







Abstract
我们表明,我们的框架不仅可以处理从标记的侧信息生成的标准的一起/分开约束(没有先前报道的良好记录的不利影响),还可以处理从新类型的侧信息(如连续值和高级领域知识)生成的更复杂的约束。
We show that our framework can not only handle standard together/apart constraints (without the well-documented negative effects reported earlier) generated from labeled side information but more complex constraints generated from new types of side information such as continuous values and high-level domain knowledge.
本文的目的之一是探索深度学习如何能在聚类领域取得超越其他方法的进步。特别是,我们发现现有的约束聚类的非深度公式有以下局限性:
-有限的限制和侧面信息( Side Information)。约束仅限于简单的一起/分开(together/apart)的约束,通常由标签生成。在某些领域中,专家可能会更自然地在集群级别提供指导,或从连续的边信息中生成约束。
-约束条件的负面影响。对于一些算法,当在许多约束集上平均提高性能时,单个约束集产生的结果比使用没有约束的[8]更差。由于从业者通常有一个约束集,它们的使用可能是“命中或错过”。
-不可缩性和可伸缩性问题。直接解决聚类分配的迭代算法遇到了棘手的[7]问题。松弛的公式(即光谱方法[17,26])需要解决一个全秩特征分解问题,它需要O(n 3)。
-假设具有良好的特性。一个核心要求是已经为复杂的数据创建了良好的特性或相似性函数。
由于深度学习是自然可伸缩的,并且能够找到有用的表示,我们关注第一和第二个挑战,但通过实验探索第三和第四个挑战。尽管带有约束的深度聚类有许多潜在的好处来克服这些限制,但它并非没有挑战。我们在本文中的主要贡献总结如下:
-我们提出了一个深度约束聚类公式,它不仅可以编码标准约束一起/分开,还可以编码新的三重约束(可以从连续的边信息生成)、实例难度约束和聚类级平衡约束(见第3节)。
-深度约束聚类克服了我们在PKDD早期[8]中报道的一个长期问题,具有深刻实际意义的约束聚类:克服单个约束集的负面影响。
-我们展示了深度学习的好处,如可伸缩性和端到端学习,如何转化为我们的深度约束聚类公式。在具有挑战性的数据集上,我们获得了比传统的约束聚类方法(使用从自动编码器生成的特征)更好的聚类结果(见表2)。
3 Deep Constrained Clustering Framework
在这里,我们概述了我们提出的深度约束聚类的框架。我们的深度学习添加约束和训练方法可以用于大多数深度聚类方法(只要网络有k个单位输出来表示聚类隶属度),这里我们选择了流行的深度嵌入聚类方法(DEC [27])。为了保证完整性,我们首先概述了这个方法。
3.1 Deep Embedded Clustering
我们选择将我们的约束公式应用于深度嵌入式聚类方法DEC [27],该方法首先预训练一个自动编码器(xi = g(f(xi)),然后删除解码器。剩下的编码器(zi = f(xi))然后通过优化一个目标来细化,该目标取第一个zi并将其转换为一个软目标长度为k的分配向量,我们称之为qi,j,表示实例i属于簇j的信念程度。然后对q进行自训练,产生一个单峰的“硬”分配向量,它将实例主要只分配给一个集群。现在,我们将概述每一步
z向软聚类分配向量q的转换
.这里DEC取一个嵌入点zi和由学生的t-分布[18]测量的聚类质心uj之间的相似性。注意,v是一个常数,因为v = 1和qij是一个软赋值:
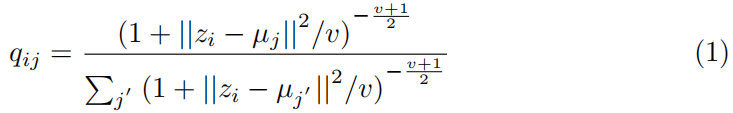
将Q转换为硬集群分配P
上述嵌入点和质心之间的归一化相似性可以看作是软聚类分配q。然而,我们希望有一个更类似于硬分配向量的目标分布P,pij定义为:
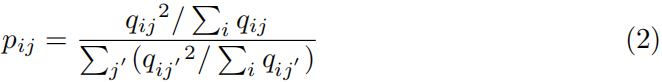
Loss Function
然后,该算法的损失函数是将P和Q之间的距离最小化如下。注意,这是一种自我训练的形式,因为我们正试图教网络产生单峰的集群分配向量。
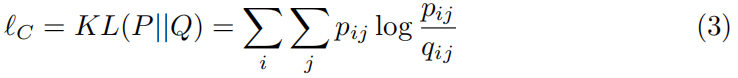
DEC方法要求给出的初始质心(µ)来计算Q是“有代表性的”。使用k-means聚类来设置初始质心。然而,并不能保证自动编码器嵌入的聚类结果产生良好的聚类。我们相信,约束条件有助于克服这个我们稍后将进行测试的问题。
3.2 Different Types of Constraints
为了提高聚类性能,并允许人类和聚类模型之间进行更多类型的交互,我们提出了四种类型的指导,它们是成对约束、实例难度约束、三重约束和基数,并给出了每种约束的例子。由于传统的约束聚类方法对最终的聚类分配进行了约束,我们提出的方法约束了q向量,即软分配。当添加约束时,一个核心挑战是允许生成的损失函数是可微的,这样我们就可以推导出反向传播更新。
成对约束
成对约束(必须链接和不能链接)得到了很好的研究[3],我们证明了它们能够定义任何基础真集分区[7]。这里我们展示了如何将这些成对约束添加到深度学习算法中。我们将必须链接约束集( must-link constraints set)ML的损失编码为:

同样地,无法链接的约束集(cannot-link constraints set)CL的损失是:
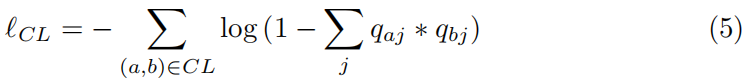
直观地说,必须链接loss更倾向于具有相同软分配的实例,而不能链接loss更倾向于相反的情况。
实例难度限制
深度学习中自我学习的一个挑战是,如果初始质心不正确,自我训练可能会导致糟糕的结果。在这里,我们使用约束来克服这一点,通过允许用户指定哪些实例更容易集群(即,它们只强烈地属于一个集群),并通过忽略困难的实例(即,那些强烈地属于多个集群的实例)。
我们用n×1约束向量M对用户监督进行编码,设Mi∈[−1,1]为实例难度指标,Mi > 0表示实例i容易聚类,Mi = 0表示没有提供难度信息,Mi < 0表示实例i难以聚类。损失函数表示为:
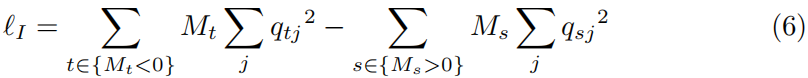
实例难度损失函数旨在鼓励更容易的实例进行稀疏聚类分配,但防止困难的实例有稀疏聚类分配。Mi的绝对值表示难度估计的置信度。这种损失将有助于模型训练过程在更容易的实例上更快地收敛,并增加我们的模型对困难实例的鲁棒性。
三重约束
尽管成对约束能够从标记数据[7]定义任何地面真实集分区,但在许多领域中没有标记边信息存在或强的成对指导不可用。因此,我们寻找三重约束,这是一种较弱的约束,表明在三重实例内的关系。给定一个锚定实例a,正实例p和负实例n,我们说实例a更类似于p而不是n。所有三胞胎(a,p,n)∈T的损失函数可以表示为:
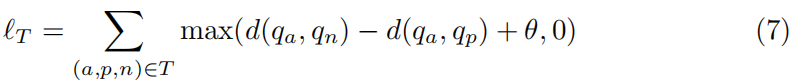
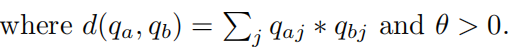
d(qa, qb)的值越大,表示a和b之间的相似性越大。变量θ控制正反实例之间的间隙距离。
l
T
l_T
lT的工作原理是将正实例的赋值推近锚的赋值,并防止负实例的赋值靠近锚的赋值。
全局大小约束
专家们可能会更自然地在集群级别上提供指导。这里我们探讨了聚类大小约束,这意味着每个聚类的大小应该大致相同。表示集群请求总数,训练实例总数为n,全局大小约束损失函数为:
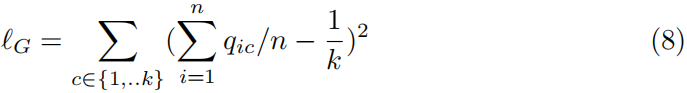
我们的全局约束损失函数通过最小化预期集群大小和实际集群大小之间的距离来工作。实际的集群大小是通过平均软分配来计算的。为了保证全局大小约束的有效性,我们需要假设在我们的小批量训练中,批量大小应该大到足够大来计算集群大小。可以使用类似的损失函数(参见第3.4节)来强制执行对集群组合的其他基数约束,例如对具有某一属性的人数的上界和下界。
3.3 Preventing Trivial Solution防止琐碎的解决方案
在我们的框架中,我们前面提到的必须链接约束可以导致简单的解决方案,即所有实例都映射到同一个集群。以往的深度聚类方法[30]也遇到了这个问题。为了缓解这个问题,我们将重建损失和必须链接的损失结合起来一起学习。将编码网络表示为f (x),解码网络表示为g (x),例如xi的重构损耗为:
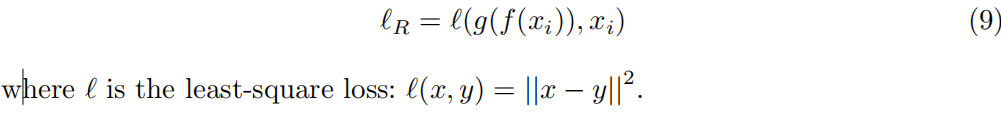
3.4 扩展到基于知识的高级领域约束
尽管我们提出的大多数约束都是基于实例标签或比较生成的。我们的框架可以扩展到基于领域知识的高级约束,只需稍加修改。
基数约束
例如,基数约束[6]允许表达对每个集群中满足某些条件的实例数量的要求。假设我们有n个人,想把他们分成k个聚餐小组。基数约束的一个例子是强制每一方应该有相同数量的男性和女性。我们将n人分为M(男性)和F(女性)两组,其中|M| + |F| = N, M∩N =∅。则基数约束可以表示为:
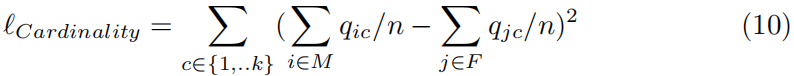
对于基于上界和下界的基数约束[6],我们使用前面描述的相同的设置,现在约束随着每个党组的变化,我们需要男性的数量从L到u。然后我们可以将其表述为:

约束条件的逻辑组合
除了基数约束外,复杂的逻辑约束还可以用来增强表示知识的表达能力。例如,如果两个实例x1和x2在同一集群中,那么实例x3和x4必须在不同的集群中。这可以在我们的框架中实现,因为一旦我们检查了x1和x2的软赋值q,我们就可以动态地添加不能链接的约束CL(x3,x4)。
考虑一个角形约束,如r∧s∧t→u,记为r = ML(x1, x2),s = ML(x3, x4), t = ML(x5, x6), u = CL(x7, x8)。将r, s, t范围内的实例前向传递给深约束聚类模型,得到这些实例的软赋值。通过验证基于r∧s∧t的满意结果,我们可以决定是否强制不可链路损失CL(x7, x8)。
4.把它们放在一起-高效的培训策略
我们的培训策略由两个培训分支组成,有效地有两种创建小批量培训的方法。例如,对于难度或全局大小的限制,我们将它们的损失函数视为令人上瘾的损失,因此不需要创建额外的分支。对于成对约束或三重约束,我们为它们构建另一个输出分支,并以另一种方式训练整个网络。
实例约束的损失分支
在深度学习中,通常会添加在相同的输出单元上定义的损失函数。在改进的DEC方法[11]中,将聚类损失
l
C
l_C
lC和重建损失
l
R
l_R
lR相加。此外,我们还添加了实例难度损失
l
I
l_I
lI。这通过识别“容易”实例有效地增加了加速训练收敛的指导,并通过忽略“困难”实例增加了模型的鲁棒性。同样地,我们将全局大小约束损失
l
G
l_G
lG视为一个额外的附加损失。所有的实例,无论它们是否是三元组约束或成对约束的一部分,都是通过这个分支进行训练的,并且小批量都是随机创建的。
复杂约束条件下的损失分支
我们的框架使用更复杂的损失函数,因为它们定义了对对甚至三组实例的约束。因此,我们创建了另一个包含成对损失
l
P
l_P
lP或三重损失
l
T
l_T
lT的损失分支,以帮助网络调整嵌入,以满足这些更强的约束。
对于每个约束类型,我们创建一个mini-batch,该batch只包含具有该约束类型的实例。对于约束类型的每个示例,我们通过网络提供受约束的实例,计算损失,计算权重的变化,但不调整权重。我们对小批中所有约束示例的权重调整相加,然后调整权重。因此,我们的方法是批权重更新的一个例子,这是DL的稳定性原因。算法1总结了整个训练过程。
















 5290
5290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









