










这篇博文不涉及理论知识,主要通过一个完整的深度学习模型训练流程,直观地了解深度学习图像分类任务。有关理论的部分,之前几篇博文已经涉及基础部分,之后也会对一些理论进行补充。
本文将结合代码,主要介绍三部分内容:
1. 数据集划分
2. 模型训练
3. 模型评估
本文集成了深度学习图像处理从数据集划分到模型训练最后到模型评估的一个完整框架。旨在方便从事相关学术研究的伙伴,进行实验对比。
1. 数据集划分
1.1 数据集文件结构

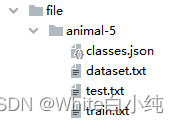
数据集结构如上图所示,共分三级目录。根目录:dataset,一级子目录:animal-5,二级子目录:5种动物的类别。每个动物类别的文件夹中,保存对应类别的图片。
1.2 数据集划分
数据集划分的步骤:
(1)读取数据集中所有图片的路径。
(2)随机选取图片,将数据集按照4:1的比例,划分为训练集和测试集。
(3)标签映射,将数据集标签映射到json文件中保存。
1.3 代码
代码文件名称:split_data.py
完整代码:
import os
import random
import json
import argparse
def split_data(dataset_root, txt_save_root, ratio):
assert 0 <= ratio <= 1, "ratio must be between 0 and 1"
# 创建保存路径文件夹
os.makedirs(txt_save_root, exist_ok=True)
# 获取所有文件路径
all_files = []
for path, _, files in os.walk(dataset_root):
for file in files:
all_files.append(os.path.join(path, file))
# 将文件路径保存到 dataset.txt
with open(f'{txt_save_root}/dataset.txt', 'w') as f:
for file_path in all_files:
f.write(file_path + '\n')
print(f'数据集路径保存成功到:{txt_save_root}/dataset.txt')
# 随机分割为训练集和测试集
random.shuffle(all_files)
split_index = int(ratio * len(all_files))
train_files = all_files[:split_index]
test_files = all_files[split_index:]
# 将训练集和测试集的路径分别保存
with open(f'{txt_save_root}/train.txt', 'w') as f:
for file_path in train_files:
f.write(file_path + '\n')
print(f'训练集路径保存成功到:{txt_save_root}/train.txt')
with open(f'{txt_save_root}/test.txt', 'w') as f:
for file_path in test_files:
f.write(file_path + '\n')
print(f'测试集路径保存成功到:{txt_save_root}/test.txt')
def get_paths_and_labels(filename):
paths_and_labels = []
with open(filename, 'r') as file:
for line in file:
path = line.strip() # 移除行尾的换行符
label = get_label_from_path(path)
paths_and_labels.append((path, label))
return paths_and_labels
def get_label_from_path(image_path):
parts = image_path.split('\\')
label = parts[-2] if len(parts) > 1 else None
return label
def create_and_save_label_mapping(file_paths_and_labels, json_file):
unique_labels = sorted(set(label for _, label in file_paths_and_labels))
label_to_index = {label: index for index, label in enumerate(unique_labels)}
with open(json_file, 'w') as file:
json.dump(label_to_index, file)
if __name__ == '__main__':
# 创建 ArgumentParser 对象
parser = argparse.ArgumentParser(description="Process some paths.")
# 添加参数
parser.add_argument('--dataset_root', default='dataset/animal-5',
type=str, help='数据集根路径')
parser.add_argument('--txt_save_root', default='file/animal-5',
type=str, help='txt文件保存路径')
parser.add_argument('--ratio', default=0.8, type=float, help='训练集的比例')
# 解析参数
args = parser.parse_args()
dataset_root = args.dataset_root
txt_save_root = args.txt_save_root
ratio = args.ratio
# 划分数据集
split_data(dataset_root, txt_save_root, ratio)
# 获取数据集标签
file_paths_and_labels = get_paths_and_labels(f'{txt_save_root}/train.txt')
print(f'成功获取数据集标签')
# 记录数据集标签映射
create_and_save_label_mapping(file_paths_and_labels, f'{txt_save_root}/classes.json')
print(f'已保存数据集标签映射到:{txt_save_root}/classes.json')1.4 代码使用方法
parser.add_argument('--dataset_root', default='dataset/animal-5',
type=str, help='数据集根路径')
parser.add_argument('--txt_save_root', default='file/animal-5',
type=str, help='txt文件保存路径')
parser.add_argument('--ratio', default=0.8, type=float, help='训练集的比例')
运行代码时,只需要更改上述参数中的 default 部分。--dataset_root为数据集根路径。--txt_save_root为txt文件保存路径。--ratio为训练集占数据集的比例,大于0,小于1。
上述代码,运行成功后,结果如下:

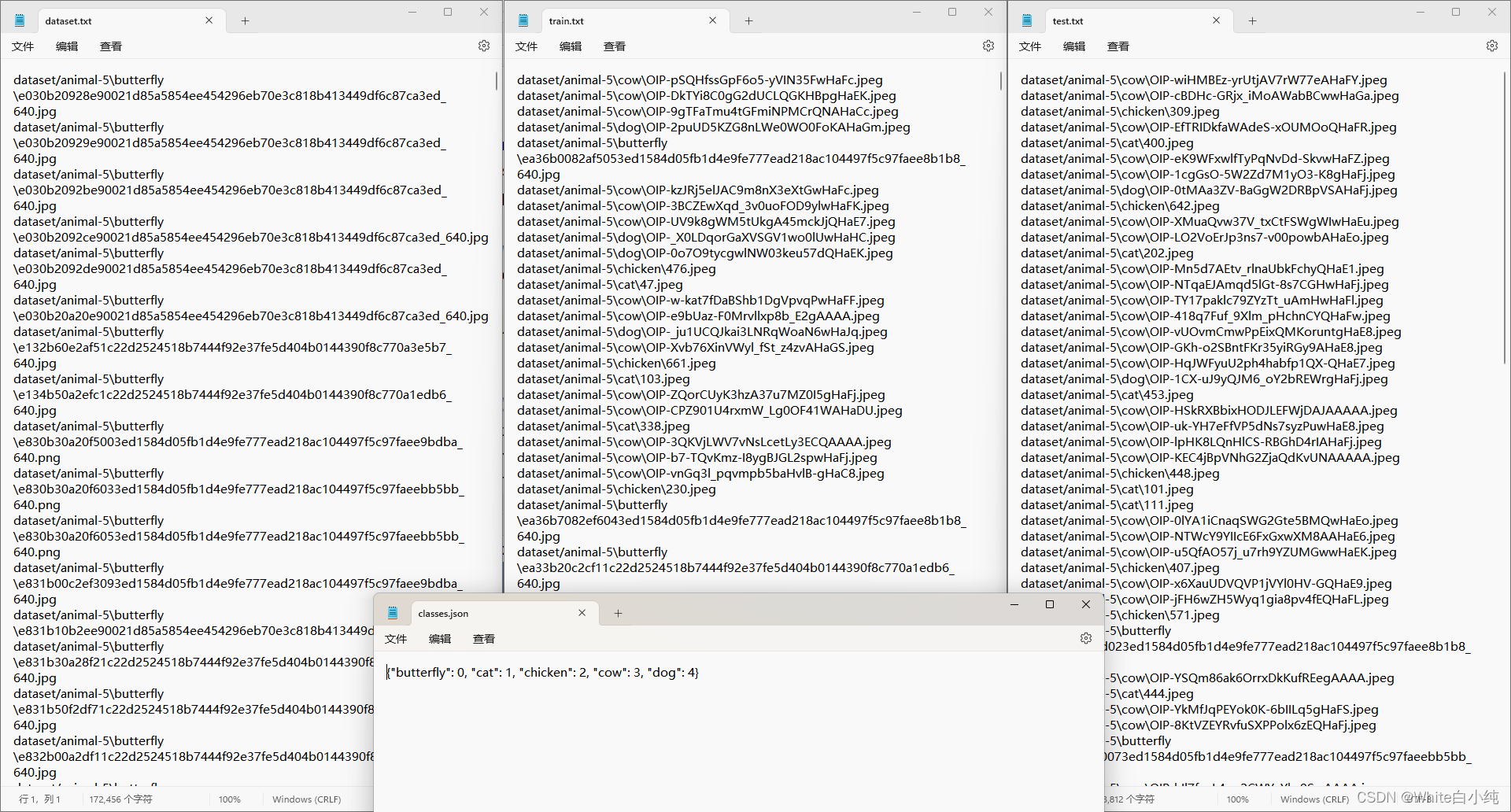
其中,dataset.txt保存了数据集所有图片的路径,train.txt保存了所有训练集图片路径,test.txt保存了所有测试集图片路径,classes.json保存了该数据集标签的映射。
上述四个文件部分内容展示如下:
2. 模型训练
2.1 模型训练步骤
(1)环境准备和参数解析
- 导入必要的库和模块,如
torch,torchvision,sklearn.model_selection等。 - 定义一个解析命令行参数的
argparse.ArgumentParser实例,用于接收从命令行传入的参数,如训练集路径、模型保存路径、批大小、学习率、是否使用预训练模型等。
(2)数据准备
- 使用给定的文件路径和JSON文件,加载训练图像的路径和对应的标签映射。
- 将数据集划分为训练集和验证集。
- 定义数据预处理步骤,包括图像的尺寸调整、随机裁剪、归一化等。
- 创建
CustomDataset类的实例,用于加载和转换图像数据。 - 使用
DataLoader对训练集和验证集进行批处理,准备输入模型的数据。
(3)模型准备
- 根据命令行参数选择不同的模型架构,如ResNet18、ResNet50、MobileNetV2等,并根据是否使用预训练模型进行相应配置。
- 将模型移至适当的设备(CPU或GPU)。
(4)训练与验证
- 定义损失函数(交叉熵损失)和优化器(Adam优化器)。
- 对模型进行多个周期的训练和验证:
- 训练阶段:模型在训练模式下运行。对每个批次的数据,执行前向传播、计算损失、执行反向传播并更新模型参数。
- 验证阶段:模型在评估模式下运行,计算验证集上的损失和准确率,以评估模型的性能。
- 在每个周期结束时,如果验证准确率有所提高,则保存当前最佳模型。
- 为了便于模型的恢复和进一步训练,每隔一定周期保存模型的检查点。
(5)结果保存
- 将训练过程中得到的最佳模型保存到指定路径。
- 可选地,保存训练过程中的一些检查点,以便未来可以从特定的周期恢复训练。
2.2 代码
以下是一个动物图像分类的训练脚本,使用PyTorch框架。它包含了从数据预处理到模型训练、验证以及保存模型的完整流程。
文件名:train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms, models
from sklearn.model_selection import train_test_split
import os
from split_data import get_label_from_path
import json
from tqdm import tqdm
from PIL import Image
import argparse
def resize_and_pad(image, target_height=224, target_width=224):
# 将PIL Image对象直接用于获取其尺寸
original_width, original_height = image.size
# 计算宽度和高度的缩放比例
scale = min(target_width / original_width, target_height / original_height)
# 应用等比例缩放
new_width, new_height = int(original_width * scale), int(original_height * scale)
resized_image = image.resize((new_width, new_height), Image.Resampling.LANCZOS)
# 创建填充用的背景图像
if image.mode == 'L': # 灰度图
mode = 'L'
elif image.mode in ['RGB', 'RGBA']: # RGB或RGBA彩色图
mode = image.mode
else:
raise ValueError("Unsupported image mode.")
# 创建一个新的空白图片用于填充
padded_image = Image.new(mode, (target_width, target_height))
# 计算填充位置
start_x = (target_width - new_width) // 2
start_y = (target_height - new_height) // 2
# 将缩放后的图像粘贴到新的背景图中
padded_image.paste(resized_image, (start_x, start_y))
return padded_image
class CustomDataset(Dataset):
def __init__(self, file_paths, label_mapping, transform=None):
self.file_paths = file_paths
self.label_mapping = label_mapping
self.transform = transform
def __len__(self):
return len(self.file_paths) # 返回数据集中的样本数量
def __getitem__(self, idx):
image_path = self.file_paths[idx]
image = Image.open(image_path).convert('RGB')
image = resize_and_pad(image, 224, 224)
label_str = get_label_from_path(image_path)
label = self.label_mapping[label_str] # 使用映射转换标签
if self.transform:
to_tensor = transforms.ToTensor()
image = to_tensor(image)
return image, torch.tensor(label), image_path
def train(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels, image_path in tqdm(train_loader, desc="Training"):
images = images.float() # 将输入数据转换为FloatTensor
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return running_loss / len(train_loader), accuracy
def validate(model, val_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels, image_path in tqdm(val_loader, desc="Validation"):
images = images.float() # 将输入数据转换为FloatTensor
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return running_loss / len(val_loader), accuracy
def main(args):
# 解析参数
train_path = args.train_path
json_path = args.json_path
save_path = args.save_path
lr = args.lr
batch_size = args.batch_size
pretrained = args.pretrained
model_name = args.model
# 创建保存路径
os.makedirs(save_path, exist_ok=True)
# 读取数据
with open(train_path, 'r') as file:
file_paths = [line.strip() for line in file.readlines()]
# 加载标签映射
with open(json_path, 'r') as file:
label_mapping = json.load(file)
img_size = {"s": [224, 224], # train_size, val_size
"m": [384, 480],
"l": [384, 480]}
num_model = "s"
# 划分训练集和验证集
train_paths, val_paths = train_test_split(file_paths, test_size=0.1)
# 数据预处理
transform = {
"train": transforms.Compose([
transforms.RandomResizedCrop(img_size[num_model][0]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
"val": transforms.Compose([transforms.Resize(img_size[num_model][1]),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}
# 创建数据集和数据加载器
train_dataset = CustomDataset(train_paths, label_mapping, transform=transform['train'])
val_dataset = CustomDataset(val_paths, label_mapping, transform=transform['val'])
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 定义模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if model_name == 'resnet50':
model = models.resnet50(pretrained=pretrained) # resnet50
elif model_name == 'resnet18':
model = models.resnet18(pretrained=pretrained) # resnet18
elif model_name == 'resnet34':
model = models.resnet34(pretrained=pretrained) # resnet34
elif model_name == 'resnet101':
model = models.resnet101(pretrained=pretrained) # resnet101
elif model_name == 'mobilenetv2':
model = models.mobilenet_v2(pretrained=pretrained) # mobilenetv2
elif model_name == 'convnext':
model = models.convnext_base(pretrained=pretrained) # convnext_base
elif model_name == 'efficientnetv2':
model = models.efficientnet_v2_s(pretrained=pretrained) # efficientnet_v2_s
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 训练和验证
epochs = args.epochs
best_val_accuracy = 0.0 # 用于跟踪最高验证准确率
for epoch in range(epochs):
train_loss, train_accuracy = train(model, train_loader, criterion, optimizer, device)
val_loss, val_accuracy = validate(model, val_loader, criterion, device)
print()
print(f"Epoch {epoch + 1}/{epochs} - "
f"Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.2f}% - "
f"Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.2f}%")
# 如果当前验证准确率高于之前的最高准确率,则保存模型
if val_accuracy >= best_val_accuracy:
best_val_accuracy = val_accuracy
torch.save(model.state_dict(), f'{save_path}/best_model.pt')
print(f"\nValidation accuracy improved to {val_accuracy:.2f}%. Saving model to {save_path}/best_model.pt")
if (epoch + 1) % 10 == 0 :
checkpoint_path = f'{save_path}/model_epoch_{epoch + 1}.pt'
torch.save(model.state_dict(), checkpoint_path)
print(f"Saved model checkpoint to '{checkpoint_path}' at epoch {epoch + 1}.")
if __name__ == '__main__':
# 创建 ArgumentParser 对象
parser = argparse.ArgumentParser(description="Process some paths.")
# 添加参数
parser.add_argument('--train_path', default='file/animal-5/train.txt',
type=str, help='保存训练集路径的txt文件路径')
parser.add_argument('--json_path', default='file/animal-5/classes.json',
type=str, help='映射标签的json文件路径')
parser.add_argument('--save_path', default='result/resnet18',
type=str, help='模型保存路径')
parser.add_argument('--batch_size', default=32, type=int)
parser.add_argument('--lr', default=2e-4, type=float)
parser.add_argument('--pretrained', default=False, type=bool, help='是否使用预训练模型')
parser.add_argument('--ratio', default=0.1, type=float, help='划分验证集的数据比例')
parser.add_argument('--epochs', default=100, type=int, help='训练总次数')
parser.add_argument('--model', default='resnet18', type=str,
help='resnet18, resnet50, resnet101, ')
args = parser.parse_args()
main(args)2.3 代码使用方法
根据实际需要和代码提示,对以下参数的default进行更改即可。
(1)参数列表
-
--train_path:指定保存训练集图片路径的文本文件的路径。默认值为file/animal-5/train.txt。这个文件应该包含所有训练图像的路径,每个路径占一行。 -
--json_path:指定包含标签和对应类别映射的JSON文件的路径。默认值为file/animal-5/classes.json。这个文件用于将图像的标签(例如类别名称)映射为模型训练时使用的整数索引。 -
--save_path:指定训练完成的模型保存位置的路径。默认值为result/resnet18。如果训练过程中的验证准确率超过了之前的最高纪录,最佳模型将被保存到这个位置。 -
--batch_size:训练和验证过程中的批处理大小。默认值为32。这决定了每次前向和反向传播过程中将处理多少图像。 -
--lr(学习率):优化器使用的学习率。默认值为0.0002。学习率决定了模型参数在每次迭代中更新的幅度。 -
--pretrained:是否使用预训练的模型作为起点进行训练。默认为False。如果设置为True,模型将使用在大型数据集(如ImageNet)上预先训练得到的权重,这通常可以帮助改进模型的性能。 -
--ratio:用于从训练数据中划分验证集的数据比例。默认值为0.1,即10%的训练数据将被用作验证集。 -
--epochs:总训练周期数。默认值为100。这决定了整个训练集将被遍历多少次。 -
--model:选择使用的模型架构。默认为resnet18。该参数允许用户根据需要选择不同的模型架构,例如resnet50,resnet101等。
(2)使用命令
基于默认参数运行脚本的示例命令如下:
python train.py如果需要自定义参数,可以在命令后添加相应的选项,如下所示:
python train.py --train_path mypath/train.txt --json_path mypath/classes.json --save_path myresult --batch_size 64 --lr 0.001 --pretrained True --epochs 50 --model resnet50
训练过程效果图:

3. 模型评估
3.1 模型评估步骤
(1)参数解析
- 通过
argparse库,脚本首先定义了一系列命令行参数,允许用户指定测试数据集路径、类别标签的JSON文件路径、模型保存路径、结果输出路径、是否使用预训练模型以及模型的类型。
(2)环境设置
- 确定模型运行的设备(CPU或GPU)并设置好,确保评估过程能够利用硬件加速。
(3)模型加载
- 根据用户指定的模型类型和是否使用预训练权重,加载相应的模型架构。支持多种模型,如ResNet18、ResNet50等。
- 遍历模型保存路径下所有指定的模型检查点文件,对每个模型进行加载和评估。
(4)测试数据准备
- 读取测试集图像路径列表和标签映射文件。
- 定义图像预处理流程,包括尺寸调整、归一化等。
- 使用
CustomDataset类(从train模块导入)创建测试数据集,然后使用DataLoader准备用于批量评估的测试数据。
(5)模型评估
- 对每个加载的模型,遍历测试数据集,预测图像标签,并收集所有预测结果和真实标签。
- 计算混淆矩阵以及其他关键性能指标,如准确率、精确度、召回率和F1得分。
(6)结果输出
- 打印混淆矩阵和评估指标。
- 将混淆矩阵和评估指标保存为CSV文件,方便后续查看和分析。
3.2 代码
import os
import torch
from torch.utils.data import DataLoader, Dataset
import json
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
import pandas as pd
from torchvision import transforms, models
from train import CustomDataset
from tqdm import tqdm
import argparse
def evaluate(model, test_loader, device, label_mapping):
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for images, labels, img_paths in tqdm(test_loader, desc="Test"):
images = images.float() # 将输入数据转换为FloatTensor
images = images.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 计算混淆矩阵
cm = confusion_matrix(all_labels, all_preds)
return cm, all_labels, all_preds
def main(args):
# 解析参数
test_path = args.test_path
json_path = args.json_path
model_path = args.model_path
pretrained = args.pretrained
model_name = args.model
result_path = args.result_path
os.makedirs(result_path, exist_ok=True)
# 加载模型
if model_name == 'resnet50':
model = models.resnet50(pretrained=pretrained) # resnet50
elif model_name == 'resnet18':
model = models.resnet18(pretrained=pretrained) # resnet18
elif model_name == 'resnet34':
model = models.resnet34(pretrained=pretrained) # resnet34
elif model_name == 'resnet101':
model = models.resnet101(pretrained=pretrained) # resnet101
elif model_name == 'mobilenetv2':
model = models.mobilenet_v2(pretrained=pretrained) # mobilenetv2
elif model_name == 'convnext':
model = models.convnext_base(pretrained=pretrained) # convnext_base
elif model_name == 'efficientnetv2':
model = models.efficientnet_v2_s(pretrained=pretrained) # efficientnet_v2_s
paths_list = [
'best_model.pt',
'model_epoch_10.pt', 'model_epoch_20.pt',
'model_epoch_30.pt', 'model_epoch_40.pt',
'model_epoch_50.pt', 'model_epoch_60.pt',
'model_epoch_70.pt', 'model_epoch_80.pt',
'model_epoch_90.pt', 'model_epoch_100.pt',
]
for _ in paths_list:
path = f'{model_path}/{_}'
# 加载保存的权重
model.load_state_dict(torch.load(path))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 加载测试集
with open(test_path, 'r') as file:
test_paths = [line.strip() for line in file]
# 加载标签映射
with open(json_path, 'r') as file:
label_mapping = json.load(file)
# 设置数据转换
transform = transforms.Compose([
transforms.Resize((224, 224)), # 示例尺寸,根据需要调整
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# 创建测试数据集和数据加载器
test_dataset = CustomDataset(test_paths, label_mapping, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 评估模型
conf_matrix, labels, preds = evaluate(model, test_loader, device, label_mapping)
# 打印混淆矩阵
print(f'{path}: ')
print("Confusion Matrix:")
print(conf_matrix)
# 计算评估指标
accuracy = accuracy_score(labels, preds)
precision = precision_score(labels, preds, average='macro')
recall = recall_score(labels, preds, average='macro')
f1 = f1_score(labels, preds, average='macro')
# 创建包含混淆矩阵的DataFrame
conf_matrix_df = pd.DataFrame(conf_matrix, columns=label_mapping.keys(), index=label_mapping.keys())
conf_matrix_df.index.name = 'Actual'
conf_matrix_df.columns.name = 'Predicted'
# 将评估指标添加到混淆矩阵的下方
metrics_df = pd.DataFrame({
"Metric": ["Accuracy", "Precision", "Recall", "F1 Score"],
"Value": [accuracy, precision, recall, f1]
})
# 保存混淆矩阵和评估指标到CSV文件
combined_df = pd.concat([conf_matrix_df, metrics_df], axis=0)
combined_df.to_csv(f"{result_path}/{_}_confusion_matrix.csv", index=True)
# 打印指标
print(metrics_df)
if __name__ == '__main__':
# 创建 ArgumentParser 对象
parser = argparse.ArgumentParser(description="Process some paths.")
# 添加参数
parser.add_argument('--test_path', default='file/animal-5/test.txt',
type=str, help='保存训练集路径的txt文件路径')
parser.add_argument('--json_path', default='file/animal-5/classes.json',
type=str, help='映射标签的json文件路径')
parser.add_argument('--model_path', default='result/resnet18',
type=str, help='模型保存路径')
parser.add_argument('--result_path', default='result/resnet18_csv',
type=str, help='保存混淆矩阵和评估结果到csv文件的路径')
parser.add_argument('--pretrained', default=False, type=bool, help='是否使用预训练模型')
parser.add_argument('--model', default='resnet18', type=str,
help='resnet18, resnet50, resnet101')
args = parser.parse_args()
main(args)3.3 代码使用方法
(1)参数详解
<script_name>.py:替换为脚本的文件名。--test_path <path_to_test_txt>:指向一个文本文件的路径,该文件包含了测试集图像的路径。每个路径应该占一行。--json_path <path_to_classes_json>:指向一个JSON文件的路径,该文件包含了标签到类别的映射。--model_path <path_to_saved_models>:模型保存的文件夹路径。这是训练过程中保存的模型权重。--result_path <path_for_output_csv>:输出结果的文件夹路径。混淆矩阵和性能指标的CSV文件将保存在这里。--pretrained <True_or_False>:指定是否使用预训练的模型权重。应该为True或False。--model <model_type>:指定模型的类型。可以是resnet18,resnet50,resnet101等。
(2)示例命令
假设你的脚本名为evaluate.py,测试数据列表保存在./file/animal-5/test.txt,标签映射文件位于./file/animal-5/classes.json,训练好的模型保存在./result/resnet18,你希望将结果保存到./result/resnet18_csv,并且你使用的是预训练的resnet18模型,以下是相应的命令:
python evaluate.py --test_path ./file/animal-5/test.txt --json_path ./file/animal-5/classes.json --model_path ./result/resnet18 --result_path ./result/resnet18_csv --pretrained True --model resnet18
确保替换命令中的路径和参数以匹配你的具体情况。运行此命令后,脚本将使用指定的测试数据评估模型,并将混淆矩阵及性能指标输出到指定的路径。
控制台输出结果:
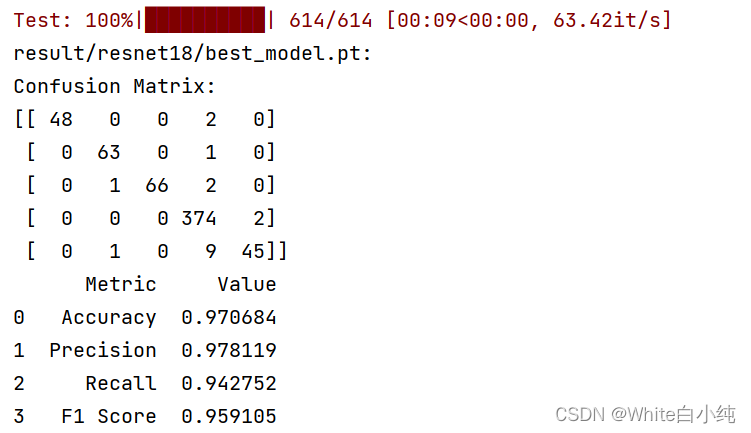
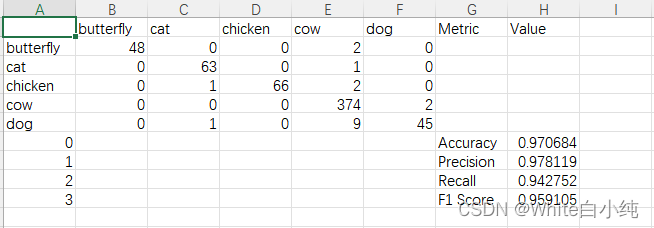
csv保存结果
4. 总结
我们深入探讨了深度学习在图像分类任务中的应用,以动物分类为例进行了实战演练。我们从数据集的准备和预处理开始,探讨了如何通过调整图像尺寸和应用数据增强技术来提高模型的泛化能力。接着,我们讨论了不同的深度学习模型架构,训练代码中集成了如ResNet和MobileNet等模型,并介绍了如何使用PyTorch框架来训练这些模型。
我们通过命令行参数灵活地控制训练过程,允许用户自定义模型训练的各个方面,包括模型的选择、是否使用预训练权重、学习率和批大小等。通过实现自定义的数据加载器,我们能够有效地处理图像数据和标签,为模型训练和评估提供了强大的支持。
在模型训练部分,我们强调了训练过程中的关键环节,如损失函数的选择、优化器的配置以及如何根据验证集的表现来保存最佳模型。此外,我们还探讨了模型评估的重要性,通过计算混淆矩阵和关键性能指标(如准确率、精确度、召回率和F1得分)来深入了解模型在未见数据上的表现。
在整个系列中,我们的目标是提供一个全面的指南,帮助读者了解和实现一个完整的图像分类项目。通过详细的代码示例和解释,我们希望读者能够不仅理解深度学习模型背后的原理,还能够自信地应用这些技术来解决自己感兴趣的问题。
之后我们会陆续更新不同的深度学习图像处理的技术和代码,不仅向大家提供便于在实验中使用的代码,也尽量提供能落地应用的代码框架。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











