








本文选自于 conference paper at ICLR 2022
摘要
基于时间序列数据准确预测过去的未来至关重要,因为它为提前做出决策和风险管理打开了大门。在实践中,所面临的挑战是建立一个灵活但简洁的模型,它可以捕获广泛的时间依赖性。在本文中,我们通过探索时间序列的多分辨率表示来提出Pyraformer。具体来说,我们引入了金字塔注意力模块(PAM),其中尺度间树结构总结了不同分辨率下的特征,尺度内相邻连接建模了不同范围的时间相关性。在温和条件下,Pyraformer中信号穿越路径的最大长度相对于序列长度L是常数(即O(1)),而其时间和空间复杂度与L成线性比例。广泛的实验结果表明,Pyraformer通常以最少的时间和内存消耗在单步和长程多步预测任务中实现最高的预测精度,尤其是当序列长时。
结论和展望
在本文中,我们提出了Pyraformer,这是一种基于金字塔注意力的新模型,它可以有效地描述短时间和长时间依赖性,同时具有低的时间和空间复杂性。具体地说,我们首先利用CSCM构建C元树,然后设计PAM以在尺度间和尺度内传递消息。当序列长度L增加时,通过调整C和固定其他参数,Pyraformer可以实现理论上的O(L)复杂度和O(1)最大信号穿越路径长度。实验结果表明,所提出的模型在单步和长程多步预测任务方面都优于最先进的模型,但计算时间和内存成本较低。到目前为止,我们只关注在构造金字塔图时A和S固定且C随L增加的情况。另一方面,我们在附录I中表明,超参数的其他配置可以进一步提高Pyraformer的性能。在未来的工作中,我们将探索如何从数据中自适应地学习超参数。此外,将Pyraformer扩展到其他领域,包括自然语言处理和计算机视觉也是很有意思的。
时序预测算法的挑战
理想的时序模型应该满足以下两个特性:
1.建模长程依赖的能力强:一般的时序中通常存在着不同尺度的依赖关系(比如日周期,周周期,和月周期)。如何找到一个强力的模型来对这些依赖关系进行建模是时序预测的关键。在不同尺度的依赖关系中,最难被处理的是长程依赖关系。模型对长程依赖的建模能力可以由时序中任意两点在模型里的最大信息传播路径来粗略评判[1],路径越短,模型对于长程依赖的建模效果越好;
2.时空复杂度低:为了捕捉长程依赖,输入模型的历史数据也需要很长。为了达到这个目的,模型的时空复杂度必须尽可能的小。
不幸的是,目前主流的方法难以同时实现上述两个目标。一方面,CNN [5]、RNN [6]等网络尽管时间复杂度是随时间序列长度$L$线性增长的,但最大信息传播路径是$\mathcal O(L)$的,因此难以学习到长程依赖。Transformer [1] 则是另一个极端,将最大信息传播路径降到了$\mathcal O(1)$,但时间复杂度则增大到了$\mathcal O(L^2)$,因此也难以应用于非常长的序列。
为了在模型能力与复杂度之间找到平衡,近来很多Transformer的变种涌现了出来,例如Longformer [2], Reformer [3] 和Informer [4]. 然而,这些变种也难以同时实现短于$\mathcal O(L)$的最大信息传播路径和极低的时空复杂度。

图1: 序列数据上常用的神经网络对应的图结构:从上到下、从左到右依次是RNN,Transformer,CNN,Pyraformer
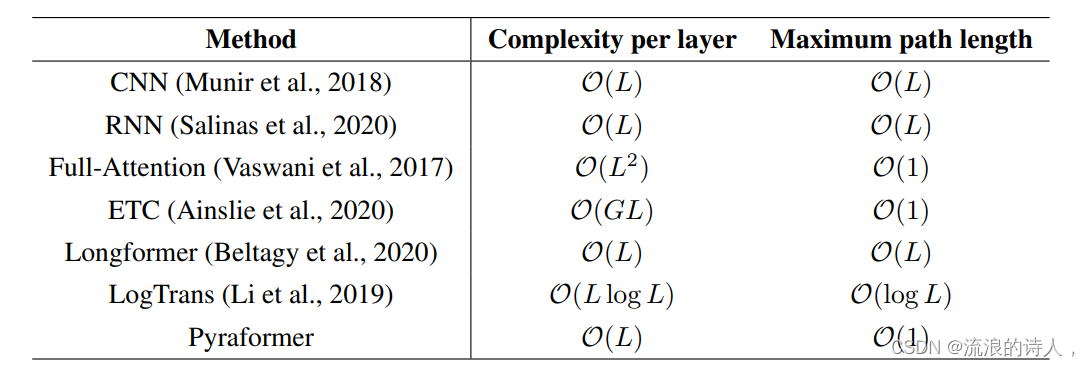
表1: 不同模型的复杂度和最大信息传播路径比较。其中,$G$是ETC中的全局节点数,实际使用中$G$会随着$L$增长,因此ETC的时空复杂度是超线性的
针对这些挑战,本文提出了Pyraformer,通过提取时间序列中的多尺度特征来进行预测。我们首先引入了金字塔注意模块(PAM),该模块采用树结构来执行自注意力,通过尺度间连边提取不同分辨率的特征,通过尺度内连边建模不同尺度的依赖关系
在适当条件下,Pyraformer中的最大信息传播路径相对于序列长度$L$是一个常数(即$\mathcal O(1)$),而时空复杂度与$L$呈线性关系。大量实验表明,Pyraformer在单步和长程预测任务中都能以最少的时间和内存占用达到最高的预测精度,尤其是在序列较长的情况下。
解决方案
时间序列预测的问题可以描述为:给定历史的$L$个观测值$\bold z_{t - L + 1 : t}$及其对应的协变量$\bold x_{t - L + 1 :t + M}$(比如观测值对应的日期、小时),预测$M$个未来值$\bold z_{t+1:t+M}$。
为了应对上述挑战,本文提出了一种基于金字塔注意力的 Transformer,来取得捕捉长程依赖和实现低时空复杂度的良好平衡,如图2所示。与Informer [4]相同的是,我们先对观测数据、协变量和位置分别做特征嵌入,然后再将它们相加。接下来,我们使用粗尺度构造模块(CSCM)构建了一棵有$C$个分支的多叉树,其中粗尺度的节点汇总了相应的$C$个细尺度节点的信息。
为了进一步捕获不同范围的时间依赖关系,我们引入了金字塔注意模块(PAM),在金字塔形的图结构中使用注意力机制交换信息。最后,根据下游任务的不同,我们使用不同的网络结构来输出最终的预测。
本文的主要贡献包括:
● 我们提出了 Pyraformer,以多分辨率的方式同时捕捉不同范围的时间依赖关系。为了与目前最先进的方法区分开,我们在图1中以图结构的形式总结了所有对比模型。
● 我们在理论上证明了通过适当选取参数,Pyraformer 可以同时实现$\mathcal O(1)$的最大信息传播路径和$\mathcal O(L)$的时空复杂度。为了突出 Pyraformer 的吸引力,我们进一步在表1中比较了不同模型的最大信息传播路径和复杂度。
● 实验表明,不论是单步预测任务还是长程预测任务,我们提出的 Pyraformer 在多个真实数据集上都取得了比 Transformer 及其变体更好的效果,并且消耗的时间和显存更低。

图2:Pyraformer的结构:CSCM将嵌入序列汇总为不同分辨率的序列,从而构建出一个多分辨率的树结构。然后,PAM被用来在节点之间高效地交换信息
下面我们详细阐述Pyraformer的各个部分:
A 金字塔注意模块(Pyramidal Attention Module, PAM)
由于PAM是本文提出方法的核心,我们首先介绍PAM。如图1(d)所示,我们利用该金字塔形的图结构,以多分辨率的方式表征历史序列中的时间依赖关系。在金字塔图中,我们假设最底层的节点对应了我们观察到的时序。比如,我们观察到的时序是小时粒度,那每个节点对应了一个小时。
上层的节点,可以认为是总结了每天,每周,和每月的信息。为了进行精准的时序预测,我们需要做的就是找到过于和未来的关系,然后基于过去才能预测未来。这里,我们通过连接每一层节点,来建模过于与未来。比如每个小时之间的关系,在底层进行了建模,而每个月之间的关系在顶层进行了建模。
由于,月与月之前的关系在顶层进行了建模,到了周这一层,就不在需要考虑本周与上个月同一周之间了关系了,只需要考虑相邻的一两周之间的关系。因此,每一层里,我们只考虑相邻节点之间的关系。整个图通过attention机制构建,即把Transformer中的全连接图换成金字塔图。
B 粗粒度构造模块(Coarse-Scale Construction Module, CSCM)
CSCM的目的是初始化金字塔图上的粗尺度节点,以便后续的PAM在这些节点之间交换信息。这里通过带bottleneck的卷积网络实现,如下图所示。

图3:粗尺度构造模块: $B$为批大小,$D$为节点特征的维度大小
C 预测模块
这里,我们提出了两种预测模块。第一种直接连接一个线性层,输出结果即为预测值。第二种使用了一个由两层全连接注意力层组成的解码器。具体结构如下图所示。我们发现,由于PAM可以比较好的从时序中提取各种信息,简单线性层已经可以很好的预测未来。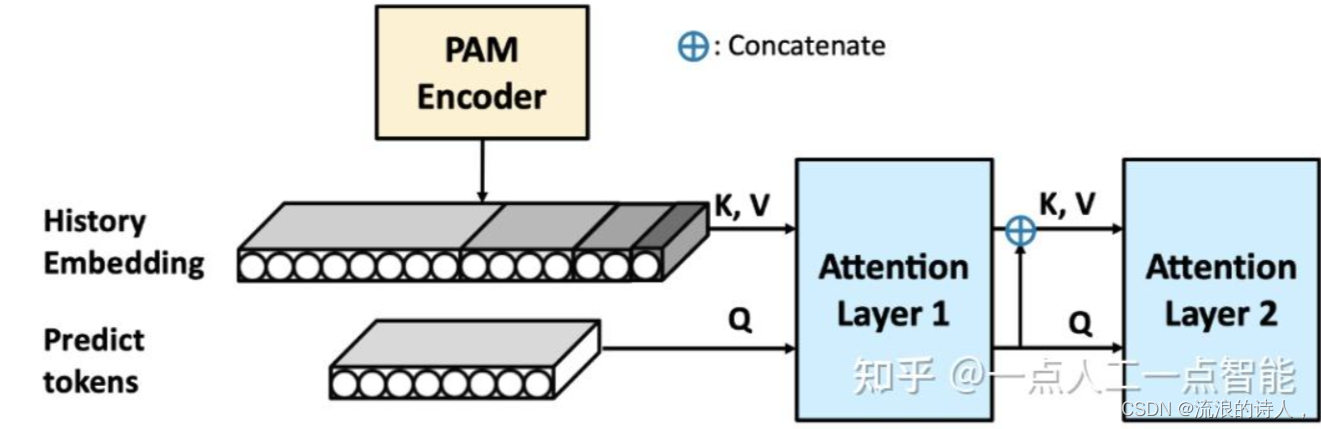
图4:基于attention机制的预测模块
A 单步预测
我们将Pyraformer与其他5种注意力机制进行了对比,包括原始的Full-attention[1],LogTrans[8],Reformer[3],ETC[7]和Longformer[2]。各方法的结果展示在表2中。
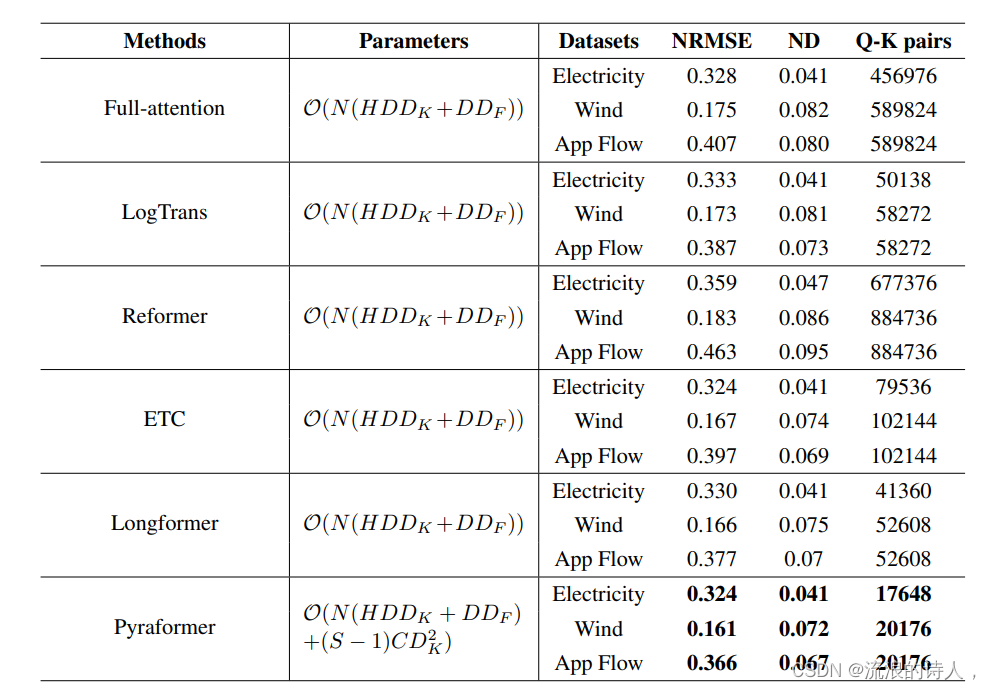
表2:三个数据集上的单步预测结果。"Q-K对"指网络中所有注意力层执行的查询向量和键向量点积的数量,代表了模型的时空复杂度。$N$代表注意力层数,$H$代表注意力头数,$S$代表尺度数,$D$代表每个节点的特征维度。$D_K$表示键向量的特征维度,$D_F$表示前馈层的最大特征维度,而$C$表示CSCM中卷积的步
实验结果表明,Pyraformer在NRMSE和ND方面优于Transformer及其变种,并且具有最少的计算量。
B 长程预测
我们在三个数据集上评估了Pyraformer的长程预测性能,包括Electricity,ETTh1和ETTm1。我们将解决方案中提出的两个预测模块装配到所有模型上进行了测试,并在表3中列出了最好的结果。
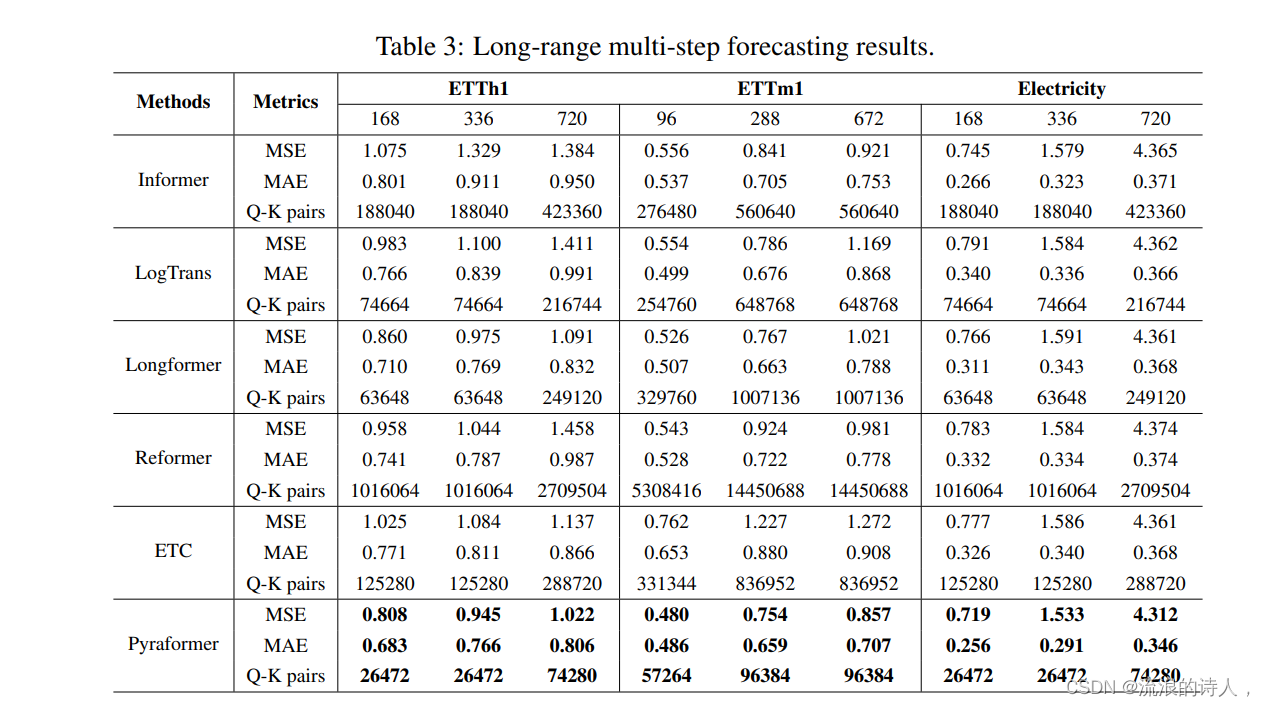
表3: 长程预测结果
可以看到,在所有数据集和所有预测长度上,Pyraformer仍然以最少的Q-K对达到了最好的性能。有趣的是,我们注意到对于Pyraformer,第一个预测模块的效果比第二个预测模块的结果更好。
C 速度和显存占用
为了检验基于TVM实现的PAM专用CUDA核的效率,我们在图4中分别以计算时间和显存占用为纵轴,以序列长度$L$为横轴,画出了二者随序列长度的变化。这里我们只比较了Informer[4]中的prob-sparse注意力机制、全连通注意力机制和PAM。

图5:不同注意力机制的时间和显存消耗比较。包括全连通注意力、Informer的prob-sparse注意力和PAM的TVM实现: (a) 计算时间; (b) 显存占用
图4表明,基于TVM的PAM的计算和存储开销近似为$L$的线性函数,与预期一致,且比全连通注意力机制和prob-sparse注意力机制小几个数量级,特别是对于较长的序列。(更多实验请参考论文原文)














 3851
3851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









