







6.2 图的存储结构
图是一种复杂的数据结构,顶点之间是多对多的关系,即任意两个顶点之间 都可能存在联系。所以,无法以顶点在存储区的位置关系来表示顶点之间的联系, 即顺序存储结构不能完全存储图的信息,但可以用数组来存储图的顶点信息。要 存储顶点之间的联系必须用链式存储结构或者二维数组。图的存储结构有多种, 这里只介绍两种基本的存储结构:邻接矩阵和邻接表。
6.2.1 邻接矩阵
邻接矩阵(Adjacency Matrix)是用两个数组来表示图,一个数组是一维数 组,存储图中顶点的信息,一个数组是二维数组,即矩阵,存储顶点之间相邻的 信息,也就是边(或弧)的信息,这是邻接矩阵名称的由来。 假设图G=(V,E)中有n个顶点,即V={v0,v1,…,vn-1},用矩阵A[i][j]表示边 (或弧)的信息。矩阵A[i][j]是一个n×n的矩阵,矩阵的元素为:
若 G 是网,则邻接矩阵可定义为
其中,wij 表示边(vi,vj)或弧<vi,vj>上的权值;∞表示一个计算机允许的大于 所有边上权值的数。 图6.1(a)、图6.2(a)、图6.2(b)的图的邻接矩阵如图6.8(a)、6.8(b)、6.8(c) 所示。
⎟
从图的邻接矩阵表示法可以看出这种表示法的特点是:
(1)无向图或无向网的邻接矩阵一定是一个对称矩阵。因此,在具体存放 邻接矩阵时只需存放上(或下)三角矩阵的元素即可。
(2)可以很方便地查找图中任一顶点的度。对于无向图或无向网而言,顶 点 vi 的度就是邻接矩阵中第 i 行或第 i 列中非 0 或非∞的元素的个数。对于有 向图或有向网而言,顶点 vi 的入度是邻接矩阵中第 i 列中非 0 或非∞的元素的 个数,顶点 vi 的出度是邻接矩阵中第 i 行中非 0 或非∞的元素的个数。
(3)可以很方便地查找图中任一条边或弧的权值,只要 A[i][j]为 0 或∞, 就说明顶点 vi 和 vj 之间不存在边或弧。但是,要确定图中有多少条边或弧,则 必须按行、按列对每个元素进行检测,所花费的时间代价是很大的。这是用邻接 矩阵存储图的局限性。
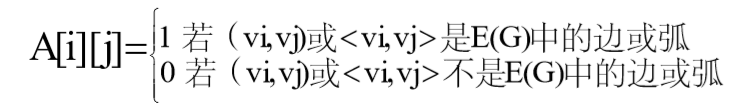
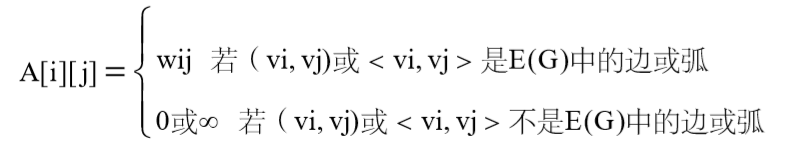



下面以无向图的邻接矩阵类的实现来说明图的邻接矩阵表示的类的实现。 无向图邻接矩阵类 GraphAdjMatrix<T>中有三个成员字段,一个是 Node<T> 类型的一维数组 nodes,存放图中的顶点信息;一个是整型的二维数组 matirx, 表示图的邻接矩阵,存放边的信息;一个是整数 numEdges,表示图中边的数目。 因为图的邻接矩阵存储结构对于确定图中边或弧的数目要花费很大的时间代价, 所以设了这个字段。
无向图邻接矩阵类 GraphAdjMatrix<T>的实现如下所示
public class GraphAdjMatrixs<T> : IGraph<T>
{
private Node<T>[] nodes; //顶点数组
private int numEdges; //边的数目
private int[,] matrix; //邻接矩阵数组
//构造器
public GraphAdjMatrixs(int n)
{
nodes = new Node<T>[n];
matrix = new int[n, n];
numEdges = 0;
}
//获取索引为index的顶点的信息
public Node<T> GetNode(int index)
{
return nodes[index];
}
//设置索引为index的顶点的信息
public void SetNode(int index, Node<T> v)
{
nodes[index] = v;
}
//边的数目属性
public int NumEdges
{
get
{
return numEdges;
}
set
{
numEdges = value;
}
}
//获取matrix[index1, index2]的值
public int GetMatrix(int index1, int index2)
{
return matrix[index1, index2];
}
//设置matrix[index1, index2]的值
public void SetMatrix(int index1, int index2)
{
matrix[index1, index2] = 1;
}
//获取顶点的数目
public int GetNumOfVertex()
{
return nodes.Length;
}
//获取边的数目
public int GetNumOfEdge()
{
return numEdges;
}
//判断v是否是图的顶点
public bool IsNode(Node<T> v)
{
//遍历顶点数组
foreach (Node<T> nd in nodes)
{
//如果顶点nd与v相等,则v是图的顶点,返回true
if (v.Equals(nd))
{
return true;
}
}
return false;
}
//获取顶点v在顶点数组中的索引
public int GetIndex(Node<T> v)
{
int i = -1;
//遍历顶点数组
for (i = 0; i < nodes.Length; ++i)
{
//如果顶点v与nodes[i]相等,则v是图的顶点,返回索引值i。
if (nodes[i].Equals(v))
{
return i;
}
}
return i;
}
//在顶点v1和v2之间添加权值为v的边
public void SetEdge(Node<T> v1, Node<T> v2,int v)
{
//v1或v2不是图的顶点
if (!IsNode(v1) || !IsNode(v2))
{
Debug.WriteLine("Node is not belong to Graph!"); return;
}
//不是无向图
if (v != 1)
{
Debug.WriteLine("Weight is not right!"); return;
}
//矩阵是对称矩阵
matrix[GetIndex(v1), GetIndex(v2)] = v;
matrix[GetIndex(v2), GetIndex(v1)] = v;
++numEdges;
}
//删除顶点v1和v2之间的边
public void DelEdge(Node<T> v1, Node<T> v2)
{
//v1或v2不是图的顶点
if (!IsNode(v1) || !IsNode(v2))
{
Debug.WriteLine("Node is not belong to Graph!"); return;
}
//顶点v1与v2之间存在边
if (matrix[GetIndex(v1), GetIndex(v2)] == 1)
{
//矩阵是对称矩阵
matrix[GetIndex(v1), GetIndex(v2)] = 0;
matrix[GetIndex(v2), GetIndex(v1)] = 0;
--numEdges;
}
}
//判断顶点v1与v2之间是否存在边
public bool IsEdge(Node<T> v1, Node<T> v2)
{
//v1或v2不是图的顶点
if (!IsNode(v1) || !IsNode(v2))
{
Debug.WriteLine("Node is not belong to Graph!");
return false;
}
//顶点v1与v2之间存在边
if (matrix[GetIndex(v1), GetIndex(v2)] == 1)
{
return true;
}
else //不存在边
{
return false;
}
}
}
无向图邻接矩阵类 GraphAdjMatrix<T>除了实现了接口 IGraph<T>中的方法 外,本身还有两个成员方法,一个是 IsNode,功能是判断一个顶点是否是无向 图的顶点,因为我们对不是图中的顶点进行处理是毫无意义的;一个是 GetIndex,功能是得到图的某个顶点在 nodes 数组中的序号,因为 matrix 数组 的下标是整数而不是顶点类型。 由于无向图邻接矩阵类 GraphAdjMatrix<T>中的成员方法的实现比较简单, 这里就不一一进行说明
6.2.2 邻接表
邻接表(Adjacency List)是图的一种顺序存储与链式存储相结合的存储结构, 类似于树的孩子链表表示法。顺序存储指的是图中的顶点信息用一个顶点数组来 存储,一个顶点数组元素是一个顶点结点,顶点结点有两个域,一个是数据域 data,存放与顶点相关的信息,一个是引用域 firstAdj,存放该顶点的邻接表的第 一个结点的地址。顶点的邻接表是把所有邻接于某顶点的顶点构成的一个表,它 是采用链式存储结构。所以,我们说邻接表是图的一种顺序存储与链式存储相结 合的存储结构。其中,邻接表中的每个结点实际上保存的是与该顶点相关的边或 弧的信息,它有两个域,一个是邻接顶点域 adjvex,存放邻接顶点的信息,实际 上就是邻接顶点在顶点数组中的序号;一个是引用域 next,存放下一个邻接顶点 的结点的地址。
顶点结点和邻接表结点的结构如图 6.9 所示

而对于网的邻接表结点还需要存储边上的信息(如权值),所以结点应增设一个域 info。网的邻接表结点的结构如图 6.10 所示。
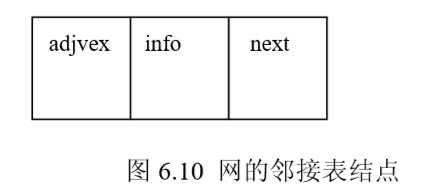
图 6.1(a)的邻接表如图 6.11 所示。

若无向图中有 n 个顶点和 e 条边,则它的邻接表需 n 个顶点结点和 2e 个邻
接表结点,在边稀疏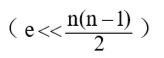 的情况下,用邻接表存储图比用邻接矩阵节 省存储空间,当与边相关的信息较多时更是如此。
的情况下,用邻接表存储图比用邻接矩阵节 省存储空间,当与边相关的信息较多时更是如此。
在无向图的邻接表中,顶点 vi 的度恰为第 i 个邻接表中的结点数;而在有向 图中,第 i 的邻接表中的结点数只是顶点 vi 的出度,为求入度,必须遍历整个邻 接表。在所有邻接表中其邻接顶点域的值为 i 的结点的个数是顶点 vi 的入度。有 时,为了便于确定顶点的入度或者以顶点 vi 为头的弧,可以建立一个有向图的 逆邻接表,即对每个顶点 vi 建立一个以 vi 为头的弧的邻接表。图 6.12 是图 6.1(b) 的邻接表和逆邻接表。
在建立邻接表或逆邻接表时,若输入的顶点信息即为顶点的编号,则建立邻 接表的时间复杂度为 O(n+e),否则,需要查找才能得到顶点在图中的位置,则 时间复杂度为 O(n*e)
在邻接表上很容易找到任一顶点的第一个邻接点和下一个邻接点。但要判定 任意两个顶点(vi 和 v j)之间是否有边或弧相连,则需查找第 i 个或 j 个邻接表, 因此,不如邻接矩阵方便。


下面以无向图邻接表类的实现来说明图的邻接表类的实现。 无向图邻接表的邻接表结点类 adjListNode<T>有两个成员字段,一个是 adjvex,存储邻接顶点的信息,类型是整型;一个是 next,存储下一个邻接表结 点的地址,类型是 adjListNode<T>。adjListNode<T>的实现如下所示
public class adjListNode<T>
{
private int adjvex; //邻接顶点
private adjListNode<T> next; //下一个邻接表结点
//邻接顶点属性
public int Adjvex
{
get
{
return adjvex;
}
set
{
adjvex = value;
}
}
//下一个邻接表结点属性
public adjListNode<T> Next
{
get
{
return next;
}
set
{
next = value;
}
}
//构造器
public adjListNode(int vex)
{
adjvex = vex; next = null;
}
}
无向图邻接表的顶点结点类 VexNode<T>有两个成员字段,一个 data,它存 储图的顶点本身的信息,类型是 Node<T>;一个是 firstAdj,存储顶点的邻接表的 第 1 个结点的地址,类型是 adjListNode<T>。VexNode<T>的实现如下所示。
public class VexNode<T>
{
private Node<T> data; //图的顶点
private adjListNode<T> firstAdj; //邻接表的第1个结点
//图的顶点属性
public Node<T> Data
{
get
{
return data;
}
set
{
data = value;
}
}
//邻接表的第1个结点属性
public adjListNode<T> FirstAdj
{
get
{
return firstAdj;
}
set
{
firstAdj = value;
}
}
//构造器
public VexNode()
{
data = null; firstAdj = null;
}
//构造器
public VexNode(Node<T> nd)
{
data = nd; firstAdj = null;
}
//构造器
public VexNode(Node<T> nd, adjListNode<T> alNode)
{
data = nd; firstAdj = alNode;
}
}
无向图邻接表类 GraphAdjList<T>有一个成员字段 adjList,表示邻接表数组, 数组元素的类型是 VexNode<T>。GraphAdjList<T>实现了接口 IGraph<T>中的方 法。与无向图邻接矩阵类 GraphAdjMatrix<T>一样,GraphAdjList<T>实现了两个 成员方法 IsNode 和 GetIndex。功能与 GraphAdjMatrix<T>一样。无向图邻接表 类 GraphAdjList<T>的实现如下所示。
public class GraphAdjList<T> : IGraph<T>
{
//邻接表数组
private VexNode<T>[] adjList;
//索引器
public VexNode<T> this[int index]
{
get
{
return adjList[index];
}
set
{
adjList[index] = value;
}
}
//构造器
public GraphAdjList(Node<T>[] nodes)
{
adjList = new VexNode<T>[nodes.Length]; for (int i = 0; i < nodes.Length; ++i)
{
adjList[i].Data = nodes[i]; adjList[i].FirstAdj = null;
}
}
//获取顶点的数目
public int GetNumOfVertex()
{
return adjList.Length;
}
//获取边的数目
public int GetNumOfEdge()
{
int i = 0;
//遍历邻接表数组
foreach (VexNode<T> nd in adjList)
{
adjListNode<T> p = nd.FirstAdj; while (p != null)
{
++i; p = p.Next
}
}
return i / 2;
}
//判断v是否是图的顶点
public bool IsNode(Node<T> v)
{
//遍历邻接表数组
foreach (VexNode<T> nd in adjList)
{
//如果v等于nd的data,则v是图中的顶点,返回true
if (v.Equals(nd.Data))
{
return true;
}
}
return false;
}
//获取顶点v在邻接表数组中的索引
public int GetIndex(Node<T> v)
{
int i = -1;
//遍历邻接表数组
for (i = 0; i < adjList.Length; ++i)
{
//邻接表数组第i项的data值等于v,则顶点v的索引为i
if (adjList[i].Data.Equals(v))
{
return i;
}
}
return i;
}
//在顶点v1和v2之间添加权值为v的边
public void SetEdge(Node<T> v1, Node<T> v2, int v)
{
//v1或v2不是图的顶点或者v1和v2之间存在边
if (!IsNode(v1) || !IsNode(v2) || IsEdge(v1, v2))
{
Debug.WriteLine("Node is not belong to Graph!"); return;
}
//权值不对
if(v != 1)
{
Debug.WriteLine("Weight is not right!"); return;
}
//处理顶点v1的邻接表
adjListNode<T> p = new adjListNode<T>(GetIndex(v2));
//顶点v1没有邻接顶点
if (adjList[GetIndex(v1)].FirstAdj == null)
{
adjList[GetIndex(v1)].FirstAdj = p;
}
//顶点v1有邻接顶点
else
{
p.Next = adjList[GetIndex(v1)].FirstAdj; adjList[GetIndex(v1)].FirstAdj = p;
}
//处理顶点v2的邻接表
p = new adjListNode<T>(GetIndex(v1));
//顶点v2没有邻接顶点
if (adjList[GetIndex(v2)].FirstAdj == null)
{
adjList[GetIndex(v2)].FirstAdj = p;
}
//顶点v1有邻接顶点
else
{
p.Next = adjList[GetIndex(v2)].FirstAdj; adjList[GetIndex(v2)].FirstAdj = p;
}
}
//删除顶点v1和v2之间的边
public void DelEdge(Node<T> v1, Node<T> v2)
{
//v1或v2不是图的顶点
if (!IsNode(v1) || !IsNode(v2))
{
Debug.WriteLine("Node is not belong to Graph!"); return;
}
//顶点v1与v2之间有边
if (IsEdge(v1, v2))
{
//处理顶点v1的邻接表中的顶点v2的邻接表结点
adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; adjListNode<T> pre = null;
while (p != null)
{
if (p.Adjvex != GetIndex(v2))
{
pre = p; p = p.Next;
}
}
pre.Next = p.Next;
//处理顶点v2的邻接表中的顶点v1的邻接表结点
p = adjList[GetIndex(v2)].FirstAdj; pre = null;
while (p != null)
{
if (p.Adjvex != GetIndex(v1))
{
pre = p; p = p.Next;
}
}
pre.Next = p.Next;
}
}
//判断v1和v2之间是否存在边
public bool IsEdge(Node<T> v1, Node<T> v2)
{
//v1或v2不是图的顶点
if (!IsNode(v1) || !IsNode(v2))
{
Debug.WriteLine("Node is not belong to Graph!"); return false;
}
adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; while (p != null)
{
if (p.Adjvex == GetIndex(v2))
{
return true;
}
p = p.Next;
}
return false;
}
}
下面对成员方法进行说明:
1、GetNumOfVertex() 算法思路:求无向图的顶点数比较简单,直接返回 adjList 数组的长度就 可以了。 算法实现如下:
public int GetNumOfVertex() { return adjList.Length; }2、GetNumOfEdge() 算法思路:求无向图的边数比求顶点数要复杂一些,需要求出所有顶点的 邻接表的结点的个数,然后除以 2。 算法实现如下:
public int GetNumOfEdge() { int i = 0; foreach (VexNode<T> nd in adjList) { adjListNode<T> p = nd.FirstAdj; while (p != null) { ++i; } } return i / 2; }3、SetEdge(Node<T> v1, Node<T> v2, int v)
算法思路:首先判断顶点 v1 和 v2 是否是图的顶点和 v1 和 v2 是否存在边。 如果 v1 和 v2 不是图的顶点和 v1 和 v2 存在边,不作处理。然后,判断 v 的值是 否为1,为1不作处理。否则,先分配一个邻接表结点,其adjvex域是v2在adjList 数组中的索引号,然后把该结点插入到顶点 v1 的邻接表的表头;然后再分配一 个邻接表结点,其 adjvex 域是 v1 在 adjList 数组中的索引号,然后把该结点插 入到顶点 v2 的邻接表的表头。
本算法是把邻接表结点插入到顶点邻接表的表头,当然,也可以插入到邻 接表的表尾,或者按照某种要求插入,只是对插入这个操作而言,在表的头部插 入是简单的,而本书在后面关于图的处理,如图的深度优先遍历和广度优先遍 历等,对图的顶点没有特殊要求,所以采用了在邻接表的头部插入结点。如果对 图的顶点有特殊要求,则需要按照一定的要求进行插入,需要修改这里的代码。 算法实现如下:
public void SetEdge(Node<T> v1, Node<T> v2, int v) { if (!IsNode(v1) || !IsNode(v2) || IsEdge(v1, v2)) { Debug.WriteLine("Node is not belong to Graph!"); return; } if (v != 1) { Debug.WriteLine("Weight is not right!"); return; } adjListNode<T> p = new adjListNode<T>(GetIndex(v2)); if (adjList[GetIndex(v1)].FirstAdj == null) { adjList[GetIndex(v1)].FirstAdj = p; } else { p.Next = adjList[GetIndex(v1)].FirstAdj; adjList[GetIndex(v1)].FirstAdj = p; } p = new adjListNode<T>(GetIndex(v1)); if (adjList[GetIndex(v2)].FirstAdj == null) { adjList[GetIndex(v2)].FirstAdj = p; } else { p.Next = adjList[GetIndex(v2)].FirstAdj; adjList[GetIndex(v2)].FirstAdj = p; } }4、DelEdge(Node<T> v1, Node<T> v2)
算法思路:首先判断顶点 v1 和 v2 是否是图的顶点以及 v1 和 v2 是否存在 边。如果 v1 和 v2 不是图的顶点或 v1 和 v2 不存在边,不作处理。否则,先在顶 点 v1 的邻接表中删除 adjVex 的值等于顶点 v2 在 adjList 数组中的序号结点, 然后删除顶点 v2 的邻接表中 adjVex 的值等于顶点 v1 在 adjList 数组中的序号 结点。
算法实现如下:
public void DelEdge(Node<T> v1, Node<T> v2) { if (!IsNode(v1) || !IsNode(v2)) { Console.WriteLine("Node is not belong to Graph!"); return; } if (IsEdge(v1, v2)) { adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; adjListNode<T> pre = null; while (p != null) { if (p.Adjvex != GetIndex(v2)) { pre = p; p = p.Next; } } pre.Next = p.Next; p = adjList[GetIndex(v2)].FirstAdj; pre = null; while (p != null) { if (p.Adjvex != GetIndex(v1)) { pre = p; p = p.Next; } } pre.Next = p.Next; } }5、IsEdge(Node<T> v1, Node<T> v2)
算法思路:首先判断顶点 v1 和 v2 是否是图的顶点。如果 v1 和 v2 不是图的 顶点,不作处理。否则,在顶点 v1(或 v2)的邻接表中查找是否存在 adjVex 的值等于 v2(或 v1)在 adjList 中的序号的结点,如果存在,则返回 true,否 则返回 false。
算法实现如下
public bool IsEdge(Node<T> v1, Node<T> v2) { if (!IsNode(v1) || !IsNode(v2)) { Console.WriteLine("Node is not belong to Graph!"); return false; } adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; while (p != null) { if (p.Adjvex == GetIndex(v2)) { return true; } p = p.Next; } return false; }















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









