






本文我们将为大家带来数维杯国际赛MCM B题超详细解题思路+问题一二三初步解题代码分享。代码放于文末【目前只有matlab代码,python代码明早六点与论文同步更新】后续具体更新时间轴
11.15 12:00 更新赛题翻译、相关文献资料、选题建议、赛题难度
11.15 16:00 更新人工精翻版本赛题、数据预处理代码
11.15 24:00 更新完整解题思路、部分解题代码
11.16 06:00 更新完整论文+解题代码+讲解视频
11.16 18:00 更新降重说明+答疑讲解
11.17 18:00 相关内容答疑讲解
11.18 18:00 无水印代码+无水印可视化
【数维杯分享版】
链接:https://pan.baidu.com/s/1zdpRqu2urPcifQyOG6WnIw
提取码:x4jj
对于数据类型题目,首先需要进行数据预处理以便能够后续处理。因此本文一共分为五个部分分别为数据预处理、问题一二三四求解思路讲解。
数据预处理
首先,我们需要理解题目给出的数据含义,
附件中的数据来自于一个矩形区域。矩形区域的结构如下:
(1)X坐标范围:列跨度从51250.0000米到64500.0000米;
(2)Y坐标范围:行跨度从78750.0000米到92000.0000米;
(3)研究区域被划分为50米×50米的小网格,共有266×266个网格点。空间变量的采样值在这些网格点上提供。
这句话翻译过来的意思,个人认为应该是,整体空间为13,250*13,250米正方形矩阵,分别对应X坐标范围列跨度从51250.0000米到64500.0000米;Y坐标范围:行跨度从78750.0000米到92000.0000米;给出数据为266*266,即组成13,250*13,250米正方形矩阵由266*266个50*50米的正方形小网格组成。如下所示【草图,仅供理解】如理解有误,欢迎在评论区指出
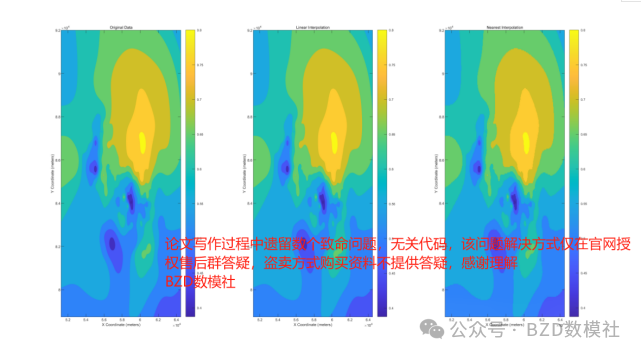
因此,我们利用这种思路对数据进行汇总整合,得到结果。并对原始的数据进行插值,得到在原50米一数据的基础上得到每5米一数据,对比如下所示
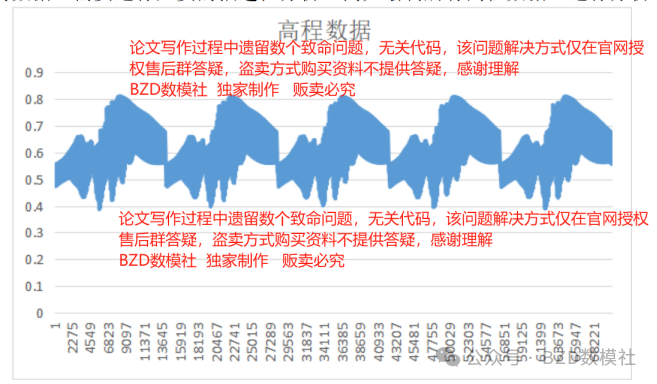
同时,为了进一步对数据进行检验以便处理缺失值、异常值,我们对题目给出的数据还需要进行必要的描述性分析,例如绘制所有高程数据,进行分析。
问题一
问题描述:使用附件1中的数据,研究一个空间变量(F1_目标变量)的变化模式。
1. 随机且均匀地重采样目标变量,用重采样后的数据估计未抽样点的空间变量值,并以等高线图的形式展示结果。
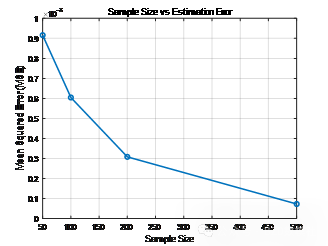
2. 通过改变样本量,探索样本量与估计误差之间的关系。
对于问题一,通过重采样的方法对附件1中的数据进行处理,研究空间变量(F1_目标变量)的变化模式。随机选择一部分原始数据点进行采样,这些数据点将用于构建插值模型。随机采样确保数据的代表性,以便在研究区域内进行较为准确的插值估计。将整个研究区域的数据点作为集合,从中随机均匀地选取一定比例的样本点可以选择不同的样本量,例如50、100、200、500等,以评估不同采样密度对估计的影响。
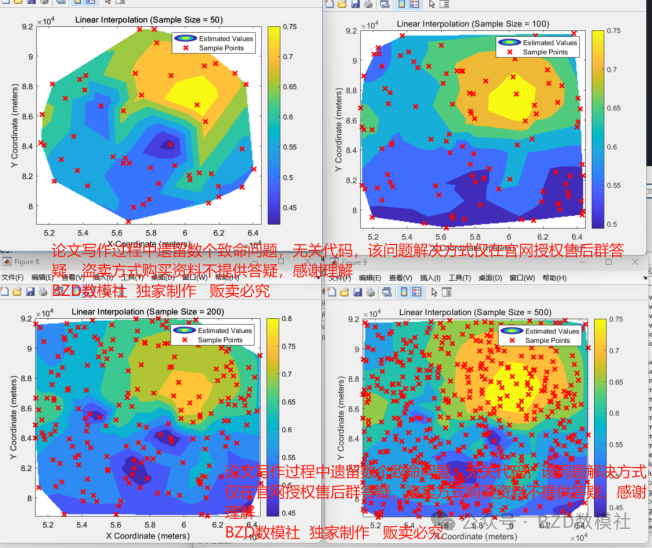
对于重采样的数据,利用插值方法来估计未采样点的目标变量值。通过改变采样量(例如50、100、200、500等),研究样本量对插值估计结果的影响。
问题二
问题描述:使用附件1中的数据,研究目标变量与协同变量之间的相关性。选择两个协同变量作为估计目标变量的协同变量。
从附件1中读取目标变量和所有协同变量的数据。在这个问题中,目标变量是F1_目标变量,协同变量是F1_协同变量1、F1_协同变量2、F1_协同变量3和F1_协同变量4。在这里,相关性分析用来衡量目标变量与协同变量之间的线性关系。通过计算相关系数,我们可以了解每一个协同变量对目标变量的影响程度。使用皮尔逊相关系数(Pearson Correlation Coefficient)来衡量目标变量和协同变量之间的相关性。具体结果如下所示

创新点:除了使用最基础的相关性分析结果外,我们还可以使用其他方法,会再论文写作中进行实现基于二维网格的逐点相关性计算、通过分块区域进行相关性计算、使用空间统计方法 - 空间自相关分析(Moran's I 等)、使用卷积操作来捕捉空间相关性、多维相关性 - 使用空间协方差矩阵等
问题三
问题描述:使用附件1的数据和问题2的结论,选择一个或两个协同变量,研究空间变量(F1_目标变量)的变化模式。
1. 随机且均匀地重采样目标变量和协同变量,用重采样后的数据估计未抽样点的空间变量值,并以等高线图的形式展示结果。
2. 通过改变样本量,探索样本量与估计误差之间的关系。
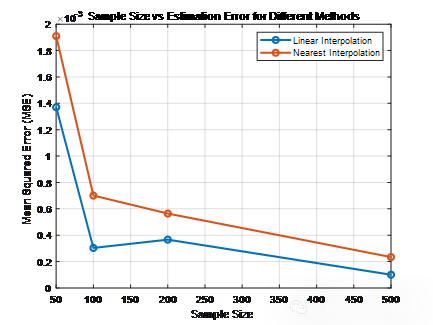
3. 选择至少两种方法进行比较。
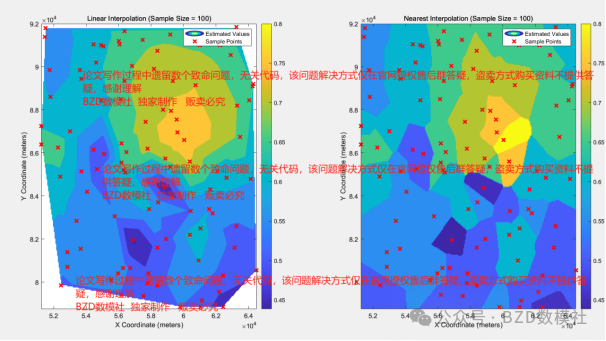
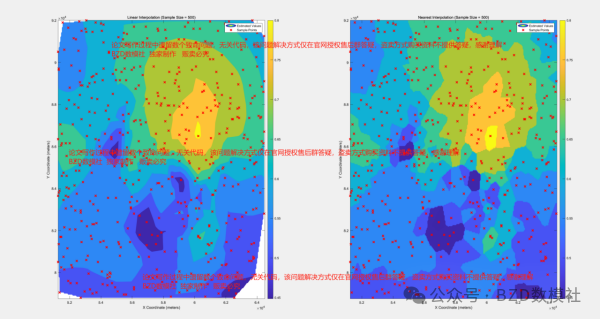
从附件1中读取目标变量(F1_目标变量)以及两个协同变量(基于问题二中相关性最高的两个协同变量)。从目标变量和两个协同变量的数据中随机选择一部分数据,作为估计整个空间的基础。插值方法: 使用不同的方法对未采样点的目标变量进行估计,至少选择两种插值方法进行比较:
·线性插值(Linear Interpolation)
·最近邻插值(Nearest Neighbor Interpolation)
·其他插值方法: 可选择 cubic 等插值方法进行对比。
问题四
问题描述:附件2中的目标变量(F2_目标变量)采样数据不足。选择问题3中的最佳方法来估计目标变量的趋势,并以等高线图的形式展示结果。
在附件2中,F2_目标变量的数据为不完全采样,即采样点数量不足以完全描述目标区域的所有网格点信息。目标是在这种情况下,使用问题三中找到的最佳插值方法来对整个研究区域的目标变量进行估计,并用等高线图的形式展示结果。
在问题三中,我们使用了不同的插值方法来估计目标变量的空间分布,并根据估计误差(MSE)来判断哪个方法最合适。我们这里使用线性插值得到结果如下所示,其余部分即可仿照
clc;
clear;
% 1. 数据读取
try
% 直接读取目标变量和协同变量1、4的数据
values_raw = readmatrix('F1_target_variable.txt');
% 删除数据中的 NaN 值
values_raw(any(isnan(values_raw), 2), :) = [];
% 将每 266 个数据组合成一行,构建最终矩阵
num_blocks = floor(size(values_raw, 1) / 266);
values = reshape(values_raw(1:num_blocks * 266, :)', [], 266)';
% 对协同变量进行相同的读取和处理
covariate1_raw = readmatrix('F1_collaborative_variable1.txt');
covariate1_raw(any(isnan(covariate1_raw), 2), :) = [];
covariate1 = reshape(covariate1_raw(1:num_blocks * 266, :)', [], 266)';
covariate4_raw = readmatrix('F1_collaborative_variable4.txt');
covariate4_raw(any(isnan(covariate4_raw), 2), :) = [];
covariate4 = reshape(covariate4_raw(1:num_blocks * 266, :)', [], 266)';
catch ME
disp('读取文件失败,请检查文件路径和格式');
rethrow(ME);
end
% 确保所有变量尺寸一致
if ~isequal(size(values), size(covariate1), size(covariate4))
error('目标变量和协同变量的尺寸不一致,请检查数据。');
end
% 网格信息
[grids_y, grids_x] = size(values);
x_coords = linspace(51250, 64500, grids_x);
y_coords = linspace(78750, 92000, grids_y);
[x_grid, y_grid] = meshgrid(x_coords, y_coords);
% 2. 使用不同的插值方法对中间层进行估计
% 选择中间的一个层(例如总层数的一半)进行插值对比
original_layer = values; % 此处只有一个层的数据
% 2.1 使用线性插值
% 增加插值网格的密度,使得数据更加密集
x_coords_dense = linspace(51250, 64500, grids_x * 10);
y_coords_dense = linspace(78750, 92000, grids_y * 10);
[x_grid_dense, y_grid_dense] = meshgrid(x_coords_dense, y_coords_dense);
z_estimated_linear = griddata(x_grid(:), y_grid(:), original_layer(:), x_grid_dense, y_grid_dense, 'linear');
% 2.2 使用最近邻插值
% 增加插值网格的密度,使得数据更加密集
z_estimated_nearest = griddata(x_grid(:), y_grid(:), original_layer(:), x_grid_dense, y_grid_dense, 'nearest');
% 3. 绘制等高线图并与原始数据进行对比
figure;
% 原始数据等高线图
subplot(1, 3, 1);
contourf(x_grid, y_grid, original_layer, 'LineStyle', 'none');
colorbar;
title(['Original Data']);
xlabel('X Coordinate (meters)');
ylabel('Y Coordinate (meters)');
% 线性插值等高线图
subplot(1, 3, 2);
contourf(x_grid_dense, y_grid_dense, z_estimated_linear, 'LineStyle', 'none');
colorbar;
title('Linear Interpolation');
xlabel('X Coordinate (meters)');
ylabel('Y Coordinate (meters)');
% 最近邻插值等高线图
subplot(1, 3, 3);
contourf(x_grid_dense, y_grid_dense, z_estimated_nearest, 'LineStyle', 'none');
colorbar;
title('Nearest Interpolation');
xlabel('X Coordinate (meters)');
ylabel('Y Coordinate (meters)');
clc;
clear;
% 1. 数据读取
try
% 直接读取目标变量和协同变量1、4的数据
values_raw = readmatrix('F1_target_variable.txt');
% 删除数据中的 NaN 值
values_raw(any(isnan(values_raw), 2), :) = [];
% 将每 266 个数据组合成一行,构建最终矩阵
num_blocks = floor(size(values_raw, 1) / 266);
values = reshape(values_raw(1:num_blocks * 266, :)', [], 266)';
% 对协同变量进行相同的读取和处理
covariate1_raw = readmatrix('F1_collaborative_variable1.txt');
covariate1_raw(any(isnan(covariate1_raw), 2), :) = [];
covariate1 = reshape(covariate1_raw(1:num_blocks * 266, :)', [], 266)';
covariate4_raw = readmatrix('F1_collaborative_variable4.txt');
covariate4_raw(any(isnan(covariate4_raw), 2), :) = [];
covariate4 = reshape(covariate4_raw(1:num_blocks * 266, :)', [], 266)';
catch ME
disp('读取文件失败,请检查文件路径和格式');
rethrow(ME);
end
% 确保所有变量尺寸一致
if ~isequal(size(values), size(covariate1), size(covariate4))
error('目标变量和协同变量的尺寸不一致,请检查数据。');
end
% 网格信息
[grids_y, grids_x] = size(values);
x_coords = linspace(51250, 64500, grids_x);
y_coords = linspace(78750, 92000, grids_y);
[x_grid, y_grid] = meshgrid(x_coords, y_coords);
% 2. 重采样
sample_sizes = [50, 100, 200, 500]; % 采样量
for i = 1:length(sample_sizes)
size = sample_sizes(i);
% 随机选择采样点
sample_indices = randperm(grids_y * grids_x, size);
[sample_rows, sample_cols] = ind2sub([grids_y, grids_x], sample_indices);
sample_x = x_coords(sample_cols);
sample_y = y_coords(sample_rows);
sample_values = values(sub2ind([grids_y, grids_x], sample_rows, sample_cols));
% 3. Kriging 插值
% 使用 scatteredInterpolant 函数进行插值估计
F = scatteredInterpolant(sample_x', sample_y', sample_values', 'linear', 'nearest');
z_estimated = F(x_grid, y_grid);
% 4. 绘制等高线图
figure;
contourf(x_grid, y_grid, z_estimated, 'LineStyle', 'none');
hold on;
plot(sample_x, sample_y, 'rx', 'MarkerSize', 8, 'LineWidth', 2);
colorbar;
title(['Kriging Interpolation (Sample Size = ', num2str(size), ')']);
xlabel('X Coordinate (meters)');
ylabel('Y Coordinate (meters)');
legend('Estimated Values', 'Sample Points');
hold off;
end

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









