







NVIDIA RTX A6000深度学习训练基准
在本文中,我们对RTX A6000的PyTorch和TensorFlow培训性能进行了基准测试。我们将其与Tesla A100,V100,RTX 2080 Ti,RTX 3090,RTX 3080,RTX 2080 Ti,Titan RTX,RTX 6000,RTX 8000,RTX 6000等进行了比较。
RTX A6000亮点
- 记忆体:48 GB GDDR6
- PyTorch convnet “FP32”的表现:〜 1.5倍比RTX 2080钛快
- PyTorch NLP“ FP32”性能:比RTX 2080 Ti快3.0倍
- TensorFlow convnet“ FP32”性能:比RTX 2080 Ti快1.8倍
- 零售价: $ 4,650
PyTorch“ 32位”卷积训练速度
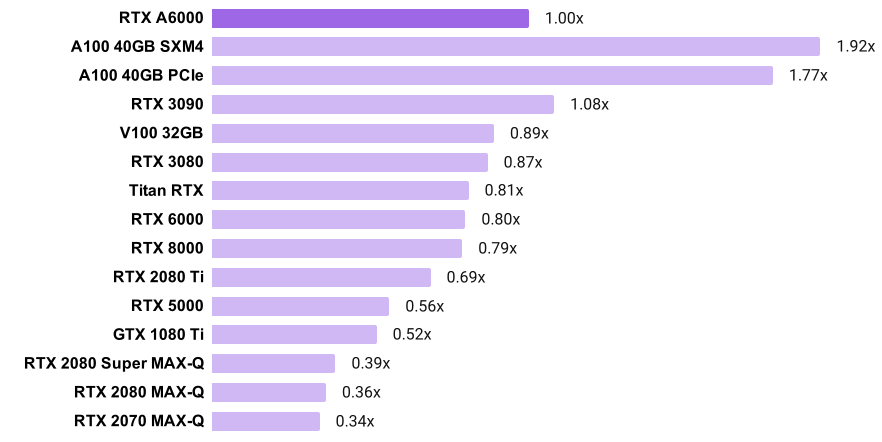
- 图表显示,例如,A100 SXM4比RTX A6000快92%
- 请注意,A100和A6000使用TensorFloat-32,而其他GPU使用FP32
- 每个GPU的训练速度是通过平均SSD,ResNet-50和Mask RCNN的标准化训练吞吐量(图像/秒)来计算的。
PyTorch“ 32位”语言模型的训练速度
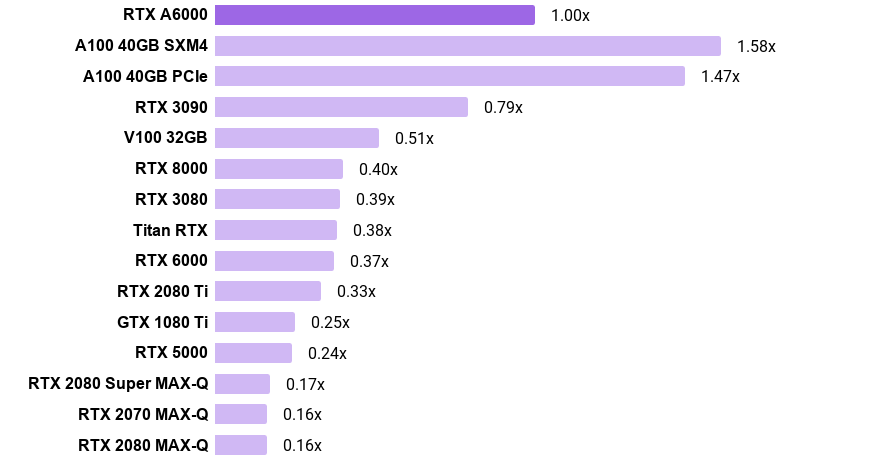
- 图表显示,例如,A100 SXM4比RTX A6000快58%
- 请注意,A100和A6000使用TensorFloat-32,而其他GPU使用FP32
- 每个GPU的训练速度是通过在Transformer-XL基础,Transformer-XL大,Tacotron 2和BERT基础SQuAD上对标准化的训练吞吐量进行平均来计算的。
TensorFlow“ 32位” convnet训练速度
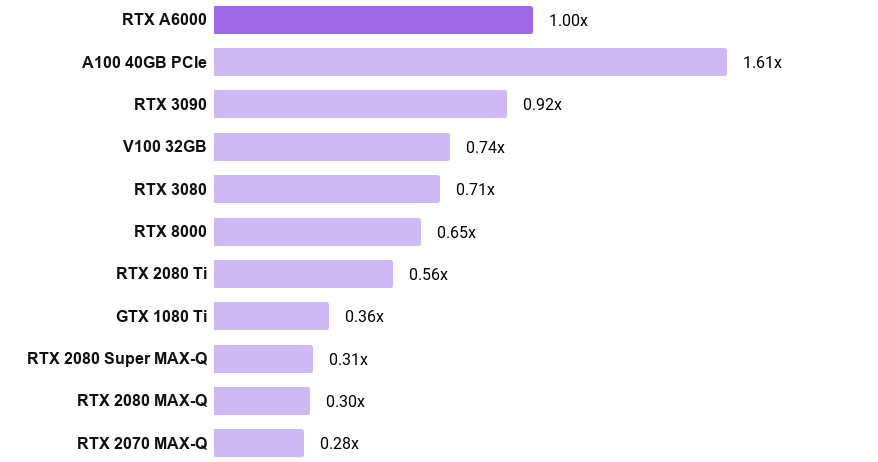
- 图表显示,例如,A100 PCIe比RTX A6000快61%
- 请注意,A100和A6000使用TensorFloat-32,而其他GPU使用FP32
- 每个GPU的训练速度是通过平均其在ResNet-152,ResNet-50,Inception v3,Inception v4,AlexNet和VGG-16上的标准化训练吞吐量(图像/秒)来计算的。
PyTorch基准测试软件堆栈
注意:我们正在使用所有GPU上使用相同软件版本的新基准测试。
RTX A6000,Tesla A100s,RTX 3090和RTX 3080已使用
NGC的PyTorch 20.10 docker映像和Ubuntu 18.04,PyTorch 1.7.0a0 + 7036e91,CUDA 11.1.0,cuDNN 8.0.4,NVIDIA驱动程序460.27.04和NVIDIA进行了基准测试优化的模型实现。
使用NGC的PyTorch 20.01 docker映像,Ubuntu 18.04,PyTorch 1.4.0a0 + a5b4d78,CUDA 10.2.89,cuDNN 7.6.5,NVIDIA驱动程序440.33和NVIDIA优化的模型实现,对安培前GPU进行了基准测试。
TensorFlow基准测试软件堆栈
注意:我们正在使用所有GPU上使用相同软件版本的新基准测试。
RTX A6000使用NGC的TensorFlow 20.10 docker映像进行了基准测试,该映像使用Ubuntu 18.04,TensorFlow 1.15.4,CUDA 11.1.0,cuDNN 8.0.4,NVIDIA驱动程序455.32和Google的官方模型实现。
特斯拉A100,RTX 3090和RTX 3080已使用Ubuntu 18.04,TensorFlow 1.15.4,CUDA 11.1.0,cuDNN 8.0.4,NVIDIA驱动程序455.45.01和Google的官方模型实现进行了基准测试。
使用TensorFlow 1.15.3,CUDA 10.0,cuDNN 7.6.5,NVIDIA驱动程序440.33和Google的官方模型实现对安培前GPU进行了基准测试。



















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











