







循环神经网络的概念
在了解循环神经网络之前,你一定了解过前馈神经网络和卷积神经网络,循环神经网络相对于这两种网络来说可能要更有“个性”一些。循环神经网络的独特之处就在于它不仅考虑到了当前的输入,而且对前面输入的内容有记忆功能,可以说其他神经网络的隐藏层是无连接的,而循环神经网络的隐藏层之间是有连接的,隐藏层的输入不仅包含输入层的输出,同时也包含了上一时刻隐藏层的输出。
循环神经网络的结构如下图所示:

如图所示Xt代表输入,A便是隐藏层,由于隐藏层的输入要包含着上一时刻隐藏层的输出,也就构成了图中的循环结构,ht表示输出。
如果对于上图中表示的神经网络还是不能很好的理解,我们可以把它拆开来看:

拆开后可以认为是相同网络的多重叠加结构,每一个网络都把消息传给他的继承者。
具体的细节结构图如下所示:


参数说明如下:
- xt:t时刻的输入
- st:t时刻的隐藏状态
- f:激活函数(一般用tanh和ReLu)
- U,V,W:网络参数(和前馈网络有所不同,RNN共享同一组网络参数)
- g:激活函数
BPTT算法
通过上面的细节结构图,我们可以得到RNN的前向传播过程,那RNN中的网络参数U,V,W又是怎么进行更新的呢
每一次的输出值Ot都会产生一个误差值Et,总的误差就可以表示为:

那么我们的损失函数可以用交叉熵损失函数或者平方差损失函数来表示。
由于神经网络需要考虑输入的时间顺序,所以在进行反向传播的时候我们也要考虑时间带来的影响,所以我们把这种由BP网络更改后的算法叫做Backpropagation Through Time(BPTT),该算法是将输出端的误差进行反向传递,并通过梯度下降法进行更新。
BPTT算法的推导可以参考:https://www.cnblogs.com/wacc/p/5341670.html
双向RNN(BRNN)的结构介绍
在传统的RNN中,我们只考虑到了当前输入的前一输入,即只考虑到了“上文”,并没有考虑到之后的内容。这样可能会造成错过一些重要的信息,使得我们得到的信息不够准确。双向RNN不仅从前往后(如下图黄色实箭头)保留该输入前面的输入的重要信息,而且从后往前(如下图黄色虚箭头)去保留该输入后面的输入的重要信息,然后基于这些重要信息进行预测该输入。双向RNN模型如下:

双向RNN可以用如下的公式来表示:
正向RNN:
反向RNN:
输出:![y=g(V[s_t_1,s_t_2])](https://i-blog.csdnimg.cn/blog_migrate/dabbe1a126745ade5a1d0a9962af3168.gif)
注:由于我们得了前文的重要信息St1和后文的重要信息St2,所以我们得到的重要信息是二者拼接的结果即:[st1,st2]。
深层RNN(DRNN)的简单介绍
深层RNN网络是在RNN模型多了几个隐藏层,是因为考虑到当信息量太大的时候一次性保存不下所有重要信息,通过多个隐藏层可以保存更多的重要信息,正如我们看电视剧的时候也可能重复看同一集记住更多关键剧情。同样的,我们也可以在双向RNN模型基础上加多几层隐藏层得到深层双向RNN模型。

注:每一层循环体中参数是共享的,但是不同层之间的权重矩阵是不同的。
长短期记忆网络(LSTM)极其变体
LSTM是一种特殊的RNN,它能够学习长时间依赖。假设我们在看一个长约两个小时的电影,在看到一小时的时候,你可能只能回忆起10分钟之前的情节,这就是RNN所能带来的记忆功能,而LSTM可以看做是对这个记忆的升级版,虽然不能够记得所有的剧情,但是能过记忆从开始到现在的重要情节,这就是LSTM所带来的升级后的记忆功能。
下面通过对比标准RNN来讲解一下LSTM:
标准RNN:

可以看出标准RNN中重复的模块只包含了单一的层(tanh)。
LSTM:

从外形上来看的话,二者并没有什么不同,只不过LSTM的每个重复模块中含有四个层(每个黄色方块算一个层)。
下面具体来讲解一下LSTM中每个部件的作用。
LSTM的核心思想是细胞状态,直接在整个链上运行,只有一些少量的线性交互,信息在链上流动保持不变会很容易。
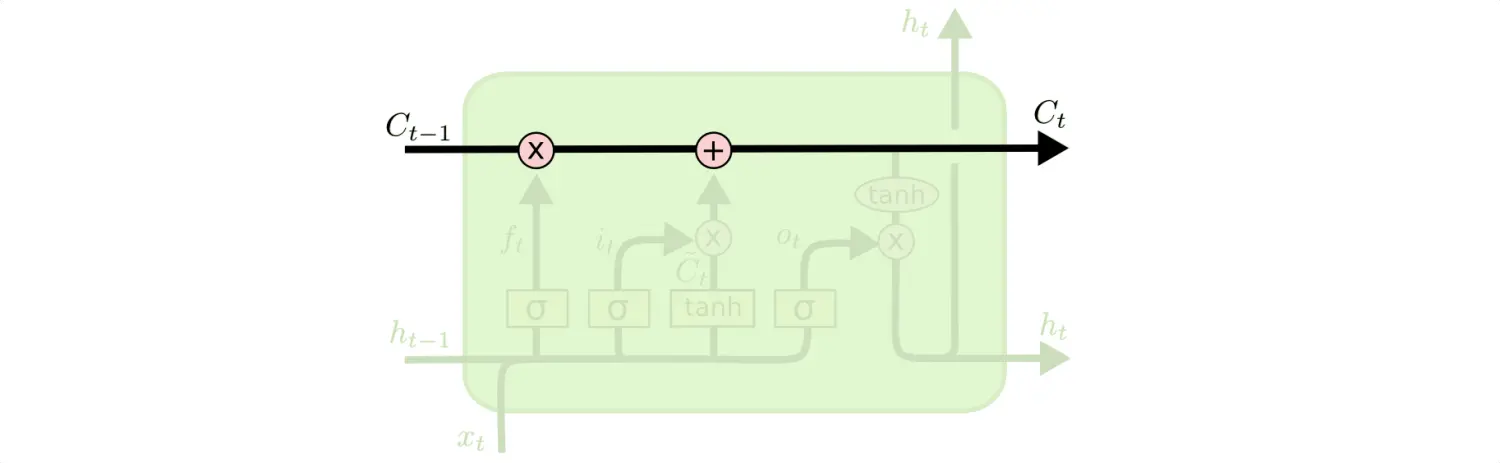
LSTM的主要结构由“门”构成,门可以用来选择让信息通过或者不通过(就像门电路一个原理),LSTM中的门主要包含一个sigmoid函数和一个pointwise乘法操作。

我们都知道sigmoid的输出范围是0-1,利用该函数作为门就可以很好的控制有多少信息可以通过,0代表没有信息可以通过,1代表所有的信息都可以通过,LSTM中一共用下面的三个门来表述各种状态。
遗忘门
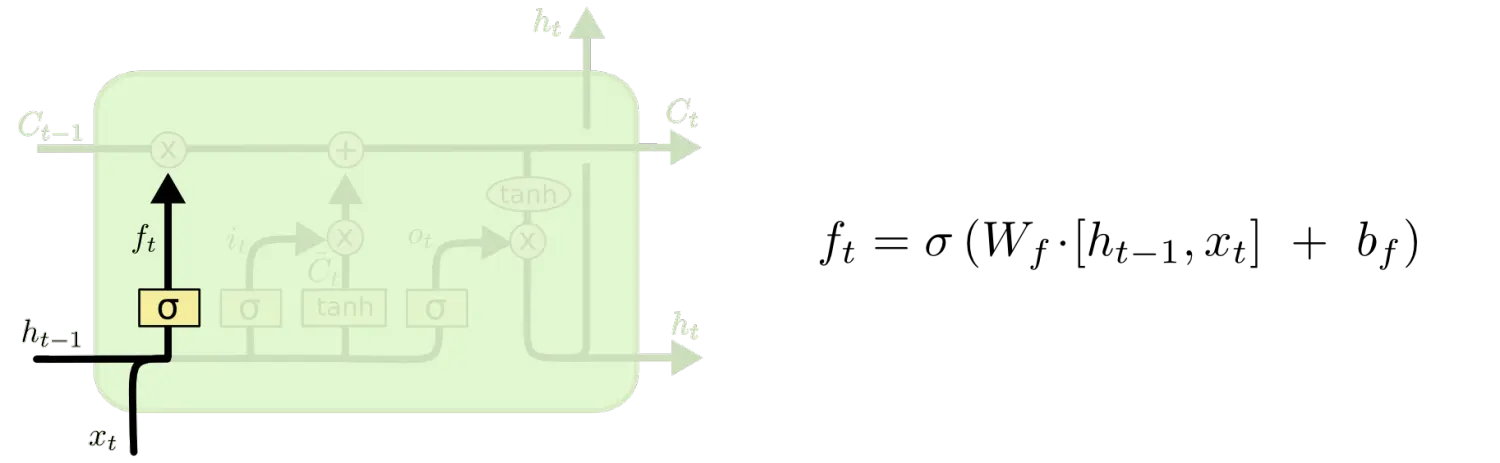
该门放在整个模块的最前端,该门用来决定我们丢弃掉什么信息,该门用和
 作为输入,在
作为输入,在单元输出一个介于0和1之间的数,0代表完全遗忘,1代表完全保留。
输入门
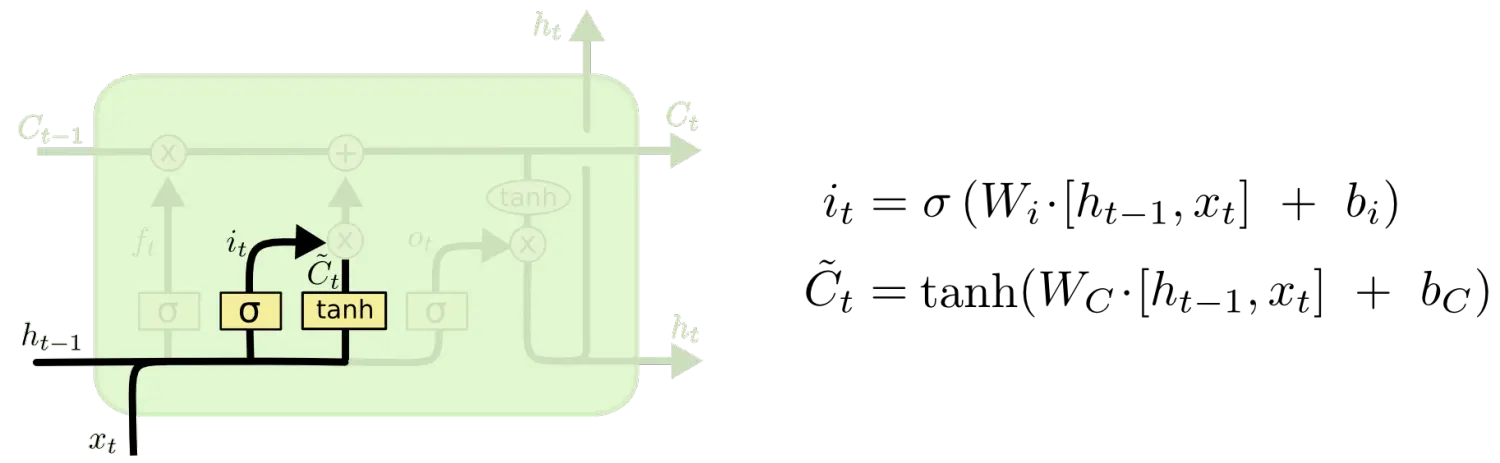
输入门是要决定单元中要存储何种信息,它由两个部分组成。首先一个sigmoid函数决定着我们要更新哪些值,其次一个tanh函数创建一个新的候选向量 ,可以加入状态机中,下一步将结合两者(遗忘门和输出门)产生状态的更新。
,可以加入状态机中,下一步将结合两者(遗忘门和输出门)产生状态的更新。
状态更新
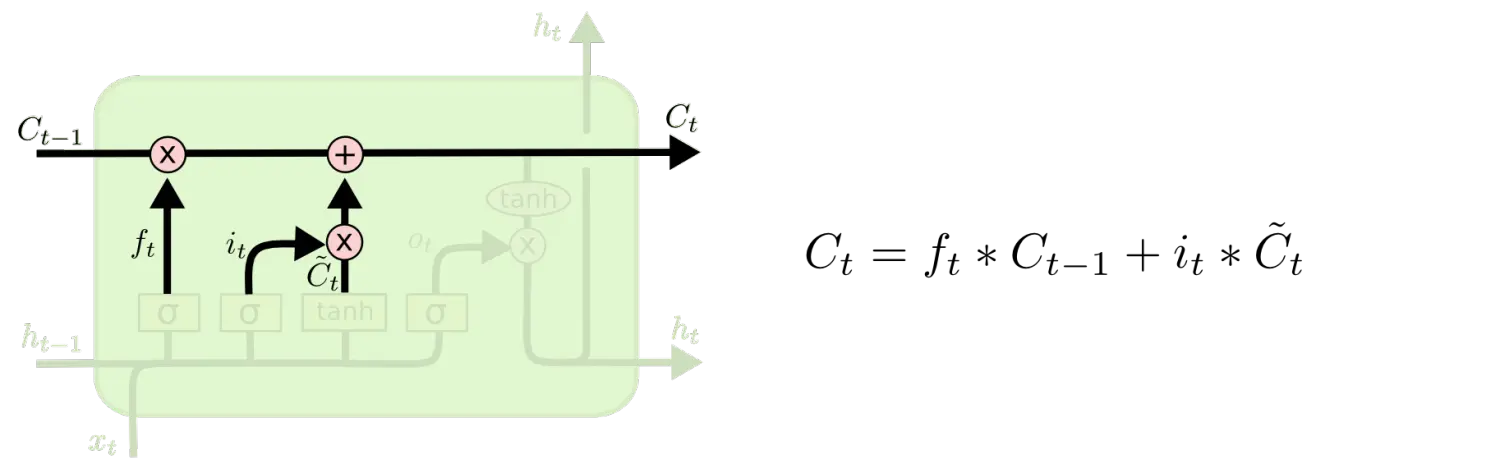
这一步主要是将旧的状态更新成
 。这里把旧的状态乘以
。这里把旧的状态乘以 ,用来遗忘我们在遗忘门中决定忘记的信息,紧接着加上
,用来遗忘我们在遗忘门中决定忘记的信息,紧接着加上 。这就是新的候选值,然后我们再根据决定更新状态的程度来设置缩放系数。
。这就是新的候选值,然后我们再根据决定更新状态的程度来设置缩放系数。
输出门
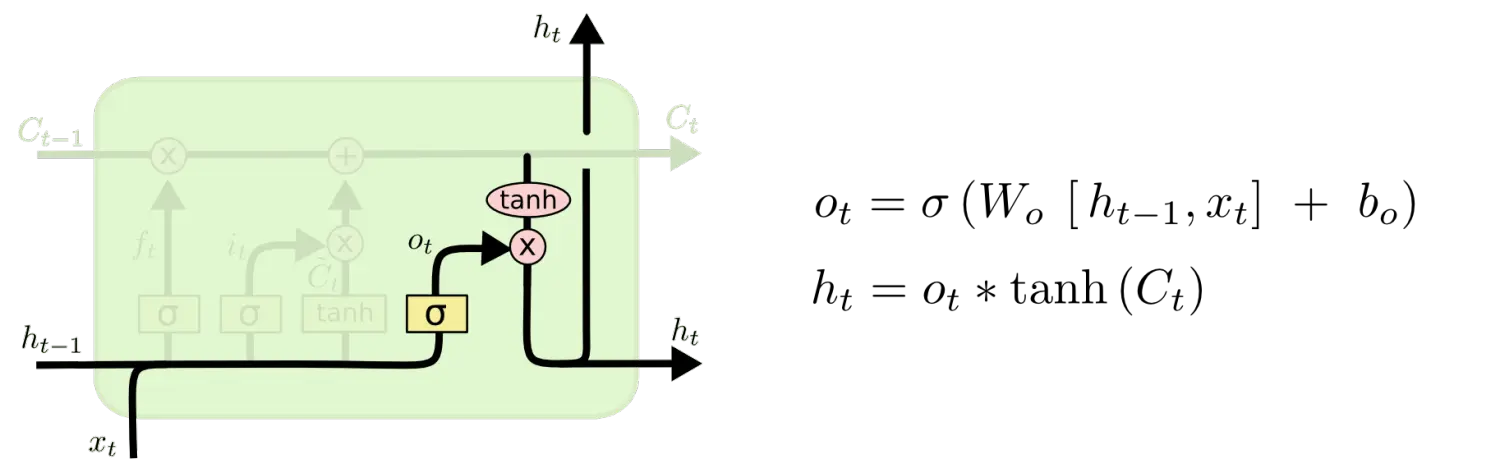
更新了状态之后,我们就要决定最终的输出了,首先用一个Sigmoid函数来决定输出细胞状态的哪个部分,接着用tanh处理细胞状态(将状态映射到-1和1之间),最后将其与Sigmoid门的输出值相乘,从而输出最终的值。
举个例子:在语言模型中,因为就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否是代词、是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
LSTM变体
(一)第一种变体是增加了窥视孔连接(peephole connection),也就是让门电路也接受细胞状态的输入。
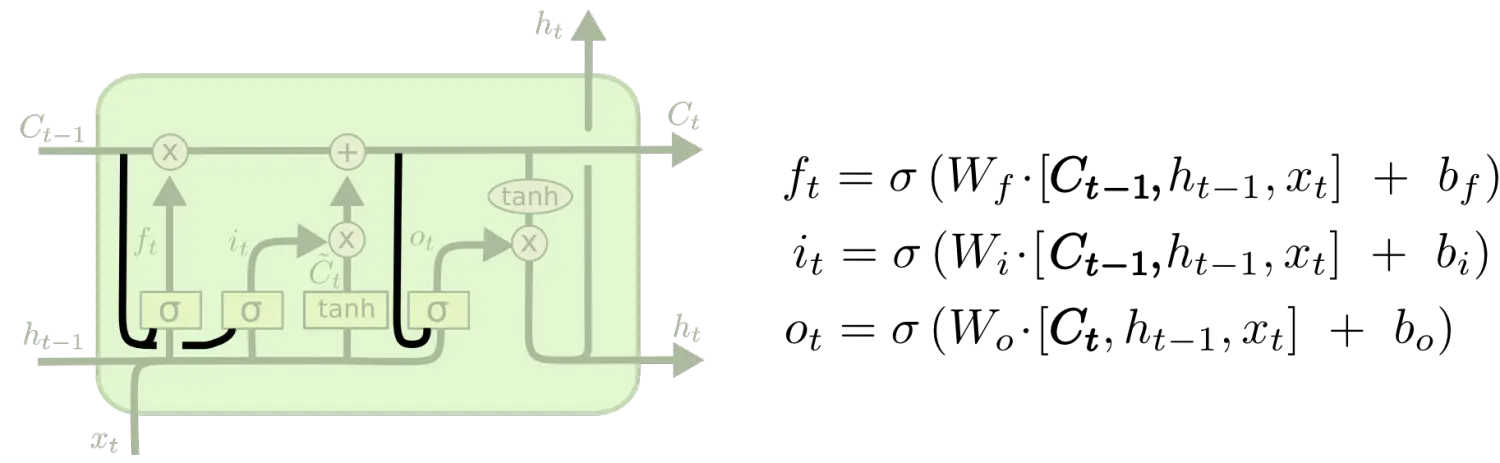
(二)第二种变体是使用了配对遗忘与输入门,与之前分别决定遗忘与添加信息不同,我们同时决定两者,只有我们需要输入一些内容的时候我们才会忘记,只有当早前信息被忘记之后我们才会输入。
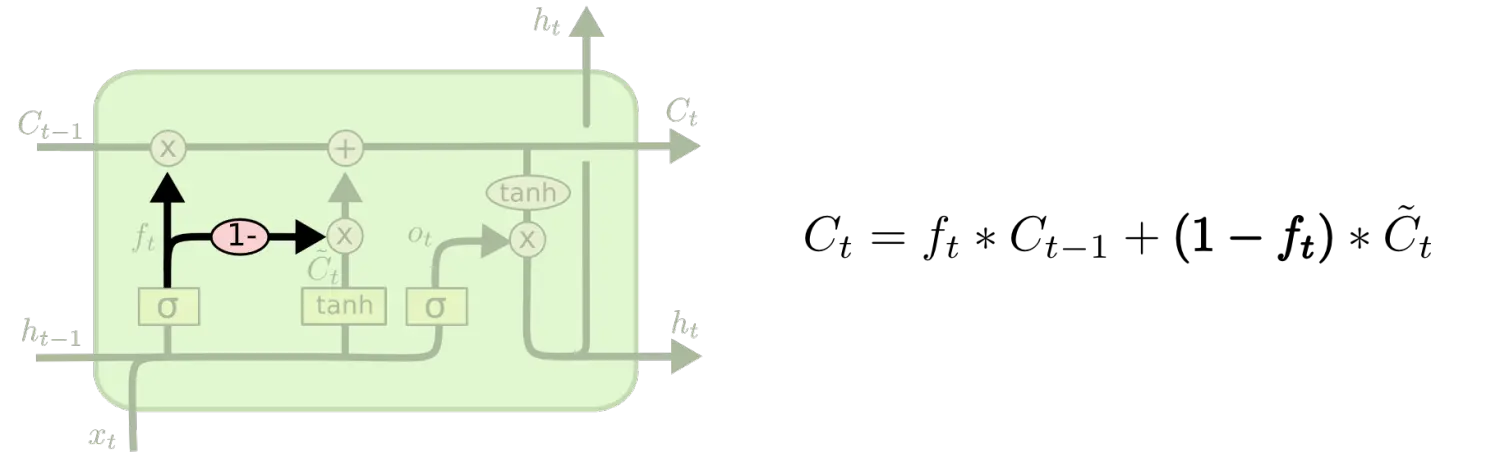
(三)GRU是一个更好的变体,该模型将输入门和遗忘门组合成了一个单独的“更新门”,同时合并了细胞状态和隐含状态,也做了一下其他的修改,最终的模型比标准的 LSTM 模型要简单,是当前非常流行的变体。

















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











