。我们在一个配备了八块英伟达A100 GPU的节点上对我们的视觉语言模型VILA1.5-13B(林等人,2024年)进行训练,每块GPU大约使用65GB的内存。训练过程大约需要30个小时才能完成。我们使用的有效批量大小为256,学习率为\(1×10^{-5}\) 。在微调过程中,整个模型(包括视觉编码器)都会进行更新。
B.2 LOW-LEVEL POLICY TRAINING DETAILS
我们训练RVT2(戈亚尔等人,2024年)和3D-DA(柯等人,2024年)作为我们的底层策略。我们保持整体架构和训练超参数与论文中设置的一致。除了二维路径投影之外,以下是关于输入是如何被修改的具体细节。
在底层策略训练方面,我们依据通过将轨迹末端执行器的点投影到相机图像上所构建的真实路径来训练这些策略。为了确保在评估过程中,这些策略对于由HAMSTER视觉语言模型(VLM)预测所引入的可能误差具有鲁棒性,我们在训练期间向二维路径\((x, y)\)图像点添加少量的随机噪声(\((N(0, 0.01))\) ),以得到略有噪声的路径绘制结果。夹爪张开/闭合指示值未添加噪声。
RVT2(戈亚尔等人,2024年)。当以HAMSTER的二维路径作为条件时,我们去掉了RVT-2的语言指令。
3D-DA(柯等人,2024年)。在Colosseum环境中的模拟实验里,无需进行任何改动。实际上,当去掉针对Colosseum任务的语言指令时,我们发现HAMSTER+3D-DA的性能有所下降;而在使用简化的语言指令时,其性能也出现了小幅下降。这很可能是由于3D-DA的视觉注意力机制,该机制会使CLIP语言标记嵌入与CLIP视觉特征进行交叉关注,因此详细的语言指令是有益的。
C REAL WORLD EXPERIMENT DETAILS
C.1 TRAINING TASKS AND DATA COLLECTION
在我们的真实世界实验中,我们按照哈扎茨基等人(2024年)所描述的设置,通过人工远程操作,使用了一台Franka Panda机械臂来收集所有数据。下面,我们来介绍一下训练任务:

在训练需要关键帧作为标签的RVT2时,除了标记夹爪执行“打开夹爪”和“关闭夹爪”动作的帧之外,我们还纳入了捕捉夹爪朝着这些关键帧移动时的中间运动的帧。
C.2 BASELINE TRAINING DETAILS
OpenVLA(金等人,2024年)。按照金等人(2024年)的做法,在我们所有的实验中,我们仅采用参数高效微调(低秩适配器,LoRA)的方法,因为他们的研究表明,这种方法在性能上与全量微调相当,同时效率要高得多。我们采用推荐的默认秩\(r = 32\) 。为了与所有基线模型的分辨率匹配,我们选择了\(360×360\)的分辨率。我们还遵循推荐的做法,对模型进行训练,直到其标记准确率超过\(95\%\)。然而,对于某些微调数据集,标记准确率在接近\(90\%\)时就收敛了。当我们观察到标记准确率收敛时,就会选择模型的检查点,这通常需要使用全局批量大小为\(16\)或\(32\),经过\(3000\)到\(10000\)步的训练。训练使用\(1\)块或\(2\)块A6000 GPU(这决定了全局批量大小是\(16\)还是\(32\))来进行。根据经验,我们发现已经收敛的检查点在现实世界中的表现非常相似。例如,当我们对经过\(3000\)步训练且已收敛的检查点进行评估时,对同一次运行中经过\(5000\)步训练的检查点进行评估,得到的性能结果非常相近。
RT-轨迹(顾等人,2023年)。为了进行表5中的比较,我们实现了两个版本的RT-轨迹。第一个版本(零样本GPT-4o)直接使用GPT-4o,通过一个与我们用于HAMSTER的提示词非常相似的提示词来生成二维路径,该提示词如图11所示。

第二个版本是按照RT-轨迹中所描述的那样,在“代码即策略”(梁等人,2023年)的基础上实现RT-轨迹。我们使用OWLv2(明德勒等人,2023年)对图像执行开放词汇的目标检测,以生成一个目标列表作为场景描述,然后使用图12中所示的提示词来促使RT-轨迹运行。我们也将GPT-4o用作这种方法的主干模型。

C.3 EVALUATION TASKS
我们在抓取与放置、撞倒物体以及按下按钮等任务上对我们的方法进行评估,这些任务面临着各种各样的泛化挑战,如图4所示。详细结果见表4。按照(金等人,2024年)的做法,我们为每一个成功的子动作计分。对于视觉语言模型(VLM),我们聘请了人类专家来评估预测轨迹的正确性。
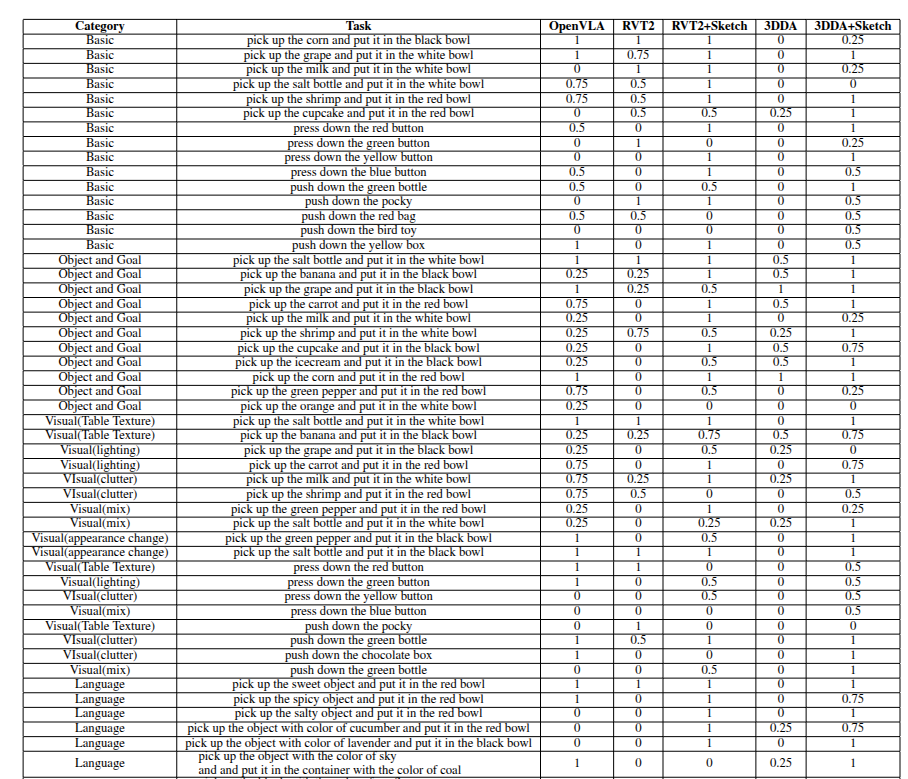
表4:真实世界评估的详细结果。第一列表示变化类别,而第二列给出了语言指令。对于抓取和放置任务,每成功完成一个动作得0.25分:到达物体处、拿起物体、将物体移至目标容器处并放入容器内。对于撞倒物体任务,触摸到正确的物体并成功将其撞倒得0.5分。对于按下按钮任务,将夹爪定位在正确的按钮上方并成功按下按钮得0.5分。
D EXTENDED RESULTS
D.1 IMPACT OF DESIGN DECISIONS ON VLM PERFORMANCE
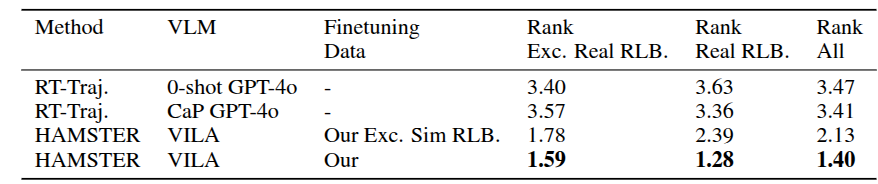
为了更好地理解所提出的分层视觉语言行为(VLA)模型的迁移和泛化性能,我们分析了在训练高层视觉语言模型(VLM)过程中所涉及的各种决策的影响。我们在一个随机收集的真实世界测试图像数据集上,对已训练的高层视觉语言模型的不同变体进行了人工评估,如图8所示。我们要求每个模型生成与诸如“把右边的方块移到泰勒·斯威夫特旁边”或“把灯泡拧到灯里”等指令相对应的二维路径轨迹(完整的指令集见附录D.2)。然后,我们将每种方法生成的路径提供给之前从未见过任何模型预测结果的人工评估人员。接着,人工评估人员对每种方法的预测结果进行排名;我们在表5中报告了这些样本的平均排名情况。
表5:基于排名的不同视觉语言模型(VLM)人工评估结果,该结果是在各种真实世界评估任务上的平均值。结果表明,纳入模拟数据的HAMSTER最为有效,因为它捕捉到了来自RLBench的不同任务中的空间和语义信息。这大大优于顾等人(2023年)所描述的基于零样本视觉语言模型的轨迹生成方法。
我们对以下视觉语言模型(VLM)进行评估:
(1)使用与我们相似提示词(如图11所示)的零样本最先进的闭源模型,如GPT-4o;
(2)同样是零样本最先进的闭源模型,如GPT-4o,但按照顾等人(2023年)所述,使用“代码即策略”(梁等人,2023年)来生成路径(提示词见图12);
(3)在第4.1节所述的数据源上进行微调的开源模型(VILA-1.5-13b),但不包括来自RLBench数据集的模拟轨迹;
(4)在第4.1节所述的数据源上进行微调的开源模型(VILA-1.5-13b),包括来自RLBench数据集的路径草图。
这些评估的目的,首先是与顾等人(2023年)使用预训练的闭源视觉语言模型生成二维轨迹的紧密相关工作进行比较(对比(1)和(2))。(3)和(4)(我们的完整方法)之间的比较,旨在分离纳入RLBench数据集的模拟路径草图所产生的影响。通过这样做,我们分析视觉语言模型预测中间路径以在差异显著的领域(从RLBench到真实世界)进行迁移的能力。
结果表明:(1)即使是零样本路径生成,即便是像GPT-4o这样的闭源视觉语言模型(如顾等人(2023年)所研究的),在借助“代码即策略”(梁等人,2023年)的额外辅助的情况下,其表现也不如像HAMSTER那样在跨域数据上进行微调的视觉语言模型;(2)在微调过程中纳入差异显著的训练数据,比如低保真度的模拟数据,能够提升在真实世界中的表现。这凸显了HAMSTER在差异极大的领域中所展现出的可迁移性。这些结果强调,尽管存在相当大的感知差异,HAMSTER中所描述的分层视觉语言行为(VLA)方法能够有效地利用各种来源的低成本先验数据来进行二维路径预测。
D.2 VLM REAL WORLD GENERALIZATION STUDY
本研究的完整任务描述列表如下(主要实验细节见附录D.1)。重复项表示针对同一任务的不同图像。我们在图13中绘制了一些额外的对比示例。请注意,本次实验图像中的路径绘制惯例与第4.2节中所述提供给底层策略的有所不同,因为这种彩色线条更便于人工评估人员查看。
图13:针对视觉语言模型(VLM)的人工评估示例图像、指令,以及分别来自未在(RLBench)模拟数据上进行任何微调的HAMSTER模型、在第4.1节所述所有数据上进行了微调的HAMSTER模型、由GPT-4o(阿奇亚姆等人,2023年)支持且基于“代码即策略”(梁等人,2023年)的RT-轨迹模型(顾等人,2023年),以及直接由GPT-4o支持的RT-轨迹模型的相应轨迹。


D.3 HUMAN RANKING
由于完成同一任务可能存在多种不同的轨迹,我们采用人工排名的方式,来比较所生成的轨迹完成任务的可能性,而非使用均方误差(MSE)等定量指标。为此,我们使用未纳入RLBench数据的HAMSTER模型、HAMSTER模型、“代码即策略”模型(梁等人,2023年)以及GPT-4o模型(阿奇亚姆等人,2023年),为48组图像-问题对生成轨迹。示例见图14。
图14:人工排名结果的一个示例。轨迹从蓝色指向红色,蓝色圆圈和红色圆圈分别表示夹爪闭合点和夹爪打开点。评分者被要求对这些轨迹进行排序,判断哪条轨迹成功的可能性最大。

我们招募了5名机器人学习领域的研究人员作为人工评估员,他们此前未见过HAMSTER的路径输出结果。我们要求他们根据以下指令对这4个视觉语言模型(VLM)进行评分:“为每种方法给出一个排名(1表示最佳,4表示最差)。在你看来,哪条机器人轨迹最有可能成功。轨迹从蓝色指向红色,蓝色圆圈表示夹爪闭合,红色圆圈表示夹爪打开。如果评估员认为某些轨迹表现相当,他们可以给多条轨迹相同的分数。由于他们是机器人学习领域的研究人员,所以熟悉那些更有可能成功的轨迹类型。因此,这些排名可作为一种有意义的轨迹质量衡量标准。
E FAILURE ANALYSIS
本节概述了我们在实验过程中观察到的失败模式,并对其成因进行了详细分析。失败的原因可归结为轨迹预测、轨迹遵循以及动作执行等方面存在的问题。
E.1 DIFFERENT FAILURE MODES
轨迹预测失败
视觉语言模型(VLM)可能会由于以下几个因素而无法预测出正确的轨迹:
无法理解语言目标:尽管视觉语言模型(VLM)在处理各种不同的任务描述方面展现出了强大的能力,但当训练集中缺少类似的任务时,它就会遇到困难。这可能会导致模型误解任务目标,从而做出不准确的预测。
- 轨迹预测错误:在某些情况下,视觉语言模型(VLM)会预测出错误的轨迹,原因要么是与错误的物体进行了交互,要么是对可行操作的方向产生了误解。
- 环境中的动态变化:由于轨迹是在任务开始时生成的,在执行任务过程中环境发生的显著变化可能会导致任务失败。该模型缺乏动态调整轨迹或重新识别最初所涉及物体的能力。
轨迹遵循失败
无法遵循预测轨迹的情况主要由以下原因导致:
三维模糊性:使用二维轨迹预测会带来模糊性问题,比如难以确定一个点是位于物体上方还是后方,这就会导致执行错误。
错误的物体交互:底层动作模型并没有受到明确的约束来严格遵循预测的轨迹。因此,它可能会出现偏差,与错误的物体进行交互,从而导致任务失败。
动作执行失败
即使轨迹被正确预测且得到了遵循,动作执行仍然可能会因为以下原因而失败:
- 与执行相关的特定问题:尽管在一系列多样化的动作上进行了训练,模型在执行过程中仍可能会失败。例如,在抓取任务中,错误的抓取角度可能会导致物体滑落,从而造成抓取失败。
E.2 FAILURE ANALYSIS
我们在图15中的分析揭示了不同方法存在的明显失败倾向。
Figure 15: Performance Distribution of RVT2+Sketch and 3DDA+Sketch
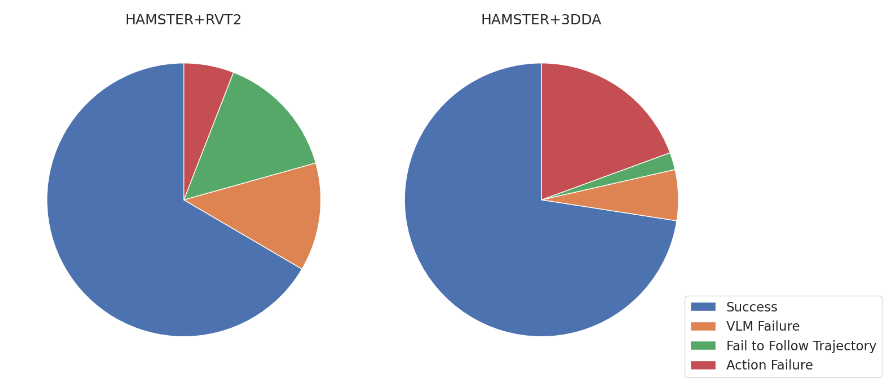
对于RVT,72%的失败源于底层模型未能遵循轨迹,而28%的失败是由于执行失败。相比之下,对于3DDA,只有10%的失败与轨迹遵循有关,90%的失败归因于执行失败。 我们推测,这种差异的产生是因为RVT纳入了一个重投影步骤,使得轨迹遵循变得复杂。相反,3DDA利用了一个视觉模块来处理原始的二维图像,简化了对轨迹的解读。
F SIMULATION EXPERIMENT DETAILS
我们的模拟实验是在“罗马斗兽场”(Colosseum,普马凯等人,2024年)上进行的。这是一个基于RLBench(詹姆斯等人,2020年)构建的模拟器,其中包含大量的视觉和任务变体,用于测试机器人操作策略的泛化性能(关于部分变体的可视化展示,见图16)。我们使用前置摄像头,并剔除了所有摄像头无法清晰拍摄到任务中物体的任务,最终在“罗马斗兽场”的20个任务中保留了14个(我们剔除了投篮入筐、清空抽屉、从冰箱取冰、移动衣架、打开抽屉、打开烤箱这些任务)。

“罗马斗兽场”模拟器中每个任务有100个训练情节,且不存在任何视觉变化情况,并针对每个变体进行25个评估情节的评估。除了仅使用前置摄像头而非多个摄像头之外,我们遵循相同的流程。在剔除了不存在视觉变化的变体(例如,物体摩擦力相关的变体)之后,我们在表3中报告了结果。
表3:HAMSTER在不同视觉变体下的模拟评估。我们在“罗马斗兽场”(普马凯等人,2024年)中的不同变体上对原始的3D扩散器智能体(3D Diffuser Actor)和HAMSTER进行了测试,结果发现,HAMSTER比3D扩散器智能体具有更有效的泛化能力。“Avg.”表示涵盖无变体情况在内的所有变体的平均值。

G DIFFERENT WAYS OF REPRESENTING 2D PATHS
为了研究二维路径上点的数量所产生的影响,我们训练视觉语言模型(VLM)来预测:
1. 使用RDP算法简化后的路径,该算法将短视距任务中的路径简化为3到5个点,这也是我们在论文中所使用的方法。在接下来的内容中,我们将这些路径记为“RDP”;
2. 用在路径上以相同步长采样得到的20个点来表示的路径,接下来我们将其记为“20p”。
在这两种方法中,我们都保留了夹爪执行打开或关闭操作时的点。 我们在RLBench的80个任务上对网络进行训练,每个任务有1000个情节,并在“合上罐子”这一任务的25个情节上对其进行测试。我们尝试使用VILA1.5-3B(记为“3B”)和VILA1.5-13B(记为“13B”)作为我们的主干模型。因此,在2个主干模型和2种路径表示设计的组合下,我们总共有4种组合情况。我们在图17中展示了结果。
图17:任务是拿起盖子,并将其正确颜色的那一面盖在罐子上。任务描述位于每张图片的左上角。轨迹从蓝色指向红色,其中蓝色圆圈表示夹爪应闭合的位置,红色圆圈表示夹爪应打开的位置。“GT”表示真实值,“3B”和“13B”分别表示VILA1.5-3B和VILA1.5-13B,“RDP”表示使用拉默-道格拉斯-普克(Ramer–Douglas–Peucker)算法简化后的路径,而“20p”表示用20个点表示的路径。
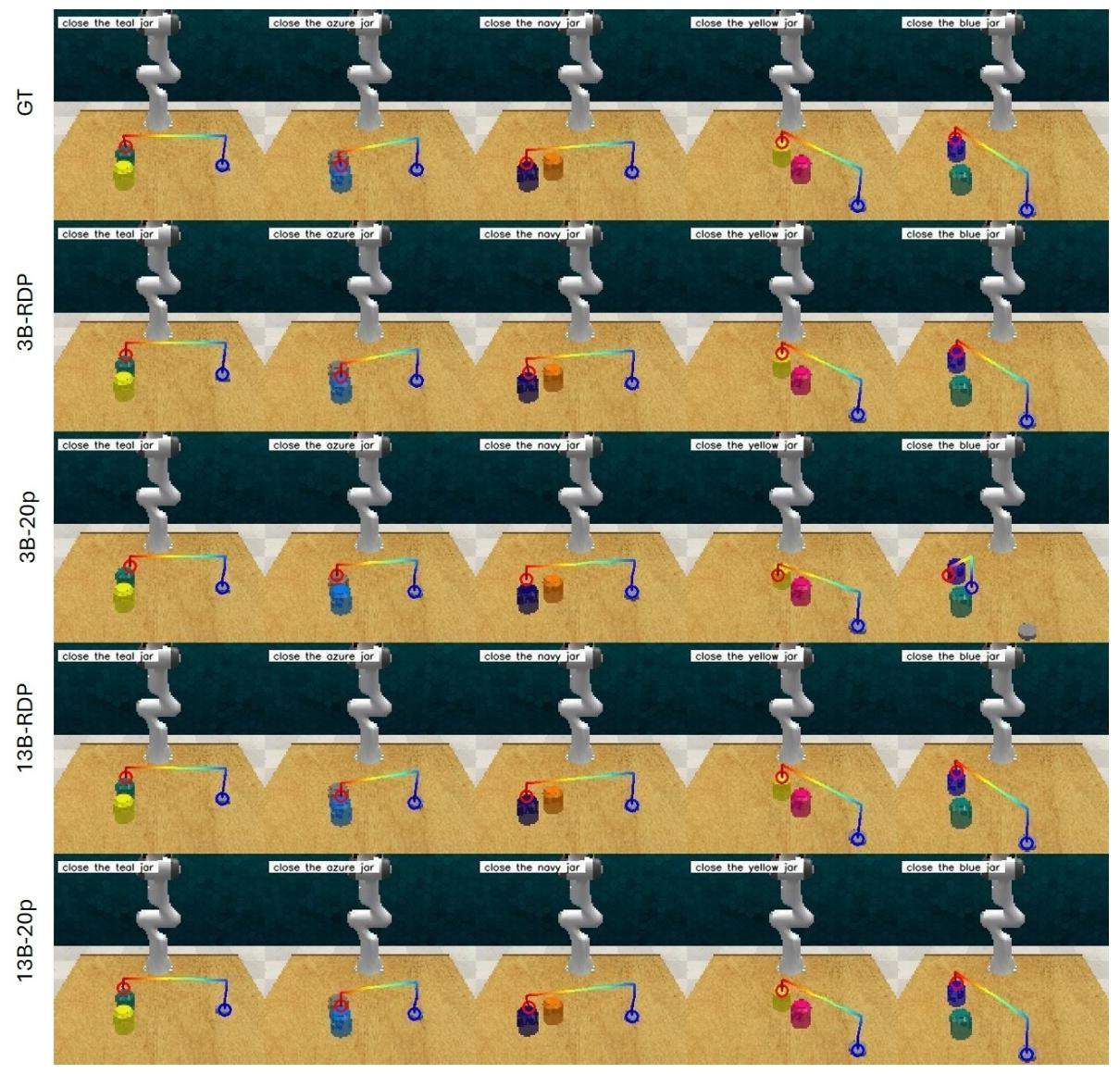
从这个结果我们可以看到,当使用较小的模型,如VILA1.5-3B时,使用RDP算法提取的点所表示的路径明显优于用固定的20个点表示的路径。当网络规模增大到13B的水平时,视觉语言模型(VLM)能够处理使用20个点的表示方式,并且两种路径表示方式都能很好地发挥作用。我们认为这是因为当使用RDP算法简化点时,我们通常只需要较少的点来表示路径,这有助于模型更加专注于预测夹爪打开/闭合点的准确位置。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









