







参考资料:https://wmathor.com/index.php/archives/1453/
首先你需要知道,Transformer 是以字作为输入,将字进行
字嵌入之后,再与
位置嵌入进行
相加(不是拼接,就是单纯的对应位置上的数值进行加和)

需要使用位置嵌入的原因也很简单,因为 Transformer 摈弃了 RNN 的结构,因此需要一个东西来标记各个字之间的时序 or 位置关系,而这个东西,就是位置嵌入
如果让我们从 0 开始设计一个 Positional Encoding,比较容易想到的第一个方法是取 [0,1] 之间的数分配给每个字,其中 0 给第一个字,1 给最后一个字,具体公式就是
 . 这样做的问题在于,假设在较短文本中任意两个字位置编码的差为 0.0333,同时在某一个较长文本中也有两个字的位置编码的差是 0.0333。假设较短文本总共 30 个字,那么较短文本中的这两个字其实是相邻的;假设较长文本总共 90 个字,那么较长文本中这两个字中间实际上隔了两个字。这显然是不合适的,因为相同的差值,在不同的句子中却不是同一个含义
. 这样做的问题在于,假设在较短文本中任意两个字位置编码的差为 0.0333,同时在某一个较长文本中也有两个字的位置编码的差是 0.0333。假设较短文本总共 30 个字,那么较短文本中的这两个字其实是相邻的;假设较长文本总共 90 个字,那么较长文本中这两个字中间实际上隔了两个字。这显然是不合适的,因为相同的差值,在不同的句子中却不是同一个含义
另一个想法是线性的给每个时间步分配一个数字,也就是说,第一个单词被赋予 1,第二个单词被赋予 2,依此类推。这种方式也有很大的问题:1. 它比一般的字嵌入的数值要大,难免会抢了字嵌入的「风头」,对模型可能有一定的干扰;2. 最后一个字比第一个字大太多,和字嵌入合并后难免会出现特征在数值上的倾斜
理想的设计
理想情况下,位置嵌入的设计应该满足以下条件:
-
它应该为每个字输出唯一的编码
-
不同长度的句子之间,任何两个字之间的差值应该保持一致
-
它的值应该是有界的
作者设计的位置嵌入满足以上的要求。首先,它不是一个数字,而是一个包含句子中特定位置信息的d维向量。其次,这种嵌入方式没有集成到模型中,相反,这个向量是用来给句子中的每个字提供位置信息的,换句话说,我们通过注入每个字位置信息的方式,增强了模型的输入(
其实说白了就是将位置嵌入和字嵌入相加,然后作为输入)
设t为一句话中某个字的位置,
 表示位置t时刻这个词位置嵌入的向量,
表示位置t时刻这个词位置嵌入的向量,
 的定义如下
的定义如下

其中

k指的是位置嵌入中维度的下标,为了使得位置嵌入和字嵌入能够相加,因此位置嵌入维度和字嵌入的维度必须相同
所以
 ,所以就有
,所以就有

对于三角函数
 来说,周期是
来说,周期是
 ,因此 B 越大,频率值越大,一个周期内函数图像重复次数越多,波长越短.
,因此 B 越大,频率值越大,一个周期内函数图像重复次数越多,波长越短.
回到
的定义中,k是越来越大的,因此wk越来越小,所以
 也越来越小,于是频率随着向量维度下标的递增而递减,频率递减 = 周期变长。我们计算一下周期最小是
也越来越小,于是频率随着向量维度下标的递增而递减,频率递减 = 周期变长。我们计算一下周期最小是
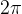 (k=0时),周期最大是1000*
(k=d/2时)
(k=0时),周期最大是1000*
(k=d/2时)
你可以想象下t时刻字的位置编码
是一个包含 sin 和 cos 函数的向量(假设d可以被 2 整除)
直观展示
你可能想知道 sin 和 cos 的组合是如何表示位置信息的?这其实很简单,假设你想用二进制表示一个数字,你会怎么做?

用二进制表示一个数字太浪费空间了,因此我们可以使用与之对应的连续函数 —— 正弦函数
















 2241
2241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









