






SENSEI:由基础模型引导的语义探索以学习多功能世界模型
Cansu Sancaktar*1 2 Christian Gumbsch*1 3 4 Andrii Zadaianchuk 1 5 Pavel Kolev 1 Georg Martius 1 2
*贡献相同 1 自主学习,图宾根大学 2 经验推断,马普智能系统研究所 3 神经认知建模,图宾根大学 4 认知与临床神经科学,德累斯顿工业大学 5VISLab,阿姆斯特丹大学。联系人:Cansu Sancaktar cansu.sancaktar@tue.mpg.de,Christian Gumbsch chris@gumbsch.de。预印本。正在审查中。1 项目网站:https://sites.google.com/view/sensei-paper
摘要 探索是强化学习(RL)的基石。内在动机试图将探索与基于外部任务的奖励解耦。然而,遵循信息增益等一般原则的既定内在动机方法,通常只能发现低层次的交互。相比之下,儿童的游戏表明,他们通过模仿或与照顾者互动来参与有意义的高层次行为。近期的研究集中在利用基础模型将这些语义偏见注入探索中。然而,这些方法通常依赖于不切实际的假设,例如语言嵌入环境或能够访问高层次动作。我们提出了SEmaNtically Sensible ExploratIon(SENSEI),这是一个为基于模型的RL代理赋予语义有意义行为内在动机的框架。SENSEI从视觉语言模型(VLM)注释中提炼出有趣性的奖励信号,使代理能够通过世界模型预测这些奖励。利用基于模型的RL,SENSEI训练一个探索策略,该策略联合最大化语义奖励和不确定性。我们证明了在机器人和类似视频游戏的模拟中,SENSEI能够从图像观察和低层次动作中发现各种有意义的行为。SENSEI为从基础模型反馈中学习提供了一个通用工具,随着VLM变得越来越强大,这是一个重要的研究方向[^1]。
1. 引言
实现人工代理的内在动机学习一直是人们的梦想,这使得代理能够从实验者手动设计和设置任务中解脱出来。因此,内在动机强化学习(RL)的目标是让代理能够高效且自主地探索其环境,构成类似于儿童好奇心驱动的自由游戏阶段。文献中提出了各种内在奖励定义,例如旨在实现状态空间覆盖(Unifying count-based exploration and intrinsic motivation[^2];#exploration: A study of count-based exploration for deep reinforcement learning[^3];Exploration by random network distillation[^4]),新颖性或回顾性惊讶(Curiosity-driven exploration by self-supervised prediction[^5];A possibility for implementing curiosity and boredom in model-building neural controllers[^6]),以及世界模型的信息增益(Self-supervised exploration via disagreement[^7];Planning to explore via self-supervised world models[^8];Curious exploration via structured world models yields zero-shot object manipulation[^9])。然而,当代理从零开始学习时,存在一个根本性问题:仅仅因为某事物是新颖的,并不一定意味着它包含对任何有意义的任务有用的或可推广的信息(A rational analysis of curiosity[^10])。
想象一个机器人面对一张有多个物体的桌子。机器人可以通过尝试穿越整个可操作空间或以不同速度敲击桌子来进行探索。相比之下,人类常识会主要关注与桌子上的物体或抽屉进行互动,因为潜在的任务分布可能主要围绕这些实体展开。
具有内在动机的代理在探索环境时面临一个鸡和蛋的问题:在尝试并体验到有趣的后果之前,你如何知道某事物是否有趣?这是代理在自由游戏中可以解锁的行为类型的瓶颈。我们认为,将人类先验知识融入探索可以缓解这一障碍。对于儿童的游戏,也提出了类似的论点。在生命的最初几年,儿童被照顾者包围,照顾者理想情况下会在他们探索环境时鼓励和强化他们。哲学家兼心理学家卡尔·格罗斯规定:“儿童有一种强烈的驱动力去观察长辈的活动,并将这些活动融入他们的游戏中”(What exactly is play, and why is it such a powerful vehicle for learning?[^11];The Play of Man[^12])。
在大型语言模型(LLM)时代的一个潜在解决方案是,利用语言作为文化传递者,将“人类对有趣事物的看法”(Bootstrap your own skills: Learning to solve new tasks with large language model guidance[^13])注入RL代理的探索中。LLM在大量主要由人类产生的数据上进行训练。因此,它们的响应可能反映了人类对什么有趣的偏好。然而,这一领域最突出的作品假设(1)语言基础的环境(Guiding pretraining in reinforcement learning with large language models[^14];ELL M: Efficient Language Learning for Mobile Agents[^15];MOTIF: Intrinsic motivation from artificial intelligence feedback[^16]),(2)离线数据集具有穷尽的状态空间覆盖(MOTIF: Intrinsic motivation from artificial intelligence feedback[^16]),或(3)能够访问高层次动作(Bootstrap your own skills: Learning to solve new tasks with large language model guidance[^13];ELL M: Efficient Language Learning for Mobile Agents[^15])。这些假设仍然与当前实体代理的现实脱节,例如在机器人技术中,它们没有完美的状态或事件描述器、预先存在的离线数据集或稳健的高层次动作。此外,这些方法中没有任何一种学习内部的“有趣性”模型。因此,它们依赖于LLM或一个提炼的模块来持续指导它们的探索,并且无法将这种知识转移到新状态。
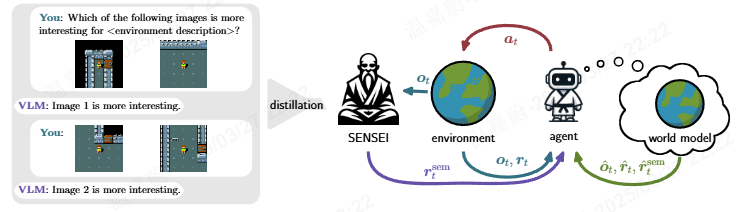
在本工作中,我们提出了SEmaNtically Sensible ExploratIon(SENSEI),这是一个用于基于模型的RL代理的视觉语言模型(VLM)引导探索框架,如图1所示。SENSEI从环境的简短描述和通过自我监督探索收集的观察数据集(例如图像)开始。VLM被提示对观察结果进行成对比较,以确定它们的有趣性,并将得到的排名提炼成奖励函数。当代理探索其环境时,它从SENSEI接收以语义为基础的探索奖励。它通过其学习的世界模型学习预测这种探索信号,对应于“有趣性”的内部模型。代理通过旨在预测有趣性高的状态并随后扩展到不确定情况的探索策略来改进其探索策略。
我们的主要贡献如下:
-
我们提出了SENSEI,这是一个带有世界模型的基础模型引导探索框架。
-
我们证明了SENSEI能够在几乎没有先决条件的情况下探索丰富且语义上有意义的行为。
-
我们证明了通过SENSEI学习的多功能世界模型能够快速学习下游任务。
图1。Sensei概述:(a)在预训练期间,我们促使VLM从环境中对其兴趣进行比较(例如图像)。我们将此排名提炼成为了探索的奖励函数(Sensei) (b)探索代理不仅从与环境的互动中获得观察结果(
)和奖励(
),而且还从Sensei获得了语义探索奖励(RSEM T)。 (c)代理从其经验中学习了世界模型,以判断状态的兴趣(
),而无需查询Sensei
2. 方法
我们考虑一个代理与部分可观察马尔可夫决策过程交互的设置。在每个时间点t,代理执行一个动作at ∈ A,并接收到一个观察结果ot ∈ O,该观察结果由图像和可能的其他信息组成。我们假设环境中存在一个或多个任务,对应于任务奖励![]() 。然而,在无任务探索期间,代理应选择与其行为无关的任务奖励。
。然而,在无任务探索期间,代理应选择与其行为无关的任务奖励。
我们假设SENSEI从一个初始数据集![]() 开始,该数据集是通过以信息增益为内在奖励的自我监督探索收集的(Planning to explore via self-supervised world models[^8]),因此不依赖于预先存在的专家数据集。SENSEI可以访问一个预训练的VLM,并且会收到环境的简短描述,该描述可以来自人类专家,也可以由VLM根据Dinit中的一些观察结果生成。在无任务探索之前,SENSEI从VLM注释中提炼出语义探索奖励函数(第2.1节)。在探索过程中,SENSEI学习一个世界模型(第2.2节),并通过基于模型的RL优化探索策略(第2.3节)。
开始,该数据集是通过以信息增益为内在奖励的自我监督探索收集的(Planning to explore via self-supervised world models[^8]),因此不依赖于预先存在的专家数据集。SENSEI可以访问一个预训练的VLM,并且会收到环境的简短描述,该描述可以来自人类专家,也可以由VLM根据Dinit中的一些观察结果生成。在无任务探索之前,SENSEI从VLM注释中提炼出语义探索奖励函数(第2.1节)。在探索过程中,SENSEI学习一个世界模型(第2.2节),并通过基于模型的RL优化探索策略(第2.3节)。
2.1. 奖励函数提炼:激发你的SENSEI
在无任务探索之前,SENSEI需要根据预训练VLM的偏好提炼出具有可学习参数ψ的基于语义的内在奖励函数![]() 。尽管SENSEI的整体框架对具体的提炼方法是不可知的,但我们选择使用基于视觉的MOTIF扩展(MOTIF: Intrinsic motivation from artificial intelligence feedback[^16];如图2a所示),我们称之为VLM-MOTIF[^17]。
。尽管SENSEI的整体框架对具体的提炼方法是不可知的,但我们选择使用基于视觉的MOTIF扩展(MOTIF: Intrinsic motivation from artificial intelligence feedback[^16];如图2a所示),我们称之为VLM-MOTIF[^17]。
MOTIF由两个阶段组成。在第一个数据集注释阶段,使用预训练的基础模型对观察结果进行成对比较,创建偏好数据集。为此,我们提示VLM提供环境描述和来自Dinit的观察结果对,询问VLM认为哪张图片更有趣。注释函数由![]() 给出,其中O是观察结果空间,
给出,其中O是观察结果空间,![]() 是关于第一个、第二个或无观察结果的选择空间。在奖励训练阶段,使用基于偏好的强化学习(A survey of preference-based reinforcement learning methods[^18])的标准技术从VLM偏好中推导出奖励函数。在偏好对数据集上最小化交叉熵损失函数,以学习基于语义的奖励模型
是关于第一个、第二个或无观察结果的选择空间。在奖励训练阶段,使用基于偏好的强化学习(A survey of preference-based reinforcement learning methods[^18])的标准技术从VLM偏好中推导出奖励函数。在偏好对数据集上最小化交叉熵损失函数,以学习基于语义的奖励模型![]() R。我们在代理与环境互动时使用最终的语义奖励函数
R。我们在代理与环境互动时使用最终的语义奖励函数![]() :代理在执行动作at后不仅接收到观察结果ot和奖励rt,还会接收到基于语义的探索奖励
:代理在执行动作at后不仅接收到观察结果ot和奖励rt,还会接收到基于语义的探索奖励![]() (见图1,中心)。
(见图1,中心)。
图2。Sensei中的内在奖励:(a)在无任务探索之前,我们提示GPT-4在某个环境中比较图像。从结果排名中,我们使用VLM-MOTIF提炼奖励函数Rψ。 (b)后来,代理从无任务探索中学习了RSSM世界模型。从每个模型状态中,代理可以预测不同的内在奖励来源,即基于认知的不确定性奖励和我们的蒸馏语义奖励
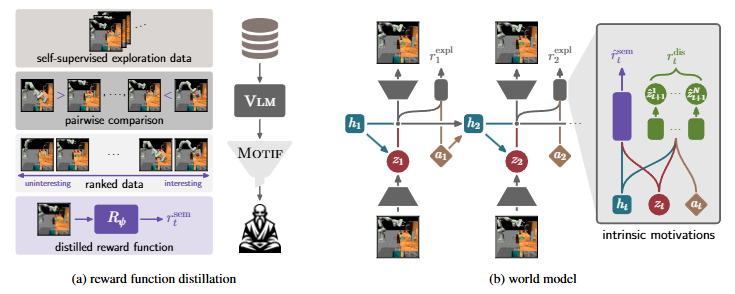
2.2. 世界模型:让你的SENSEI畅想
我们假设一个基于模型的设置,即代理从其互动中学习世界模型。遵循DreamerV3(Hafner等人,2023[^19]),我们用循环状态空间模型(RSSM)(Hafner等人,2019b[^20])实现世界模型。
具有可学习参数ϕ的RSSM计算如下:
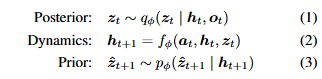
简而言之,RSSM通过两个潜在状态编码所有互动,即随机状态zt和确定性记忆ht。在每个时间点t,RSSM从后验分布![]() 中采样一个新的随机状态zt,该分布由当前确定性状态ht和新的观察结果ot计算得出(公式1)。RSSM根据动作at和之前的潜在状态更新其确定性记忆ht+1(公式2)。然后,模型预测下一个随机状态zt+1(公式3)。一旦接收到新的观察结果ot+1,就会计算下一个后验分布
中采样一个新的随机状态zt,该分布由当前确定性状态ht和新的观察结果ot计算得出(公式1)。RSSM根据动作at和之前的潜在状态更新其确定性记忆ht+1(公式2)。然后,模型预测下一个随机状态zt+1(公式3)。一旦接收到新的观察结果ot+1,就会计算下一个后验分布![]() ,并重复该过程。
,并重复该过程。
除了在潜在状态内编码动态外,RSSM还通过输出头![]() 从其潜在状态重建外部量
从其潜在状态重建外部量:
![]()
其中![]() 。DreamerV3(Hafner等人,2023[^19])的RSSM重建观察结果ot、剧集延续ct和奖励rt。对于SENSEI,我们还额外预测语义探索奖励
。DreamerV3(Hafner等人,2023[^19])的RSSM重建观察结果ot、剧集延续ct和奖励rt。对于SENSEI,我们还额外预测语义探索奖励![]() 。世界模型通过端到端训练联合优化证据下界。
。世界模型通过端到端训练联合优化证据下界。
因此,我们的世界模型学会预测状态的语义有趣性semantic interestingness ![]() (见图1,右侧)。我们可以仅基于这一信号进行探索。然而,我们(1)预计在优化这一信号时会面临许多局部最优值,且(2)我们不想仅探索一组固定的行为,而是确保代理能够探索既有趣又新颖的状态。为克服这一限制,Klissarov等人(2023[^16])对
(见图1,右侧)。我们可以仅基于这一信号进行探索。然而,我们(1)预计在优化这一信号时会面临许多局部最优值,且(2)我们不想仅探索一组固定的行为,而是确保代理能够探索既有趣又新颖的状态。为克服这一限制,Klissarov等人(2023[^16])对![]() 进行后处理,并通过剧集事件消息计数进行归一化 episodic event message counts。由于我们不假设存在可计数事件的真实标题,我们选择将语义奖励信号与认识不确定性 epistemic uncertainty 相结合,而认识不确定性已被证明是基于模型探索的有效目标(Sekar等人,2020[^8];Pathak等人,2017[^5];Sancaktar等人,2022[^9])。遵循Plan2Explore(Sekar等人,2020[^8]),我们训练一个包含N个模型的集成,其权重为
进行后处理,并通过剧集事件消息计数进行归一化 episodic event message counts。由于我们不假设存在可计数事件的真实标题,我们选择将语义奖励信号与认识不确定性 epistemic uncertainty 相结合,而认识不确定性已被证明是基于模型探索的有效目标(Sekar等人,2020[^8];Pathak等人,2017[^5];Sancaktar等人,2022[^9])。遵循Plan2Explore(Sekar等人,2020[^8]),我们训练一个包含N个模型的集成,其权重为![]() ,以预测下一个随机潜在状态:
,以预测下一个随机潜在状态:
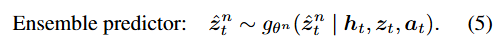
我们通过计算集成预测的方差,并在潜在状态维度J上取平均值,量化认识不确定性为集合预测的不一致性![]() :
:
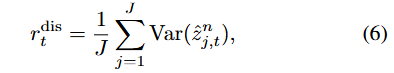
因此,模型学会为状态-动作对预测两个内在奖励![]() (见图2b)。
(见图2b)。
2.3. 探索策略:用SENSEI去探索
我们可以使用两个内在奖励信号的加权和,例如![]() ,作为优化探索策略的总体奖励
,作为优化探索策略的总体奖励![]() 。然而,理想情况下,两个信号的权重应根据情况而定。在无趣的状态中,我们希望代理主要追求有趣性(通过
。然而,理想情况下,两个信号的权重应根据情况而定。在无趣的状态中,我们希望代理主要追求有趣性(通过![]() )。然而,一旦代理发现了一个有趣的状态,我们希望代理能够拓展并发现新的行为(通过
)。然而,一旦代理发现了一个有趣的状态,我们希望代理能够拓展并发现新的行为(通过![]() )。这遵循了Go-Explore(Ecoffet等人,2021[^21])的原则,即代理应首先到达一个子目标,然后从那里开始探索(见图3)。我们通过自适应阈值参数
)。这遵循了Go-Explore(Ecoffet等人,2021[^21])的原则,即代理应首先到达一个子目标,然后从那里开始探索(见图3)。我们通过自适应阈值参数![]() 来实现这一点,其中
来实现这一点,其中![]() ,其值取决于以下切换标准:
,其值取决于以下切换标准:
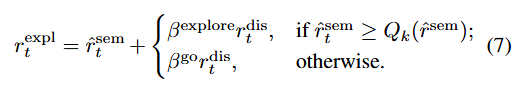
这里Qk表示![]() 的第k百分位数,我们通过移动平均法来估计。因此,在达到一定水平的
的第k百分位数,我们通过移动平均法来估计。因此,在达到一定水平的![]() 之前,探索奖励主要旨在最大化有趣性。一旦超过这一阈值,探索更倾向于支持不确定性最大化的行为。一旦代理进入一个有趣性较低的状态(rsem < Qk),SENSEI会切换回专注于语义有趣性。两个权衡因子βgo和βexplore以及百分位数k均为超参数。有关这种适应和超参数的更多细节,请参见补充材料B。我们基于rexpl t使用DreamerV3(Hafner等人,2023[^19])学习探索策略。
之前,探索奖励主要旨在最大化有趣性。一旦超过这一阈值,探索更倾向于支持不确定性最大化的行为。一旦代理进入一个有趣性较低的状态(rsem < Qk),SENSEI会切换回专注于语义有趣性。两个权衡因子βgo和βexplore以及百分位数k均为超参数。有关这种适应和超参数的更多细节,请参见补充材料B。我们基于rexpl t使用DreamerV3(Hafner等人,2023[^19])学习探索策略。
3. 相关工作
内在奖励应用于两种场景:一是在直接奖励稀疏的任务中促进探索;二是在任务不可知的设置中,帮助收集多样化的数据。文献中提出了许多不同的探索奖励信号(Intrinsically Motivated Learning in Natural and Artificial Systems[^22]),例如预测误差(A possibility for implementing curiosity and boredom in model-building neural controllers[^6];Curiosity-driven exploration by self-supervised prediction[^5];Active world model learning with progress curiosity[^23])、贝叶斯惊讶(Reinforcement driven information acquisition in non-deterministic environments[^24];Sparse reward exploration via novelty search and emitters[^26];Control What You Can: Intrinsically motivated task-planning agent[^25])、学习进步(A possibility for implementing curiosity and boredom in model-building neural controllers[^6];CURIOUS: Intrinsically motivated modular multi-goal reinforcement learning[^27];Control What You Can: Intrinsically motivated task-planning agent[^25])、赋能(Empowerment: a universal agent-centric measure of control[^28];Variational information maximisation for intrinsically motivated reinforcement learning[^29])、状态空间覆盖指标(Unifying count-based exploration and intrinsic motivation[^2];#exploration: A study of count-based exploration for deep reinforcement learning[^3];Exploration by random network distillation[^4])和规律性(Regularity as intrinsic reward for free play[^30])。虽然这些目标在低维观察中效果良好,但在高维图像观察中应用起来具有挑战性。在这里,替代方法是采用低维目标空间(CURIOUS: Intrinsically motivated modular multi-goal reinforcement learning[^27];Asymmetric selfplay for automatic goal discovery in robotic manipulation[^31];Visual reinforcement learning with imagined goals[^32];Skew-fit: State-covering self-supervised reinforcement learning[^33];Selfsupervised visual reinforcement learning with objectcentric representations[^34];Discovering and achieving goals via world models[^35])或学习潜在世界模型(Dream to control: Learning behaviors by latent imagination[^36];Learning latent dynamics for planning from pixels[^19];Learning hierarchical world models with adaptive temporal abstractions from discrete latent dynamics[^37]),这些模型可用于基于模型的探索(Self-supervised exploration via disagreement[^7];Planning to explore via self-supervised world models[^8])。特别是,Plan2Explore(Planning to explore via self-supervised world models[^8])使用潜在空间动态预测的集成不一致性作为内在奖励。虽然这是一种非常通用的探索策略,但在需要语义上有意义或目标导向行为(Principles of object perception[^38])的更具挑战性的环境中,它可能会受到限制。
利用基础模型进行探索:近期大型语言模型(LLM)的上下文学习改进为探索开辟了新的途径,利用人类对有趣事物的偏见进行探索(MOTIF: Intrinsic motivation from artificial intelligence feedback[^16];Guiding pretraining in reinforcement learning with large language models[^15];Bootstrap your own skills: Learning to solve new tasks with large language model guidance[^13])以及技能学习(Language as a cognitive tool to imagine goals in curiosity driven exploration[^39];Augmenting autotelic agents with large language models[^40];ELL M: Efficient Language Learning for Mobile Agents[^41])。MOTIF(MOTIF: Intrinsic motivation from artificial intelligence feedback[^16])利用LLM通过比较事件标题对来推导内在奖励,在复杂的NetHack游戏(The nethack learning environment[^42])中展示了其有效性。同样,ELL M(Guiding pretraining in reinforcement learning with large language models[^15])利用LLM引导RL代理朝着基于代理当前状态描述的有意义目标前进,在Crafter环境(Benchmarking the spectrum of agent capabilities[^43])中展示了改进的任务覆盖。此外,OMNI(OMNI: Open-endedness via models of human notions of interestingness[^44])引入了一种新方法,通过使用LLM建模人类对有趣事物的看法来优先考虑任务。因此,OMNI专注于不仅可学习而且普遍有趣的任务。LAMP(Language reward modulation for pretraining reinforcement learning[^45])提出使用VLM进行奖励调制。首先,使用LLM生成一组潜在任务,然后LAMP使用VLM为这些任务生成奖励,以学习基于语言条件的策略。然后,该策略使用实际任务奖励进行微调。
通过VLM进行奖励塑形:大多数依赖VLM作为奖励源的作品试图解决强化学习中的奖励规范问题。在这些作品中,任务被假设为用语言标题(Vision-language models as a source of rewards[^46];Can foundation models perform zero-shot task specification for robot manipulation?[^47];Roboclip: one demonstration is enough to learn robot policies[^48])描述,目标图像(Vision-language models as a source of rewards[^46])或视频演示(Roboclip: one demonstration is enough to learn robot policies[^48])。特别是,RL-VLM-F(RL-VLM-F: Reinforcement learning from vision language foundation model feedback[^49])使用与SENSEI非常相似的设置。通过VLM比较初始rollout的图像对来提炼奖励函数。然而,与我们的工作不同的是,VLM明确地以任务为提示,而我们提炼出的是环境特定但通用的探索奖励。此外,SENSEI假设基于模型的设置来学习世界模型,而不是优化基于任务的策略。
4. 实验结果
我们的实验旨在实证评估以下问题:
-
从VLM注释中提炼的奖励函数Rψ是否鼓励有趣的行为?
-
SENSEI是否能够在无任务探索期间发现语义上有意义的行为?
-
通过探索学习的世界模型是否适合后续高效解决下游任务?
我们通过以下方式回答这些问题:(1)通过展示从VLM-Motif获得的语义奖励反映了环境中的有趣事件;(2)定量展示SENSEI在无任务探索期间导致更具互动性的行为;(3)使用学习到的世界模型成功训练基于任务的策略。我们使用了两种根本不同的环境类型:
MiniHack(Minihack the planet: A sandbox for open-ended reinforcement learning research[^50])是一个基于NetHack(The nethack learning environment[^42])设计RL任务的沙盒。在MiniHack中,代理需要通过与环境进行有意义的互动来导航地牢,例如用钥匙打开门。我们测试了两个任务:在一个大房间里获取钥匙以解锁一个小房间并找到出口(KeyRoom-S15)或在迷宫般的房间中获取钥匙以打开宝箱(KeyChest)。MiniHack使用离散动作。作为观察结果,我们使用围绕代理的像素基础、以自我为中心的视图以及一个二进制标志,指示是否捡起了钥匙(详细信息见补充材料C.2)。
Robodesk(Robodesk: A multi-task reinforcement learning benchmark[^51])是一个多任务RL基准测试,其中模拟的机械臂可以与桌上的各种物体互动,包括按钮、两种类型的积木、球、滑动柜子、抽屉和垃圾桶。对于不同的物体,存在不同的任务,例如打开抽屉。Robodesk使用像素基础的观察结果和连续动作。为了处理遮挡问题,我们在VLM注释中使用了两个摄像头角度的图像,但仅将一个摄像头角度的图像作为代理的输入(详细信息见补充材料C.1)。
我们使用Plan2Explore(Planning to explore via self-supervised world models[^8])收集初始数据集Dinit,这是像素基础观察的最新探索方法。我们在MiniHack中收集了500k步的探索数据,在Robodesk中收集了1M步的探索数据。对于数据注释,我们使用了GPT-4(详细信息见补充材料C.3)。
4.1. SENSEI的奖励函数
我们展示了从VLM-Motif提炼出的语义奖励函数Rψ为MiniHack和Robodesk中的示例序列分配语义探索奖励rsem t ,如图4所示。在MiniHack中,我们清楚地看到在重要事件发生时rsem t 有跳跃。KeyRoom-S15和KeyChest中的第2帧和第3帧分别是捡起钥匙之前的瞬间。之后,当代理拿着钥匙到达门或宝箱时(KeyRoom-S15中的第3帧和KeyChest中的第4帧和第5帧),rsem t 进一步增加。对于Robodesk,我们看到当机器人与物体互动时,例如打开抽屉和推动积木时,rsem t 也会增加。
4.2. 无任务探索
4.2.1. MiniHack
我们在MiniHack的两个任务中量化了SENSEI在无任务探索期间发现的互动。图5展示了与任务相关事件的平均互动次数。与Plan2Explore相比,SENSEI更专注于语义上有意义的互动,例如捡起钥匙、打开锁着的门或找到带有钥匙的宝箱。因此,SENSEI在无任务探索期间比Plan2Explore更频繁地完成这两个任务,这从收集到的更高奖励数量中可以看出。我们相信这表明SENSEI非常适合在这些环境中进行初始的无任务探索,能够发现对解决下游任务至关重要的状态空间区域。
信息增益对SENSEI是否重要?我们展示了仅使用语义奖励rsem t 进行探索的结果,这对应于没有信息增益奖励rdis t (β = 0)的SENSEI。在这个VLM-MOTIF消融实验中,我们强调了信息增益目标的重要性。仅针对语义奖励rsem t 进行优化可能会导致代理陷入局部最优,阻碍进一步的探索。例如在KeyRoom任务中,仅使用VLM-MOTIF的代理经常捡起钥匙。然而,在捡起钥匙后,它未能充分探索房间以找到并打开门并到达出口,这从图5中的互动指标中可以看出。
对于KeyChest任务,我们也观察到了类似的情况:尽管仅使用VLM-MOTIF的代理在捡起钥匙后经常到达宝箱,但它收集到的奖励比SENSEI少得多。为了完成任务,代理需要用钥匙打开宝箱。然而,VLM-MOTIF代理只是在宝箱周围徘徊。因为带着钥匙到达宝箱是一个“有趣”的状态,且打开宝箱会立即结束剧集,所以代理没有真正的动力去探索打开宝箱的动作。这个消融实验表明,结合新颖性和实用性是持续推动体验边界的关键。
4.2.2. Robodesk
接下来,我们分析了在具有挑战性的视觉控制套件Robodesk中的探索情况。在这里,我们将SENSEI与Plan2Explore和随机网络蒸馏(RND[^4],Burda等人,2019)进行了比较,RND是一种使用随机图像嵌入的预测误差作为内在奖励以最大化状态空间覆盖的强大的无模型探索方法。图6展示了三种方法在探索期间与各个物体的平均互动次数。平均而言,SENSEI与大多数可用物体的互动次数都超过了基线方法。因此,在大多数任务中,SENSEI在探索期间收到的任务奖励都比Plan2Explore或RND多(详细信息见补充材料D.3)。从定性角度来看,Plan2Explore主要执行手臂伸展动作[^3],而RND主要在屏幕中央移动手臂,大部分时间都在击打按钮(因为它们也位于桌子中央),偶尔也会击打物体。
因此,我们的语义探索奖励似乎比纯认识不确定性基础的探索更能引导出有意义的行为,即使在低层次运动控制的机器人环境中也是如此。
人类专家提供的环境描述对SENSEI是否必要?在之前的SENSEI实验中,我们在VLM注释的提示中提供了简短的环境描述。我们研究了SENSEI是否依赖于这种外部描述,并将其与使用更通用的零知识提示策略的SENSEI版本(称为SENSEI GENERAL)进行了比较。SENSEI GENERAL首先提示VLM根据环境图像生成环境描述,并将生成的答案作为上下文用于注释偏好数据集(详细信息见补充材料C.3.2)。如图6所示,SENSEI GENERAL与相关物体的互动次数大致与SENSEI相当,在整体物体互动次数上超过了Plan2Explore和RND。因此,将外部环境知识注入提示并非必要,这一步可以完全自动化。这进一步巩固了我们方法的通用性。
消融实验 我们进行了消融实验,以了解(1)VLM的噪声注释对SENSEI的影响与理想标注者相比如何,(2)初始数据集的行为丰富度如何影响SENSEI的性能(见补充材料图12),以及(3)消融我们的Go-Explore切换策略。我们观察到,随着VLM的性能提升,确实可以从SENSEI中获得更多收益,且更丰富的探索数据有助于SENSEI更快地启动。更多详细信息请参见补充材料D.2。我们还在补充材料D.6中展示了我们的Go-Explore切换策略在超参数敏感性方面的鲁棒性,与固定权重的SENSEI变体(语义奖励和不一致性奖励的权重固定)进行了比较。
4.3. 快速下游任务学习
我们假设从更丰富的探索中学习到的世界模型将使基于模型的RL代理能够快速学会解决新的下游任务。我们在MiniHack中通过运行DreamerV3(Hafner等人,2023[^19])来验证这一假设,使用之前探索的世界模型来学习新的基于任务的策略。为此,我们使用初始500k步探索期间预训练的世界模型来初始化DreamerV3(见第4.2节)。我们将从无任务探索中使用SENSEI或Plan2Explore学习到的世界模型进行了比较。此外,我们还比较了从头开始运行DreamerV3和训练近端策略优化(PPO[^52],Schulman等人,2017)的情况,PPO是一种最先进的无模型基线方法。
图7展示了任务策略在训练过程中的性能。从SENSEI学习到的预探索世界模型使代理能够比所有其他基线更快地学会解决任务。与Plan2Explore相比,SENSEI更多地分配资源来探索环境中的相关动态,例如更多地打开宝箱,从而为策略优化提供了更合适的世界模型。与Plan2Explore不同,SENSEI的无任务探索并没有始终如一地优于从头开始使用DreamerV3学习任务策略。在KeyRoom任务中,无模型基线PPO需要超过20M步才能一致地解决任务(完整的PPO曲线见补充材料图11)。因此,在这个任务中,SENSEI的性能大约比PPO高出两个数量级。这展示了我们方法的改进样本效率:结合基础模型引导的探索和基于模型的强化学习。在KeyChest任务中,无模型基线PPO在训练早期就显示出任务的成功,但平均而言,它需要更长时间才能可靠地学会解决任务。
5. 讨论
我们介绍了SENSEI,这是一个通过基础模型引导基于模型的代理探索的框架。SENSEI从之前生成的玩耍数据中引导出一个有趣性的模型。在这个数据集上,SENSEI提示VLM比较图像的有趣性,并提炼出一个语义奖励函数。SENSEI通过基于模型的强化学习使用两种内在奖励来学习探索策略:(1)尝试达到具有高语义有趣性的状态,以及(2)从这些状态分支出来以最大化认识不确定性。我们证明了在MiniHack的视频游戏环境和机器人模拟中,这种策略导致了更有意义的互动,例如用钥匙打开宝箱或操纵桌上的物体。在这两种环境中,SENSEI都比最先进的探索方法Plan2Explore(Sekar等人,2020[^8])积累了更多的奖励,因为它已经在探索过程中解决了人类设计的稀疏奖励任务。
内部有趣性模型 与其他基础模型引导探索的方法(Klissarov等人,2023[^16];Wang等人,2024[^49])不同,SENSEI将语义探索与世界模型学习相结合,从而学习了一个内部的“有趣性”模型。当使用世界模型时,这是一个合理的设计选择(详细信息见补充材料A.3)。先前的MOTIF变体(Klissarov等人,2023[^16];Wang等人,2024[^49])需要完整的观察结果来计算基于基础模型的奖励。经过训练后,SENSEI可以从其潜在状态中预测语义奖励,因此也可以评估想象中的、假设性的状态。正如我们的实验所展示的,这可以显著加快策略学习的速度,因为VLM引导和基于模型的强化学习都提高了样本效率。
局限性 SENSEI受益于完全可观察的观察结果,例如能够捕捉环境中所有相关方面的图像。当处理遮挡问题时,VLM注释以及由此提炼出的奖励函数会受到影响。在Robodesk中,我们使用第二个摄像头角度进行VLM注释以减少噪声。在未来的工作中,可以通过对视频进行注释来进一步解决这个问题,以更好地传达时间或部分可观察的信息。
未来工作 我们假设SENSEI从探索中学习了一个多功能的世界模型,因为它是在更丰富的互动数据集上进行训练的。在未来的工作中,我们计划通过将其用于零样本基于模型的规划(Sancaktar等人,2022[^9])来进一步检验所探索的世界模型的多功能性。此外,在补充材料D.2中,通过比较用于初始玩耍数据集Dinit的两个来源,我们观察到SENSEI在一定程度上强化了初始探索轮次中存在的趋势。为了进一步强化更复杂的互动类型,我们可以使用从SENSEI运行中获得的新VLM注释来细化我们的奖励函数。因此,SENSEI有可能通过每一代的迭代解锁越来越复杂的行为。除此之外,观察结果的真实性可能会帮助VLM注释,因为VLM的大部分训练数据来自真实世界的照片或视频。因此,我们认为SENSEI可以很好地扩展到更现实的应用或现实世界任务中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









