









 本文深入探讨了OIT(Order Independent Transparency)技术,一种解决半透明物体渲染难题的方法。文章详细介绍了几种OIT技术,如Depth Peeling、Per-Pixel Linked Lists OIT等,并以Per-Pixel Linked Lists OIT为例,讲解了其在Vulkan中的实现过程。
本文深入探讨了OIT(Order Independent Transparency)技术,一种解决半透明物体渲染难题的方法。文章详细介绍了几种OIT技术,如Depth Peeling、Per-Pixel Linked Lists OIT等,并以Per-Pixel Linked Lists OIT为例,讲解了其在Vulkan中的实现过程。

一、OIT技术
在3D渲染中,物体的渲染是按一定的顺序渲染的,这也就可能导致半透明的物体先于不透明的物体渲染,结果就是可能出现半透明物体后的物体由于深度遮挡而没有渲染出来。对于这种情况通常会先渲染所有的不透明物体再渲染半透明物体或者按深度进行排序来解决。但这样仍然无法解决半透明物体之间的透明效果渲染错误问题,特别是物体之间存在交叉无法通过简单的排序来解决。于是就有一些用专门来解决半透明物体渲染算法,OIT算法即Order Independent Transparency(顺序无关的半透明渲染),下图分别为两个交叉的半透明物体不采用OIT及采用OIT的绘制效果。


如果出现自纠缠的复杂的半透明物体,就必须引入更加复杂的技术来解决问题了。即本文将要讨论的顺序无关的半透明混合技术(Order Independent Transparency,OIT)。OIT 技术的方案不止一种,下表大致罗列了这些技术的相关信息:
| 速度(大约) | 空间(大约) | |
|---|---|---|
| Depth Peeling | 1 | 100 |
| Stencil Routed | 1 | 100 |
| Per-Pixel Linked List | 5 | 80 |
| Adaptive Transparency | 10 | 80 |
| Weighted Blended OIT | 10 | 80 |
| Pixel Synchronization | 10 | 50 |
1.1 Depth Peeling
深度剥离方法,出自 NVIDIA,其核心思想是从相机触发,经过 N(可配置)个 PASS 将场景中的半透明物体根据深度分成了 N 层,分别记录每层的颜色和深度,然后再将每层的颜色混合起来。后来 NVIDIA 为了优化剥离性能,又提出了一种在一个 PASS 中同时剥离 最前面一层 和 最后面 的方法,被成为 Dual Depth Peeling。

Depth Peeling 是一种很慢,非常费显存空间(空间分配可确定),但对硬件没什么高要求的 OIT 方法。
文献参考:
1.2 Per-Pixel Linked Lists OIT
逐像素的链表,是运用用到一个被成为“GPU 并行链表“的技术,在 Pixel Shader 中使用两个可写的纹理(DX11,SM 5.0,UAV),一个屏幕大小的链表头纹理,一个屏幕大小 N 倍的链表节点纹理。链表头纹理的每个像素存储每个像素链表在节点纹理中的偏移量。
这项技术可以用来解决图形渲染中的很多问题,用来解决 OIT 问题只是其诸多应用之一。核心做法是遇到半透明片元就将深度、颜色等写入对应像素的链表。最后再用一个 PASS 对每个像素的链表进行深度排序和颜色混合。

Per-Pixel Linked Lists 用于解决 OIT 问题,速度比 Depth Peeling 快了很多。显存空间也比 Depth Peeling 更加节省,但节点纹理具体需要多大无法事先做准确的预估,因此显存的具体消耗不可控。
文献参考:
- real-time concurrent linked list construction on the GPU:
- OIT in OpenGL 4.x
- KlayGE: 实现一个较新的OIT方法:Per-Pixel Linked Lists
1.3 Adaptive Transparency
Adaptive Transparency,简称 AT,是 Intel 提出的一种 OIT 技术。其核心思想是通过修改经典混合公式本身来改进 Per-Pixel Linked Lists 方法的内存和性能问题。
回顾一下经典混合公式:
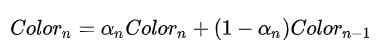
在经典的混合公式中,颜色一次一次有序的迭代混合到目标色上的。如果我们使用某种方法,打破这种有序迭代,我们就可以不用再对片段排序了,即做到了真正的顺序无关。在这个方法中引入了一个能见度函数来简化这个顺序无关的混合公式。
引入能见度的混合公式:
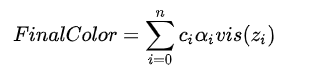
现在所有的问题都集中在能见度函数上了:一个在 [0, 1] 之间单调递减的函数。

能见度函数:
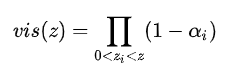
因此我们可以这样计算 OIT 最终颜色了:
-
渲染半透明物体,建立 Per-Pixel Linked Lists,并将片段颜色、深度写入对应的 List。
-
读取 Lists 然后建立能见度函数 vis 。
-
再次读取 Pixel Lists 然后使用带有能见度函数的混合公式计算最终颜色。
但这并没有比 Per-Pixel Linked List 更优秀。一个很好的思路是将能见度函数近似的表示为一个单调递减的定长数组。比如:
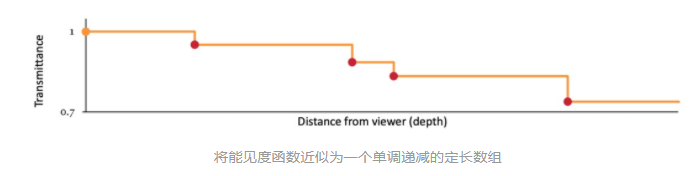 在采用近似能见度函数后,OIT 计算理想情况下可以直接简化为:
在采用近似能见度函数后,OIT 计算理想情况下可以直接简化为:
- 渲染半透明物体,将颜色、近似的能见度函数 vis(z),并将其存储到framebuffer中。
- 后处理,使用带有能见度的混合方程,计算最终颜色。
但是在 DX11 的硬件设备和 API 上不能支持我们完成上述方案的第一步:
- 如果使用framebuffer,其位宽有限,无法存储第一步产生的数据。
- 如果使用 UAV,GPU 片段计算是完全并行的(同一个像素的不同片段都是并行的),无法采用原子方法生成单调递减的 vis 函数。
因此,最终的 Adaptive Transparency 方法是:
- 渲染半透明物体,建立 Per-Pixel Linked Lists,并将片段颜色、深度写入对应的 List(这一步与 Per-Pixel
Linked List OIT 一样)。 - 后处理:读取 List,在本地内存空间生成近似能见度函数数组,并使用带能见度函数的混合公式混合片段计算出最终颜色。

Adaptive Transparency 方法使用了近似的能见度函数,对 Per-Pixel Linked List 的混合步骤进行了简化,不需要再对每个像素的所有片段进行排序了,简化了混合计算复杂度,但也因此丢失了混合精度。从 paper 的测试数据看,AT 方法在越复杂的场景中,相比 Per-Pixel Linked Lists OIT 的效率越高。
文献参考:
- 2011-02 Adaptive Transparency by intel presentation on GDC 2011
- KlayGE: 继续探索OIT:Adaptive Transparency
1.4 Weighted Blended OIT
文献参考:
1.5 Pixel Synchronization
文献参考:
- 2013 SIGGRAPH Pixel Synchronization: Solving Old Graphics Problems with New Data Structures
- 2017 intel: Order-Independent Transparency Approximation with Raster Order Views
二、Vulkan实现
本部分主要采用Per-Pixel Linked Lists OIT算法实现顺序无关的半透明混合具体算法。
2.1 算法回顾
2.1.1 常规混合算法
现在让我们再回顾一下正确的透明计算法。对每一个像素来说,若当前的背景色为c0 ,然后待渲染的透明像素片元按深度值从大到小排序为c1 , c2 , . . . , cn ,透明度为a1 , a2 , . . . , an则最终的像素颜色为:
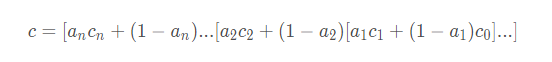
在以往的绘制方式,我们无法控制透明像素片元的绘制顺序,运气好的话还能正确呈现,一旦换了视角就会出现问题。要是场景里各种透明物体交错在一起,基本上无论你怎么换视角都无法呈现正确的混合效果。因此为了实现顺序无关透明度,我们需要预先收集这些像素,然后再进行深度排序,最后再计算出正确的像素颜色。
2.1.2 逐像素使用链表(Per-Pixel Linked Lists)
由于着色器只有按值传递,没有指针和引用,在GPU是做不到使用基于指针或引用的链表的。为此,我们使用的数据结构是静态链表,它可以在数组中实现,原本作为next的指针则变成了下一个元素的索引值。

因为数组是一个连续的内存区域,我们还可以在一个数组中,存放多条静态链表(只要空间足够大)。基于这个思想,我们可以为每个像素创建一个链表,用来收集对应屏幕像素位置的待渲染的所有像素片元。
该算法需要历经两个步骤:
- 创建静态链表。通过像素着色器,利用类似头插法的思想在一个大数组中逐渐形成静态链表。
- 利用静态链表渲染。通过计算着色器,取出当前像素对应的链表元素,进行排序,然后将计算结果写入到渲染目标。
2.2 创建静态链表
这一步实际上是把原本要绘制到渲染目标的这些像素片元给拦截下来,放到静态链表当中。
下图展示了通过像素着色器创建静态链表的过程:

看完这个动图后其实应该基本上能理解了,可能你的脑海里已经有了初步的代码构造,但现在还是需要跟着现有的代码学习才能实现。
首先我们来看一下创建静态链表所用的shader:
顶点着色器:
#version 450
layout (location = 0) in vec3 inPos;
layout (set = 0, binding = 0) uniform RenderPassUBO
{
mat4 projection;
mat4 view;
} renderPassUBO;
layout(push_constant) uniform PushConsts {
mat4 model;
vec4 color;
} pushConsts;
void main()
{
mat4 PVM = renderPassUBO.projection * renderPassUBO.view * pushConsts.model;
gl_Position = PVM * vec4(inPos, 1.0);
}
顶点着色器中我们使用推入常量来初始化实例物体,颜色值则是片元着色器中直接存储至链表。
片元着色器:
#version 450
layout (early_fragment_tests) in;
struct Node
{
vec4 color;
float depth;
uint next;
};
layout (set = 0, binding = 1) buffer GeometrySBO
{
uint count;
uint maxNodeCount;
};
layout (set = 0, binding = 2, r32ui) uniform uimage2D headIndexImage;
layout (set = 0, binding = 3) buffer LinkedListSBO
{
Node nodes[];
};
layout(push_constant) uniform PushConsts {
mat4 model;
vec4 color;
} pushConsts;
void main()
{
// 增加节点数
uint nodeIdx = atomicAdd(count, 1);
// 判断链表是否满溢
if (nodeIdx < maxNodeCount)
{
// 交换新的链表头索引和以前的链表头
uint prevHeadIdx = imageAtomicExchange(headIndexImage, ivec2(gl_FragCoord.xy), nodeIdx);
// 存储数据至链表
nodes[nodeIdx].color = pushConsts.color;
nodes[nodeIdx].depth = gl_FragCoord.z;
nodes[nodeIdx].next = prevHeadIdx;
}
}
片元着色器中,我们需要注意两个函数:
- atomicAdd:函数是先赋值后进行加法计算。atomicAdd实际是调用atomicCAS函数,atomicSub、atomicMax等函数都是如此,了解一个就都明白了。从代码中看到,atomicCAS是对地址操作,将结果存在地址上,返回的是还是old值。
- imageAtomicExchange:函数是将data写入给定坐标上,并返回原来的值。函数的返回值是执行操作之前内存中的值。
记录完数据后,使用map将数据映射出去,之后在渲染之前将数据赋值映射进新的渲染管线。
2.3 利用静态链表渲染
现在我们需要让片元/链接缓冲区和首节点偏移缓冲区都作为渲染阶段着色器资源。一般情况下还需要准备一个存放渲染了场景中不透明物体的背景图作为混合初值,同时又还要将结果写入到渲染目标(一般情况下是:存放与后备缓冲区等宽高的纹理,然后将场景中不透明的物体都渲染到此处),此处为了简化流程我们直接使用vec4(0.025, 0.025, 0.025, 1.0f)近似纯黑作为背景。
对于顶点着色器来说,因为是渲染整个窗口,可以直接传顶点:
#version 450
void main()
{
vec2 uv = vec2((gl_VertexIndex << 1) & 2, gl_VertexIndex & 2);
gl_Position = vec4(uv * 2.0f + -1.0f, 0.0f, 1.0f);
}
对于片段着色器来说,主要是讲数据读取出来,排序深度,之后执行混合三步。
#version 450
#define MAX_FRAGMENT_COUNT 128
struct Node
{
vec4 color;
float depth;
uint next;
};
layout (location = 0) out vec4 outFragColor;
//上一个管线存储的链表数据
layout (set = 0, binding = 0, r32ui) uniform uimage2D headIndexImage;
layout (set = 0, binding = 1) buffer LinkedListSBO
{
Node nodes[];
};
void main()
{
Node fragments[MAX_FRAGMENT_COUNT];
int count = 0;
uint nodeIdx = imageLoad(headIndexImage, ivec2(gl_FragCoord.xy)).r;
//数据读取
while (nodeIdx != 0xffffffff && count < MAX_FRAGMENT_COUNT)
{
fragments[count] = nodes[nodeIdx];
nodeIdx = fragments[count].next;
++count;
}
// 使用插入排序,深度值从大到小
for (uint i = 1; i < count; ++i)
{
Node insert = fragments[i];
uint j = i;
while (j > 0 && insert.depth > fragments[j - 1].depth)
{
fragments[j] = fragments[j-1];
--j;
}
fragments[j] = insert;
}
// 混合处理
vec4 color = vec4(0.025, 0.025, 0.025, 1.0f); //底图
for (int i = 0; i < count; ++i)
{
color = mix(color, fragments[i].color, fragments[i].color.a);
}
outFragColor = color;
}
至此,主要步骤已结束。至于C++端代码便不再赘述。运行结果可见下图:




















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









