







Coding Skill目录下的所有Tutorials、Notes博客都会不定期迭代更新,只为记录学习历程,便于回顾总结
Contents of table
Tutorials
数据结构
Pandas处理以下三个数据结构
- 系列(Series)
- 数据帧(DataFrame)
- 面板(Panel)
这些数据结构构建在Numpy数组之上,这意味着它们很快。
可变性
所有Pandas数据结构是值可变的(可以更改),除了系列都是大小可变的。系列是大小不变的。
注 - DataFrame被广泛使用,是最重要的数据结构之一。面板使用少得多。
快速入门
对象创建
通过传递值列表来创建一个系列,让Pandas创建一个默认的整数索引:
import pandas as pd
import numpy as np
s = pd.Series([1,3,5,np.nan,6,8])
print(s)
执行后输出结果如下:
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
通过传递numpy数组,使用datetime索引和标记列来创建DataFrame:
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=7)
print(dates)
print("--"*16)
df = pd.DataFrame(np.random.randn(7,4), index=dates, columns=list('ABCD'))
print(df)
执行后输出结果如下:
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07'],
dtype='datetime64[ns]', freq='D')
--------------------------------
A B C D
2017-01-01 -0.732038 0.329773 -0.156383 0.270800
2017-01-02 0.750144 0.722037 -0.849848 -1.105319
2017-01-03 -0.786664 -0.204211 1.246395 0.292975
2017-01-04 -1.108991 2.228375 0.079700 -1.738507
2017-01-05 0.348526 -0.960212 0.190978 -2.223966
2017-01-06 -0.579689 -1.355910 0.095982 1.233833
2017-01-07 1.086872 0.664982 0.377787 1.012772
…
查看数据
df.head()
df.tail()
df.index
df.columns
df.values
df.describe()
df.T : 调换数据
df.sort_index :排序,轴排序、按列的值排序
选择区块
.at,.iat,.loc,.iloc和.ix
获取
df.A
df[‘A’]
df[0:3]
df[‘20170102’:‘20170103’]
按标签选择
df.loc[dates[0]]
df.loc[:,[‘A’,‘B’]]
df.loc[‘20170102’:‘20170104’,[‘A’,‘B’]]
df.loc[‘20170102’,[‘A’,‘B’]]
df.loc[dates[0],‘A’]
df.at[dates[0],‘A’]
通过位置选择
df.iloc[3]
df.iloc[3:5,0:2]
df.iloc[[1,2,4],[0,2]]
df.iloc[1:3,:]
df.iloc[:,1:3]
df.iloc[1,1]
df.iat[1,1]
布尔索引
df[df.A > 0]
df[df > 0]
df2[df2[‘E’].isin([‘two’,‘four’])]
Series
pandas.Series( data, index, dtype, copy)。

创建一个空的系列
从ndarray创建一个系列
从字典创建一个系列
从标量创建一个系列
从具有位置的系列中访问数据
使用标签检索数据(索引)
DataFrame
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
数据帧(DataFrame)的功能特点:
潜在的列是不同的类型大小可变标记轴(行和列)可以对行和列执行算术运算
pandas.DataFrame( data, index, columns, dtype, copy)

Panel
基本功能


描述性统计

函数应用
要将自定义或其他库的函数应用于Pandas对象,有三个重要的方法,下面来讨论如何使用这些方法。使用适当的方法取决于函数是否期望在整个DataFrame,行或列或元素上进行操作。
- 表合理函数应用:pipe()
- 行或列函数应用:apply()
- 元素函数应用:applymap()
重建索引
重新索引会更改DataFrame的行标签和列标签。重新索引意味着符合数据以匹配特定轴上的一组给定的标签。
可以通过索引来实现多个操作 -
- 重新排序现有数据以匹配一组新的标签。
- 在没有标签数据的标签位置插入缺失值(NA)标记。
迭代
Pandas对象之间的基本迭代的行为取决于类型。当迭代一个系列时,它被视为数组式,基本迭代产生这些值。其他数据结构,如:DataFrame和Panel,遵循类似惯例迭代对象的键。
简而言之,基本迭代(对于i在对象中)产生 -
- Series - 值
- DataFrame - 列标签
- Pannel - 项目标签
要遍历数据帧(DataFrame)中的行,可以使用以下函数 -
- iteritems() - 迭代(key,value)对
- iterrows() - 将行迭代为(索引,系列)对
- itertuples() - 以namedtuples的形式迭代行
排序
Pandas有两种排序方式,它们分别是 -
- 按标签
- 按实际值
字符串和文本数据

选项和自定义
索引和选择数据
在本章中,我们将讨论如何切割和丢弃日期,并获取Pandas中大对象的子集。
Python和NumPy索引运算符"[]“和属性运算符”."。 可以在广泛的用例中快速轻松地访问Pandas数据结构。然而,由于要访问的数据类型不是预先知道的,所以直接使用标准运算符具有一些优化限制。对于生产环境的代码,我们建议利用本章介绍的优化Pandas数据访问方法。
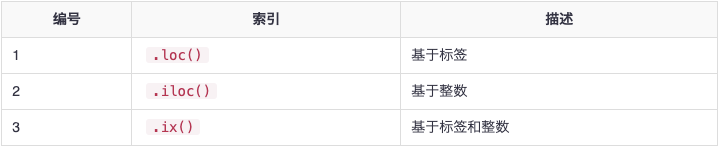
Pandas现在支持三种类型的多轴索引; 这三种类型在下表中提到 -
统计函数
pct_change()函数
协方差
相关性
数据排名
窗口函数
聚合
缺失数据
检查缺失值
缺少数据的计算
清理/填充缺少数据
用标量值替换NaN
填写NA前进和后退
丢失缺少的值
替换丢失(或)通用值
分组(GroupBy)
任何分组(groupby)操作都涉及原始对象的以下操作之一。它们是 -
- 分割对象
- 应用一个函数
- 结合的结果
在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数。在应用函数中,可以执行以下操作 -
- 聚合 - 计算汇总统计
- 转换 - 执行一些特定于组的操作
- 过滤 - 在某些情况下丢弃数据
合并/连接
Pandas具有功能全面的高性能内存中连接操作,与SQL等关系数据库非常相似。Pandas提供了一个单独的merge()函数,作为DataFrame对象之间所有标准数据库连接操作的入口 -
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True)

级联
Pandas提供了各种工具(功能),可以轻松地将Series,DataFrame和Panel对象组合在一起。
pd.concat(objs,axis=0,join=‘outer’,join_axes=None,
ignore_index=False)

日期功能
时间差
分类数据
可视化
Series和DataFrame上的这个功能只是使用matplotlib库的plot()方法的简单包装实现。
IO工具
Pandas I/O API是一套像pd.read_csv()一样返回Pandas对象的顶级读取器函数。
读取文本文件(或平面文件)的两个主要功能是read_csv()和read_table()。它们都使用相同的解析代码来智能地将表格数据转换为DataFrame对象 -
pandas.read_csv(filepath_or_buffer, sep=’,’, delimiter=None, header=‘infer’,
names=None, index_col=None, usecols=None)
Python
形式2-
pandas.read_csv(filepath_or_buffer, sep=’\t’, delimiter=None, header=‘infer’,
names=None, index_col=None, usecols=None)
稀疏数据
SQL
使用Pandas执行各种SQL操作
选择(Select)
WHERE条件
通过GroupBy分组
前N行
pandas 将大文件分块读取
这类问题易佰教程里是没有的,可以遇到了去搜csdn,看看别人的解决方案。看文档太枯燥,暂时不推荐一遇到问道直接去看文档,可以辅助查阅、参考一下。
import pandas as pd
reader = pd.read_csv('paintings_hashSet.csv', sep=r'\|\|', iterator=True, engine='python')
# Another Uasge
# reader = pd.read_csv('paintings_hashSet.csv', sep=r'\|\|', iterator=True, engine='python', chunksize=10000)
print(type(reader)) # <class 'pandas.io.parsers.TextFileReader'>
for idx in range(3):
df = reader.get_chunk(10000)
print(type(df)) # <class 'pandas.core.frame.DataFrame'>
print(df.head(2))
print('=='*10)
Ref 1
Ref 2
Ref 3
Ref 4 Official Document














 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









