






DITTO:使用世界模型的离线模仿学习
Branton DeMoss∗, Paul Duckworth, Jakob Foerster, Nick Hawes, Ingmar Posner 牛津大学
摘要
为了让模仿学习算法能够应对现实世界的挑战,它们必须能够处理高维观测、离线学习以及策略诱导的协变量偏移。我们提出了 DITTO,一种离线模仿学习算法,能够解决这三个问题。DITTO 在学习到的世界模型的潜在空间中优化一种新颖的距离度量:首先,我们在所有可用的轨迹数据上训练一个世界模型,然后,模仿代理从专家的起始状态在学习到的模型中展开,并因其在多个时间步上与专家数据集的潜在偏差而受到惩罚。我们使用标准的强化学习算法优化这种多步潜在偏差,这可以证明诱导出模仿学习,并在一系列 Atari 环境中实现了最先进的性能和样本效率,这些环境都是从像素级别进行训练,且没有任何在线环境访问。我们还将其他标准的模仿学习算法适应到世界模型设置中,并表明这显著提高了它们的性能。我们的结果表明,创造性地使用世界模型可以带来一个简单、稳健且高性能的策略学习框架。
1 引言
模仿学习(IL)是一种策略学习方法,它通过直接模仿专家示范者的行为来绕过奖励设定。最简单的 IL 类型是行为克隆(BC),它训练一个代理从观测中预测专家的动作,然后在测试时根据这些预测采取行动。然而,这种方法未能考虑到决策问题的顺序性,因为当前步骤的决策会影响后续看到的状态,打破了标准监督学习算法的 IID 假设。除非专家训练数据覆盖了整个状态空间,或者代理不犯任何错误,否则测试时看到的状态分布将与训练时不同。这种分布不匹配,或协变量偏移,会导致误差累积问题:最初的小预测误差会导致状态分布的小变化,进而导致更大的误差,最终完全偏离训练分布(Dean A. Pomerleau. Alvinn: An autonomous land vehicle in a neural network. In NeurIPS, 1989)[^1]。直观地说,代理没有学会在自己诱导的分布 its own
induced distribution 下行动。Ross & Bagnell(Stéphane Ross and J. Andrew Bagnell. Efficient reductions for imitation learning. In AISTATS, 2010)[^2]在其开创性工作中对此进行了形式化,他们给出了专家和学习者回报差异的紧密遗憾界限,对于 BC 来说,这个界限是关于剧集长度的二次方。
在 Ross 等人(Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In AISTATS, 2011)[^3]的后续工作中,他们表明如果代理在与专家的交互式在线环境中学习,可以实现关于遗憾的线性界限:由于代理是在自己的分布下接受专家纠正进行训练的,因此在测试时不存在分布不匹配。当在线学习是安全的且可以得到专家监督时,这种方法效果良好,但在许多现实世界的用例中,例如机器人技术,由于在线学习可能不安全、耗时或不可行,这种方法是不可行的。这抓住了模仿学习中的一个主要开放性挑战:一方面,我们希望生成与策略一致的数据以避免协变量偏移,但另一方面,我们可能由于安全或其他原因而无法进行在线学习。我们提出的算法 DITTO 以一种能够扩展到高维观测(如像素)的方式来解决这个离线模仿学习挑战。据我们所知,我们是第一个在模仿学习设置中解决这些 Atari 基准测试的,我们完全从像素级别进行离线训练,并且能够一致地恢复专家性能。 Ha & Schmidhuber(David R Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. ArXiv, abs/1809.01999, 2018)[^4]提出了一种两阶段策略学习方法,代理首先使用称为“世界模型”(WM)的循环神经网络学习预测环境动态,然后在 WM 中单独学习策略。这种方法是可取的,因为它能够在世界模型中进行离线的与策略一致的学习。类似的基于模型的学习方法最近在在线强化学习(Hafner et al., 2021)的相邻设置中取得了成功,并且在将仅在 WM 中训练的策略令人印象深刻地零样本迁移到物理机器人上(Wu et al., 2022 Daydreamer: World models for physical robot learning)。
在学习策略时,量化策略对未见输入的泛化能力是很重要的。然而,在模仿学习中存在一个概念上的困难,即衡量泛化性能:尽管我们可以通过在保留的专家状态 - 动作对上评估策略性能(例如通过测量预测精度)来衡量策略性能,但这未能反映我们在测试时应该期望的策略性能,因为我们在专家的分布下评估策略,而不是在它将要行动的分布下,即它自己诱导的分布。世界模型提供了解决这一问题的方法:给定一个学习到的动态模型,我们可以在专家起始状态下使用我们的学习策略进行展开,并在多个时间步上测量潜在空间中的偏差。这为我们提供了一个离线的、与策略一致的偏差度量,它捕捉了模仿学习决策问题的顺序性。这正是 DITTO 强大经验性能的关键所在,也是我们理论贡献的基础。为了确认我们算法的泛化特性,我们在具有外部奖励函数的环境中进行评估(模仿学习者无法访问该函数),并研究我们提出的偏差度量与外部奖励之间的关系。如图 2 所示,我们发现离线指标(如专家动作预测精度)并不能预测环境中的最终回报,而我们的在线潜在偏差度量则能够预测外部回报[^5]。
我们将上述观点结合起来,提出了一种新的模仿学习算法,称为梦中模仿(DITTO)。DITTO 以一种新颖的方式利用学习到的世界模型来诱导无奖励的模仿学习:首先,将专家轨迹映射到模型的潜在空间中;然后,在模型的潜在空间中从任意专家起始状态展开模仿策略。最后,我们直接使用在潜在空间中定义的一个简单、固定的距离函数,将在线展开与专家轨迹进行比较。我们的关键观点是,世界模型的潜在空间提供了一个自然的轨迹偏差度量,我们可以在这个度量上进行模仿学习,而无需任何中间的学习奖励模型或鉴别器。这使得我们能够在一种与领域无关的方式下进行稳健的模仿学习。利用这个偏差度量,DITTO 将离线模仿学习的挑战转化为在学习到的世界模型中进行在线强化学习的问题。 我们的主要贡献总结如下:
-
我们提出了 DITTO,这是一个新颖的模仿学习框架,它利用学习到的世界模型,将离线模仿转化为在模型潜在空间中的在线强化学习。
-
我们表明,由动态学习诱导的潜在空间为策略学习提供了一个自然且通用的偏差度量。我们展示的潜在距离函数比对抗模仿学习中使用的鉴别器更简单、更稳健,并且能够实现更优的策略学习性能。
-
我们证明 DITTO 显著优于标准的模仿学习基线。据我们所知,我们是第一个在研究的 Atari 基准测试中从像素级别完全离线地一致恢复专家性能的算法。
-
为了更全面地评估迄今为止尚未充分探索的从像素级别进行离线模仿学习的领域,我们提出了两个基线 IL 算法(BC、GAIL)到世界模型、离线设置的扩展(D-BC、D-GAIL)。
2 相关工作
2.1 模仿学习
模仿学习算法可以根据生成良好策略所需的资源集合进行分类。Ross 等人(Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In AISTATS, 2011)[^3]在在线交互式设置中给出了强大的理论和实证结果,该设置假设我们可以在真实环境中在线行动并学习,同时可以与专家策略进行交互式查询,例如让专家为学习者提供当前状态下的最优动作。后续工作逐渐放宽了生成良好策略所需的资源假设[^6]。Sasaki & Yamashina(Fumihiro Sasaki and Ryota Yamashina. Behavioral cloning from noisy demonstrations. In ICLR, 2021)[^7]表明,当从不完美的演示中学习时,如果满足专家次优性界限的约束,可以使用改进形式的 BC 恢复最优策略。Brantley 等人(Kianté Brantley, Wen Sun, and Mikael Henaff. Disagreement-regularized imitation learning. In ICLR, 2020)[^8]研究了在线、非交互式设置中的协变量偏移,并通过联合优化 BC 目标与一个新的策略集合不确定性成本,证明了一个近似线性的遗憾界限,该成本鼓励学习者返回并停留在专家支持的分布中。他们通过在 BC 目标中添加以下不确定性成本项来实现这一点:
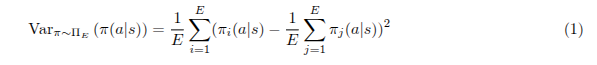
这个项衡量了在专家数据的不相交子集上训练的策略集合 ![]() 的总方差。他们使用标准的在线强化学习算法优化结合了 BC 和不确定性的目标,并表明这可以减轻协变量偏移[^9]。
的总方差。他们使用标准的在线强化学习算法优化结合了 BC 和不确定性的目标,并表明这可以减轻协变量偏移[^9]。
逆强化学习(IRL)可以通过首先从专家演示中学习一个奖励函数,使专家成为最优的,然后使用在线策略强化学习优化该奖励,从而实现比 BC 更好的性能。这个两步过程,包括第二步中的在线策略强化学习,有助于 IRL 方法减轻由于训练和测试分布不匹配而导致的协变量偏移。然而,学习到的奖励函数可能无法在专家状态分布之外泛化[^10]。
有一条研究路线将 IRL 视为偏差最小化:不是直接复制专家的动作,而是最小化专家和学习者状态分布之间的偏差:
![]()
其中![]() 是由 π 诱导的折扣状态 - 动作分布,
是由 π 诱导的折扣状态 - 动作分布,![]() 是概率分布之间的偏差度量。流行的 GAIL 算法(Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. In NIPS, 2016)[^11]构建了一个类似于 GANs(Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In NIPS, 2014)[^12]的极小化极大博弈,学习者策略 π 和一个鉴别器
是概率分布之间的偏差度量。流行的 GAIL 算法(Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. In NIPS, 2016)[^11]构建了一个类似于 GANs(Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In NIPS, 2014)[^12]的极小化极大博弈,学习者策略 π 和一个鉴别器 ![]() 之间进行对抗,鉴别器学习区分专家和学习者状态分布
之间进行对抗,鉴别器学习区分专家和学习者状态分布
![]()
这种表述最小化了专家和学习者策略之间的 Jensen-Shannon 偏差,并限制了代理和专家之间的预期回报差异。然而,Wang 等人(Ruohan Wang, Carlo Ciliberto, Pierluigi Vito Amadori, and Y. Demiris. Random expert distillation: Imitation learning via expert policy support estimation. In ICML, 2019)[^13]指出,对抗性奖励学习本质上是不稳定的,因为鉴别器总是被训练来惩罚学习者状态 - 动作分布,即使学习者已经收敛到专家策略。这一发现与早期工作(Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. In International Conference on Learning Representations, 2019)[^14]一致,该工作观察到鉴别器过拟合,需要提前停止以防止训练崩溃。多项工作报告称,在我们研究的像素级环境中,GAIL 无法处理高维观测(例如在连续动作设置中),这使得这种稀疏表述在实践中难以实现[^15]。
为了应对对抗性训练的问题,Wang 等人(Ruohan Wang, Carlo Ciliberto, Pierluigi Vito Amadori, and Y. Demiris. Random expert distillation: Imitation learning via expert policy support estimation. In ICML, 2019)[^13]和 Reddy 等人(Siddharth Reddy, Anca D. Dragan, and Sergey Levine. Sqil: Imitation learning via reinforcement learning with sparse rewards. In International Conference on Learning Representations, 2020)[^16]考虑将 IL 转化为基于内在奖励的强化学习
其中 ![]() 是专家数据集。虽然这种稀疏表述在连续动作设置中不实用,但他们表明,使用随机网络蒸馏(Yuri Burda, Harrison Edwards, Amos J. Storkey, and Oleg KoltovYuri Burda, Harrison Edwards, Amos J. Storkey, and Oleg Klimov. Exploration by random network distillation. ArXiv, abs/1810.12894, 2019)[^17]进行支持估计的内在奖励泛化,可以实现稳定的无对抗训练学习,其性能与 GAIL 相当。Ciosek(Kamil Ciosek. Imitation learning by reinforcement learning. In ICLR, 2022)[^18]表明,这种表述等价于在总变差距离下的偏差最小化,并得出了使用这种方法训练的学习者与专家在外部奖励上差异的界限。
是专家数据集。虽然这种稀疏表述在连续动作设置中不实用,但他们表明,使用随机网络蒸馏(Yuri Burda, Harrison Edwards, Amos J. Storkey, and Oleg KoltovYuri Burda, Harrison Edwards, Amos J. Storkey, and Oleg Klimov. Exploration by random network distillation. ArXiv, abs/1810.12894, 2019)[^17]进行支持估计的内在奖励泛化,可以实现稳定的无对抗训练学习,其性能与 GAIL 相当。Ciosek(Kamil Ciosek. Imitation learning by reinforcement learning. In ICLR, 2022)[^18]表明,这种表述等价于在总变差距离下的偏差最小化,并得出了使用这种方法训练的学习者与专家在外部奖励上差异的界限。
3 梦中模仿
我们在部分可观测马尔可夫决策过程(POMDP)中研究模仿学习,该过程具有离散的时间步和动作,以及由未知环境生成的高维观测。POMDP M 由元组 ![]() 组成,其中 s∈S 是状态空间,a∈A 是动作空间,
组成,其中 s∈S 是状态空间,a∈A 是动作空间,![]() 是观测空间,γ 是折扣因子,r=R(s,a) 是奖励函数。转移动态是马尔可夫的,由
是观测空间,γ 是折扣因子,r=R(s,a) 是奖励函数。转移动态是马尔可夫的,由 ![]() 给出。代理无法访问底层状态,只能接收由
给出。代理无法访问底层状态,只能接收由 ![]() 表示的观测。目标是最大化外部(环境)奖励的折扣总和
表示的观测。目标是最大化外部(环境)奖励的折扣总和 ![]() ,但代理无法访问这些奖励。 训练分为两部分:我们首先从记录的观测序列中学习世界模型,然后在世界模型中训练一个演员 - 评论家代理以模仿专家。世界模型的潜在动态定义了一个完全可观测的马尔可夫决策过程(MDP),因为模型状态
,但代理无法访问这些奖励。 训练分为两部分:我们首先从记录的观测序列中学习世界模型,然后在世界模型中训练一个演员 - 评论家代理以模仿专家。世界模型的潜在动态定义了一个完全可观测的马尔可夫决策过程(MDP),因为模型状态 ![]() 是马尔可夫的。基于模型的展开总是从专家演示中抽取的观测开始,并持续固定的时间步 H,即代理训练范围。如果代理能够匹配专家的潜在轨迹,则会获得奖励。
是马尔可夫的。基于模型的展开总是从专家演示中抽取的观测开始,并持续固定的时间步 H,即代理训练范围。如果代理能够匹配专家的潜在轨迹,则会获得奖励。
3.1 预备知识
我们证明了在世界模型中限制学习者 - 专家状态分布的偏差,也可以限制它们在实际环境中的回报差异,并将我们的方法与 IL 作为偏差最小化框架(Ghasemipour et al., 2019)联系起来[^19]。Rafailov 等人(Rafael Rafailov, Tianhe Yu, Aravind Rajeswaran, and Chelsea Finn. Visual adversarial imitation learning using variational models. ArXiv, abs/2107.08829, 2021)[^20]表明,对于一个学习到的动态模型 ![]() ,其与真实转移的总变差 total variation 有界,使得
,其与真实转移的总变差 total variation 有界,使得 ![]()
![]() ,且
,且![]() ,则
,则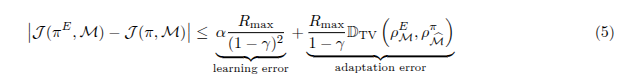
其中 ![]() 是策略 π 在 MDP M 中的预期回报,
是策略 π 在 MDP M 中的预期回报,![]() 是由世界模型诱导的“想象 MDP”。这意味着专家回报与学习者回报在真实环境中的差异被两个项限制:
是由世界模型诱导的“想象 MDP”。这意味着专家回报与学习者回报在真实环境中的差异被两个项限制:
1)与模型近似误差 α 成正比的项,原则上可以通过更多数据来减少;
2)模型领域适应误差项,它捕捉了一个在一种策略下训练的模型的泛化误差,并在另一种策略下部署。
Rafailov 等人(Rafael Rafailov, Tianhe Yu, Aravind Rajeswaran, and Chelsea Finn. Visual adversarial imitation learning using variational models. ArXiv, abs/2107.08829, 2021)[^20]还表明,限制潜在分布之间的偏差可以限制它们真实状态分布之间的偏差。形式上,给定一个潜在表示的转移历史 ![]() 和一个信念分布 belief distribution
和一个信念分布 belief distribution ![]() ,那么如果策略只基于潜在表示 zt,使得信念分布独立于当前动作
,那么如果策略只基于潜在表示 zt,使得信念分布独立于当前动作 ![]() ,则真实状态分布之间的偏差被潜在分布之间的偏差限制:
,则真实状态分布之间的偏差被潜在分布之间的偏差限制:
![]()
其中 ![]() 是一个通用的 f-偏差 f -divergence,例如 KL 或 TV。这个结果,连同公式 (5),表明在模型潜在空间中最小化偏差足以限制专家 - 学习者回报差异的期望值。
是一个通用的 f-偏差 f -divergence,例如 KL 或 TV。这个结果,连同公式 (5),表明在模型潜在空间中最小化偏差足以限制专家 - 学习者回报差异的期望值。
奖励
为了限制专家 - 学习者状态分布的偏差,先前的方法集中在稀疏指示函数奖励(Ciosek, 2022)[^18]或对抗性奖励学习(Ghasemipour et al., 2019)[^19]上。我们提出了一个新的表述,它奖励代理在多个时间步上匹配专家的潜在状态 - 动作对。具体来说,对于任意距离函数 d,代理状态 - 动作潜在 ![]() ,以及一组专家状态 - 动作潜在
,以及一组专家状态 - 动作潜在 ![]() :
:
![]()
任何形式的函数都奖励匹配代理的状态 - 动作对与专家的,如 Ciosek(2022)[^18]中所研究的。我们 formulation 中的主要区别在于我们在学习到的模型潜在状态上计算奖励,以及计算一个简单的平滑偏差,这意味着不需要精确匹配即可获得奖励。附录中的证明 A 展示了如何使这种宽松的奖励与 Ciosek(2022)[^18]中的理论结果兼容,从而获得一个精确的偏差界限。具体来说,我们证明了最大化这个奖励可以限制专家和学习者潜在状态分布之间的总变差,以及限制它们的外部奖励差异。
直观上,在学习者和专家之间匹配潜在状态比匹配观测更容易,因为从生成性世界模型训练中学习到的表示应该提供更丰富的状态相似性信号。在实践中,最小化 ![]() 可能计算成本较高,因此我们将目标 (7) 修改为精确匹配来自同一时间步的代理潜在状态与专家潜在状态,如图 1 所示。具体来说,我们从 DE 中随机抽取连续的专家潜在状态
可能计算成本较高,因此我们将目标 (7) 修改为精确匹配来自同一时间步的代理潜在状态与专家潜在状态,如图 1 所示。具体来说,我们从 DE 中随机抽取连续的专家潜在状态 ![]() ,并在世界模型中从相同的起始状态展开代理,得到一系列代理潜在状态
,并在世界模型中从相同的起始状态展开代理,得到一系列代理潜在状态 ![]() 。最后,我们在每个时间步 t 计算奖励如下:
。最后,我们在每个时间步 t 计算奖励如下:
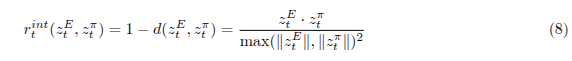
这种表述将我们的方法从分布匹配转变为模式寻找,因为专家频繁访问的状态在期望中将获得更大的奖励。我们发现,这种修改后的点积奖励在经验上优于 L2 和余弦相似度度量。

3.2 算法
数据集
世界模型训练可以使用任何质量的策略生成的数据集进行,因为模型只预测转移动态。转移数据集由 N 个episoid ![]() 观测序列 xt 和动作 at 组成:
观测序列 xt 和动作 at 组成:![]() 。
。
世界模型架构
我们采用了 Hafner 等人(Danijar Hafner, Timothy P. Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. ArXiv, abs/1912.01603, 2020)[^21]提出的架构,该架构由图像编码器、循环状态空间模型(RSSM)组成,后者学习转移动态,以及解码器,用于从紧凑的潜在状态重建观测。编码器使用卷积神经网络(CNN)生成表示,而解码器是转置 CNN。RSSM 预测长度为 T 的确定性循环状态序列![]() ,每个状态都用于参数化两个随机隐藏状态的分布。随机后验状态 zt 是当前观测 xt 和循环状态 ht 的函数,而随机先验状态
,每个状态都用于参数化两个随机隐藏状态的分布。随机后验状态 zt 是当前观测 xt 和循环状态 ht 的函数,而随机先验状态 ![]() 则在没有当前观测的情况下被训练以匹配后验。当前观测是从完整模型状态重建的,完整模型状态是确定性和随机状态的连接
则在没有当前观测的情况下被训练以匹配后验。当前观测是从完整模型状态重建的,完整模型状态是确定性和随机状态的连接![]() 。更多细节请参见附录中的模型架构部分。
。更多细节请参见附录中的模型架构部分。
代理架构
我们使用标准的随机演员 - 评论家架构,并带有熵奖励。演员观察世界模型中的马尔可夫循环状态,并产生其动作空间上的分布,我们从中采样以获取动作。评论家回归 λ-目标(Sutton & Barto, 2005)[^22],该目标是从内在奖励的总和以及在剧集范围内的价值引导计算得出的。更多细节请参见附录中的代理架构部分。
算法
学习过程分为两个阶段:首先,我们使用 ELBO 目标 11 在所有可用的演示数据上训练世界模型。接下来,我们将专家演示编码到世界模型的潜在空间中,并使用上述在线策略演员 - 评论家算法优化内在奖励 8,该奖励衡量代理和专家在潜在空间中的时间偏差。原则上,任何在线策略强化学习算法都可以替代演员 - 评论家。我们在算法 1 中描述了完整的程序。
4 实验
据我们所知,我们是第一个在研究的像素级环境中一致恢复专家性能的离线设置。先前的工作通常集中在改进行为克隆(Sasaki & Yamashina, 2021)[^7],或者研究允许一些在线交互的混合设置(Rafailov et al., 2021)[^20](Kidambi et al., 2021)[^23]。为了证明世界模型在模仿学习中的有效性,我们没有任何与真实环境的交互,也没有任何奖励信息进行训练。 最近的先进模仿学习算法(Sasaki & Yamashina, 2021)[^7](Kim et al., 2022)[^24](Kostrikov et al., 2019)[^25]大多仅在低维完美状态观测环境中进行评估。为了测试能够扩展到部分可观测、高维观测环境(例如从视频源进行机器人操作)的策略学习的世界模型的有效性,我们在具有挑战性的像素级环境中进行评估。我们在标准像素级 Atari 环境中进行测试,这些环境被最近的在线方法所考虑,例如 Brantley 等人(2020)[^8](Reddy 等人,2020)[^16]。我们使用来自 RL Baselines Zoo 仓库(Raffin, 2020)[^26]的强基线专家在 Atari 领域的一个子集上进行评估,以及一个像素级连续控制环境。
4.1 代理
为了测试我们算法的性能,我们将 DITTO 与标准基线方法行为克隆进行比较,并引入了两种在世界模型设置中的方法。
行为克隆
我们从像素级别端到端地训练一个 BC 模型,使用卷积神经网络架构。与先前研究 Atari 游戏中从像素级别进行行为克隆的工作(Hester 等人,2017)[^27](Zhang 等人,2020)[^28](Kanervisto 等人,2020)[^29]相比,我们的基线实现即使在使用低分数据进行训练的游戏中也取得了更强的结果。 梦想代理 我们将 GAIL(Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. In NIPS, 2016)[^11]和 BC 适应到世界模型设置中,分别称为 D-GAIL 和 D-BC。D-GAIL 和 D-BC 都接收世界模型的潜在状态而不是像素观测。D-BC 代理使用最大似然估计在潜在空间中对专家演示进行训练,并添加了一个熵正则化项,我们发现这稳定了学习:
![]()
D-GAIL 代理在世界模型中使用对抗目标(公式 3)进行在线策略训练。D-GAIL 代理使用与 DITTO 相同的演员 - 评论家公式优化其学习到的对抗奖励,如第 3.2 节所述。
D-GAIL 与 Rafailov 等人(2021)[^20]提出的 VMAIL 几乎完全相同,只是我们使用了 Dreamerv2(Danijar Hafner, Timothy P. Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. ArXiv, abs/2010.02193, 2021)[^30]的世界模型。我们使用固定范围 H=15 训练 DITTO 和 D-GAIL。
在测试时,基于模型的代理策略与世界模型编码器和 RSSM 组合,将高维观测转换为潜在表示。 我们实验中的所有基于模型的策略都使用相同的多层感知机(MLP)架构,以公平比较策略的表示能力,而 BC 代理则由堆叠的 CNN 和 MLP 架构参数化,该架构镜像了世界模型编码器加上代理策略。
我们发现 D-GAIL 比预期的要稳定得多,因为先前的工作(Reddy 等人,2020)[^16](Brantley 等人 Brantley et al., 2020)[^8]在从像素级别进行在线设置的模仿学习中报告了负面结果。这表明世界模型可能对在线情况下的表示学习也有益处,并且其他在线算法可以通过世界模型预训练,然后在潜在空间中进行策略训练来改进[^31]。
我们使用来自 RL Baselines3 Zoo(Raffin, 2020)[^26]的强 PPO 代理作为专家演示者,在 5 个 Atari 环境和一个连续控制环境中评估我们的算法和基线,使用 NE={4,8,15,30,60,125,250,500,1000} 个专家剧集来训练世界模型中的代理策略。
为了训练世界模型,我们从预训练的策略(PPO 或优势演员 - 评论家(A2C)(Mnih et al., 2016)[^32])中生成 1000 个剧集,该策略与 PPO 相比获得的奖励显著较低。
令人惊讶的是,我们发现 A2C 和 PPO 训练的世界模型表现相似,只有模仿剧集的质量影响了最终性能。我们假设这是因为 A2C 和 PPO 生成的数据集提供了对环境的良好覆盖。
看来只要数据集覆盖了状态分布,世界模型就可以从广泛类别的数据集中学习环境动态[^33]。数据生成策略的质量对于模仿学习是相关的,但对于动态学习似乎并不重要,除了覆盖[^34]。
图 2:我们在真实环境(BeamRider)中对比了不同算法在代理训练过程中的平均外部奖励(左),与两个模仿指标:潜在距离(中)和专家动作预测精度(右)。
潜在距离和精度都是在用于验证的保留专家轨迹上计算的。潜在距离定义为 Ld=1−rint。DITTO 明确最小化了这个量,并在真实环境中实现了最大的泛化性能。与专家完全一致将导致 Ld=0,但由于世界模型是随机的,这是不可能实现的。出人意料的是,专家动作预测精度与真实环境(即外部)性能呈负相关,而我们的潜在距离度量则可以预测环境中的性能[^35]。
4.2 结果
我们致力于推动模仿学习向现实世界的部署迈进,这需要处理高维观测和离线学习,如第 1 节所述。在离线设置中估计分布外的模仿性能尤其困难,因为根据定义,我们没有那里的专家数据,无法将我们的代理的行为与专家的行为进行比较。
这突显了标准离线模仿指标(如专家动作预测精度)的缺陷,这些指标仅告诉我们学习者在专家分布中的表现,可能无法预测学习者在其自身诱导分布下的表现[^36]。 图 2 展示了不同算法在训练过程中的真实环境性能,与两个模仿指标对比:潜在距离,我们将其作为一种更稳健的模仿泛化性能度量;以及专家动作预测精度,这是一个旨在捕捉泛化能力的标准模仿基准。DITTO 在其自身分布下实现了与专家的最低潜在距离。
我们发现,出人意料的是,动作预测精度与实际环境(即外部)性能呈负相关,而我们的潜在距离度量可以预测环境中的性能。这支持了我们的假设,即仅在专家分布中进行评估的指标不足以预测当部署到真实环境时模仿学习者的性能,因为它们忽略了决策问题的顺序性和随后的策略诱导协变量偏移[^37]。我们的结果表明,专家分布中的动作预测精度并不能衡量泛化性能[^38]。
图 3 绘制了 DITTO 与我们为离线设置提出的基于世界模型的基线和标准 BC 的性能对比。在 MsPacman 和 Qbert 中,大多数方法使用我们测试的最少数据量就能恢复专家性能,并且紧密聚集在一起,表明这些环境即使只有少量数据也能更容易地学习到良好的策略。
D-GAIL 在 MsPacman 中出现了两次对抗性崩溃,这比在 Atari 中从像素级别进行模仿学习的标准 GAIL 有所改进,后者在先前的研究中表现出均匀的对抗性崩溃(Reddy et al., 2020)[^16](Brantley et al., 2020)[^8]。
相比之下,DITTO 在所有测试环境中始终恢复或超过平均专家性能,并在样本效率和渐近性能方面与基线相匹配或优于基线[^39]。更多结果和消融实验可以在附录中找到。
5 结论
模仿学习算法必须处理离线学习、高维观测空间和协变量偏移,才能真正应用于现实世界的部署。在本文中,我们提出了 DITTO,这是一种使用世界模型解决这些问题的算法。DITTO 实现了比我们为离线设置引入的强基线更好的性能,并且在样本效率方面具有优势。DITTO 是第一个从像素级别解决这些困难的 Atari 环境的离线模仿学习算法[^40]。基于模型的方法通常被认为会导致泛化挑战,因为训练于学习模型中的代理可能会利用动态或学习奖励函数的泛化失败。相比之下,我们的表述鼓励学习者使用在模型潜在空间中定义的一个简单固定奖励函数返回到数据分布。通过在其自身分布下学习,DITTO 策略减轻了策略诱导的协变量偏移[^41]。解决高维部分可观测环境和离线学习的结合难题是将模仿学习扩展到现实世界挑战的关键[^42]。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









