







开源大模型更新迭代太快,今年刚推出的模型可能过几个月就过时了。关于这个问题,我想更多的不是思考现在能部署哪些大模型,而是要思考三个方面:
一是如何找到最新的大模型,二是如何判断本地硬件资源是否满足大模型的需求,三是如何快速部署大模型。
一、如何找到最新的大模型?
1.huggingface
huggingface可以理解为对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库(比如transformers|peft|accelerate)、教程等。
几乎所有最新开源的大模型都会上传到huggingface,涵盖多模态、CV、NLP、Audio、Tabular、Reinforcement Learning等模型。
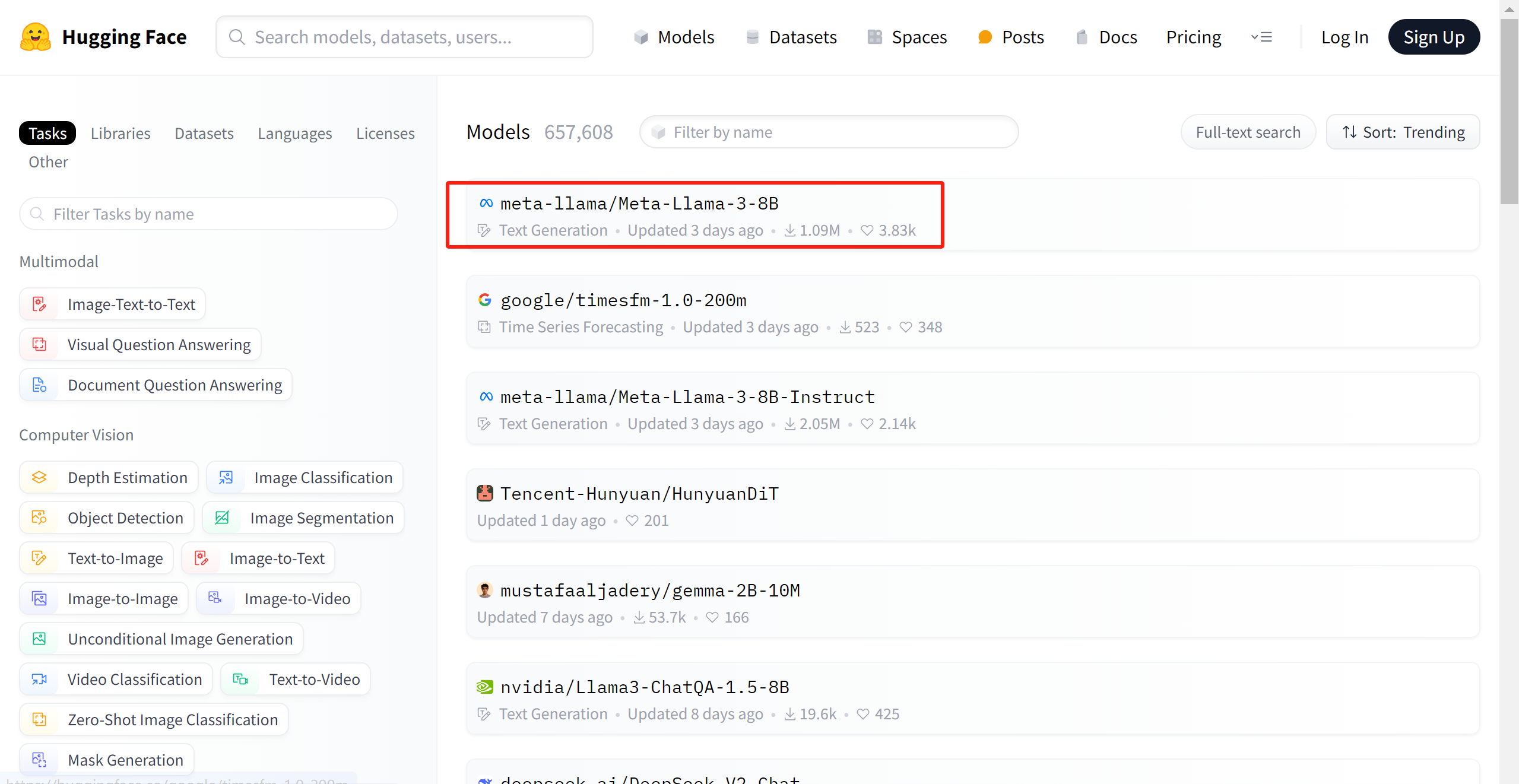
上图红框处就是meta最新开源的Llama3,参数量为8B(80亿参数)。
2.modelscope
huggingface有时存在网络不稳定的问题
这里推荐国内比较好的平台modelscope
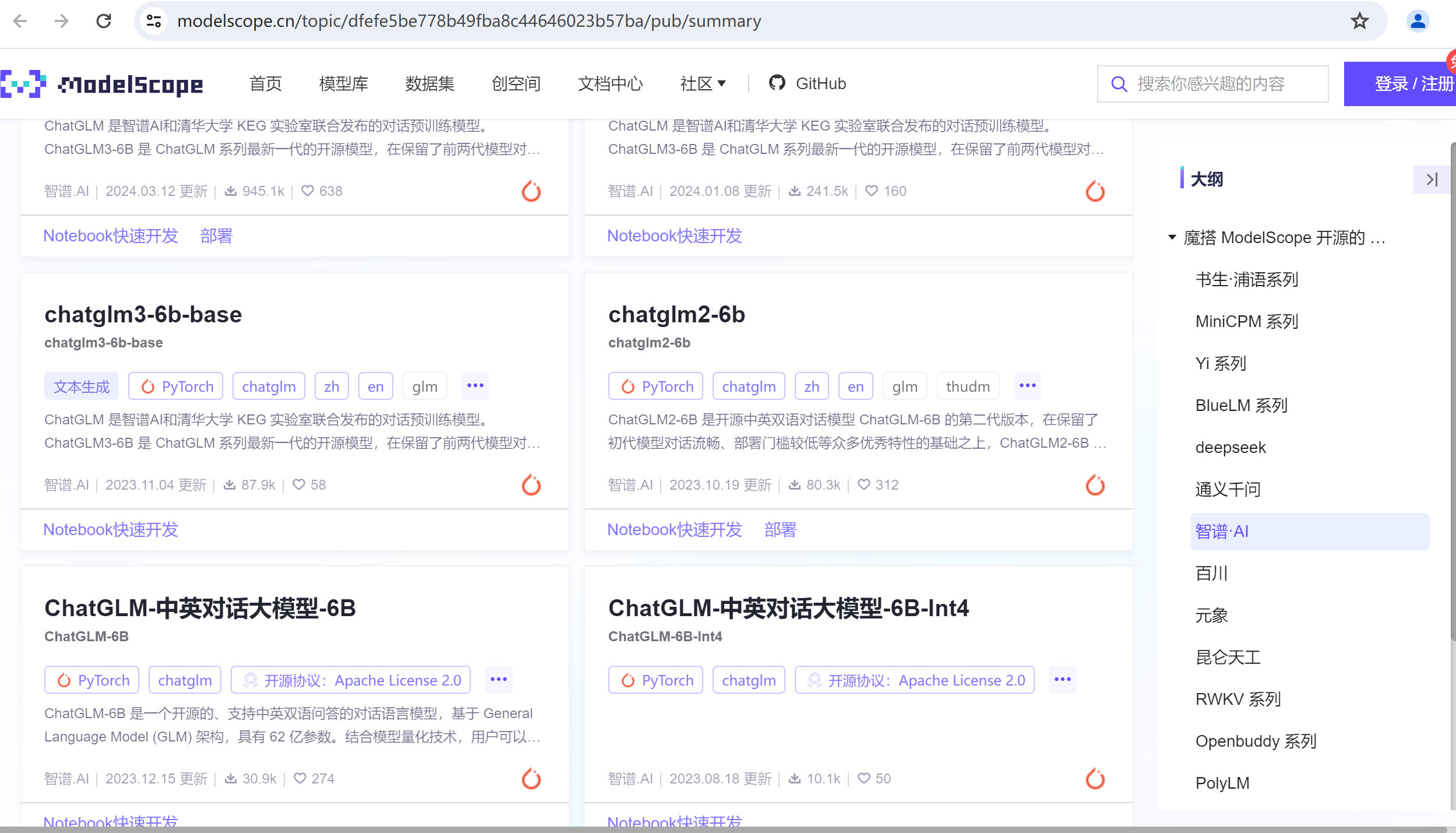
由上图可看到,通过modelscope也可以几乎下载所有开源大模型,包括零一万物、百川、通义千问等等。
比如chatglm2-6b,代表它的模型名称为chatglm2,参数量为60亿。
二、如何判断本地硬件资源是否满足大模型的需求?
首先要搞清楚,本地可以部署什么大模型,取决于你的硬件配置(尤其关注你GPU的显存)。
一般来说,只要你本地机器GPU的显存能够满足大模型的要求,那基本上都可以本地部署。
那么大模型类别这么多,有7B、13B、70B等等,我的GPU显存如何准备呢?
在没有考虑任何模型量化技术的前提下:
公式:模型显存占用(GB) = 大模型参数(B)X 2
我之前为了探索千亿级大模型到底需要多少计算资源,用云计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









