







大家好,我是程序锅。
github上的代码封装程度高,不利于小白学习入门。
常规的大模型RAG框架有langchain等,但是langchain等框架源码理解困难,debug源码上手难度大。
因此,我写了一个人人都能看懂、人人都能修改的大模型RAG框架代码。
整体项目结构如下图所示:手把手教你大模型RAG框架架构
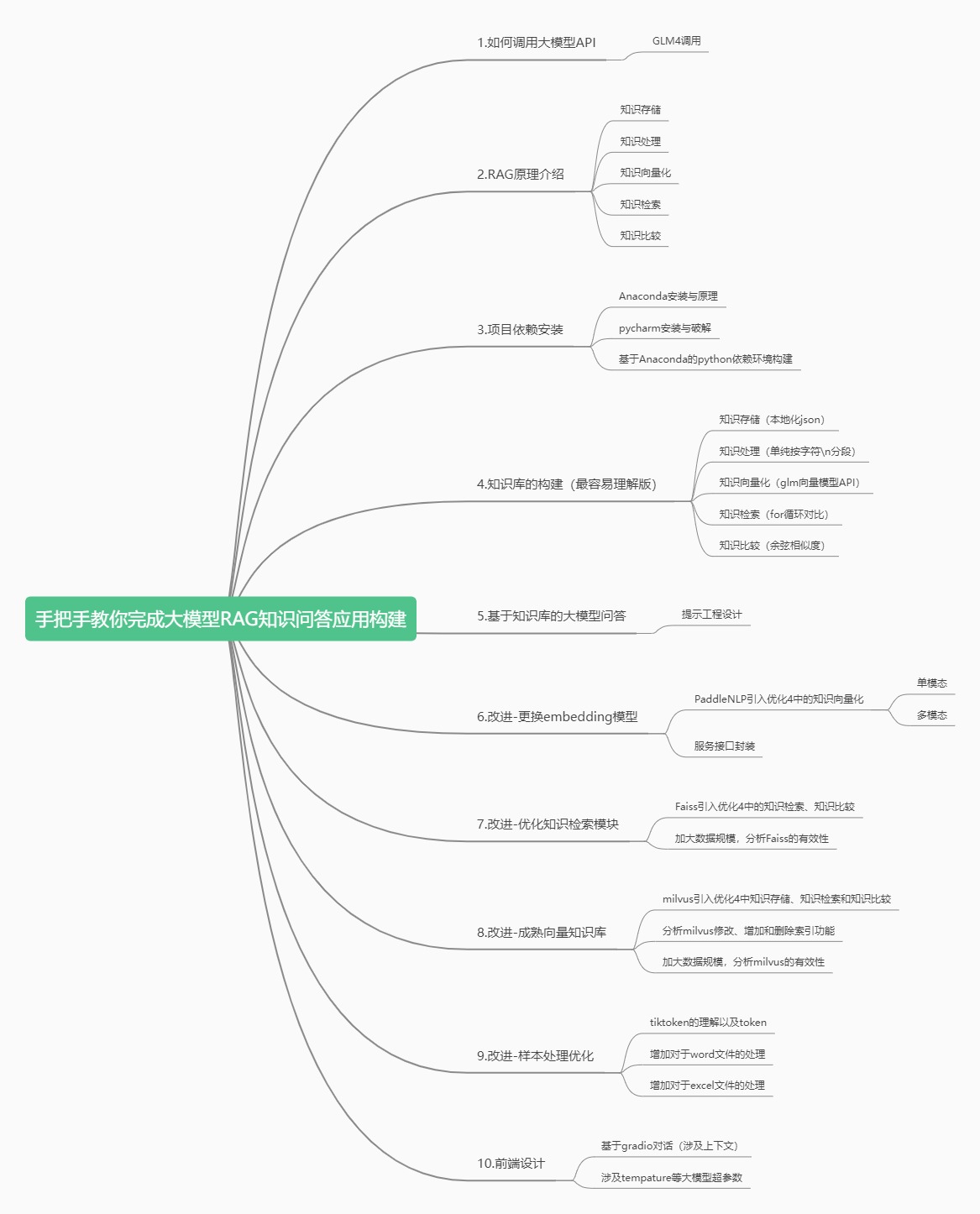
整个小项目分为10个章节,和github高度封装的RAG代码不同,我们将从0到1搭建大模型RAG问答系统。
前序章节:
自己手写了一个大模型RAG项目-04.知识库构建

本篇文章将介绍5.基于知识库的大模型问答,知识库构建好之后还需要通过知识检索和智能问答。
一、知识检索
首先第一个问题,为什么要做知识检索
在整个大模型RAG智能问答应用构建过程中,需要将用户的问题向量化,将向量化后的问题与知识库内的向量做匹配。
前面几篇文章已经讲述了如何构建知识库,目前需要从向量库中匹配与问题最相似的k个向量(k是一个超参数,需要根据大模型输入上下文长度来界定)
怎么匹配以及匹配的标准是什么呢?
匹配的目的就是一堆向量中找到最相似的几个向量,最简单直白的方式就是去遍历所有向量,计算问题向量与知识库所有向量之间的相似度,然后按照相似度多少,从高到低排序,取最大的几个。
匹配的标准也很简单,我采用了余弦相似度。此外可以用L2范数、内积、曼哈顿距离、p范数等等。
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
""& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









