







首先说一下,UE5由于用户硬件适应性的原因,没有采用Mesh Shader而是采用了更复杂的自定义meshlet group lod算法,如下对比所示:
UE5 meshlet方案:

Mesh Shader Meshlet方案:

一、Amplification Shader and Mesh Shader
我们先来明确一下VK、OpenGL也有Mesh Shader,对于DX12中的Amplification Shader 在其下则是叫Task shader(可非必选)。
1.1 Why Mesh Shaders
(1)原有管线的瓶颈
简而言之:面对现代海量且细节丰富的场景,传统渲染流水线很难做到高效渲染,因此衍生出了很多现代图形渲染技术(GPU-Driven Rendering)。
其实对于传统管线而已,不管事先对模型数据做何处理,处理好的mesh数据最终还是要经过Draw Call的。API一路演化下来,提供了许多高级的Draw Call:
- 实例绘制(instancing):同样的顶点数据,多份实例数据(不同的位置、方向、尺寸、材质ID……)
- 间接绘制(Draw Indirect):把Draw Call的参数存在Buffer里,可供GPU修改。
- 多间接绘制(Multi Draw Indirect):多个Draw Call的参数存在Buffer里,可供GPU修改。
间接绘制,正是GPU-Driven的基础,GPU做完剔除后可以自己修改Draw Call参数来决定要绘制哪些物体,而不用回传给CPU重新组织Draw Call。
接下来让我们看看,现有的光栅化管线,都存在哪些问题,以致于NVIDIA决定甩开历史包袱,另起炉灶。
- 首先是几何着色器(Geometry Shader):一个线程可以对应任意个图元的拍脑袋设计,给硬件厂商挖了个大坑,性能长期拉胯。后续推出的细分阶段(Tessellation)则明显保守了许多,由硬件Tessellator负责产生固定pattern,使用起来简单高效,但也牺牲了灵活性。TES一个线程对应一个新顶点,这种定死了线程映射关系的设计思路,与传统管线一脉相承,也注定了其只能局限于细分这么一个领域。(常常被当成输出细分因子工具人的TCS,反而有协作式编程模型的味道,虽然线程数被定死为输出到TES的顶点数,但并非一一对应)
以上的不足要么不够灵活,要么我干脆不用,倒也不足以成为整条几何管线被痛下杀手的主因。真正的性能瓶颈是在图元分发(Primitive Distributor) 上,因其是个固定管线阶段,可能不太被人熟知。
我们知道,无论是什么着色器代码,它们在GPU上都是以Warp为单位运行的,海量的顶点数据从管线上方进入,肯定要经过一个步骤进行拆分,这就是PD的工作内容,拆分后的三角形块被称为Batch。
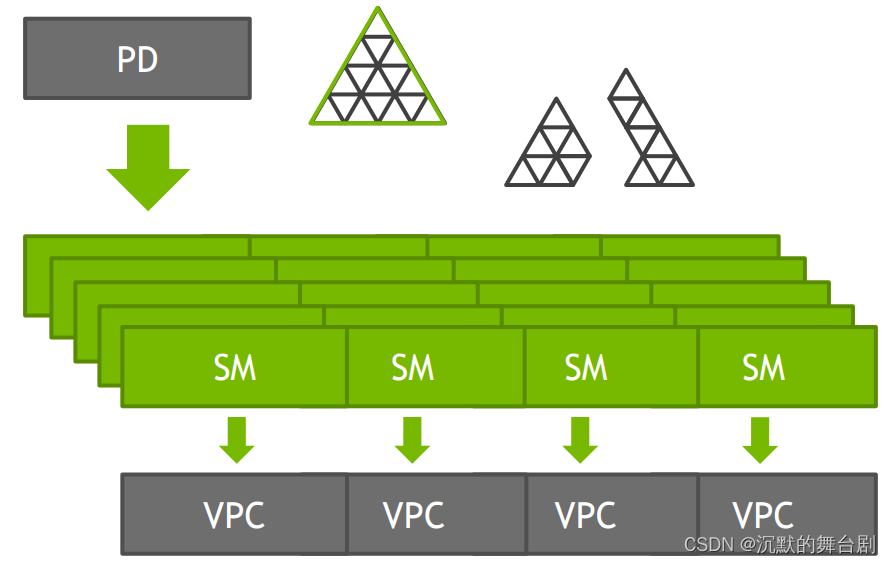
分发前对于顶点索引数据的组织和压缩十分巧妙。因为顶点常常被多个三角形复用,因此实际上的顶点索引是存在大量重复的。当我们把目光聚焦到一个Batch上时,则可以通过再引入一层间接性(顶点索引的索引,虽然听起来很绕,但这么表述反而是最清晰的,后续实例会逐一体现),以实现只存一份不重复的顶点索引。
其本质只是把重复的顶点索引变成重复的顶点索引的索引罢了。这有什么意义呢?意义在于,顶点索引是用来索引一整个顶点Buffer里的顶点数据的,因此每一个顶点索引的位数肯定很大;但是顶点索引的索引只是用来索引一个Batch内的顶点索引,其所需位数就小得多了。

但是上述解决方案还是有问题的:
- 每次都重新组织,实在没有必要。大部分模型数据,其实都是静态的,但是每一帧,都得经过PD做一模一样的事情。虽然这由专门的硬件负责速度相对来说很快,但是抛开使用场景谈速度就是耍流氓,当我们开始极力追求海量模型数据、恐怖的细节增长时,这种不必要的重复显然就成了可以优化的瓶颈。
- 顶点复用率超过3,顶点就无法满载。既然PD是固定管线模块,那么很多东西便是定死的,比如每一个Batch的顶点数(也就是顶点索引数,因为Batch里顶点索引是去重的)和图元数是被定死的,最大只有32,谁先装满,这个Batch也就装满了。这意味着当顶点复用率超过3时,就会出现图元装满了但顶点没有装满的情况,会使之后的Warp无法满载。
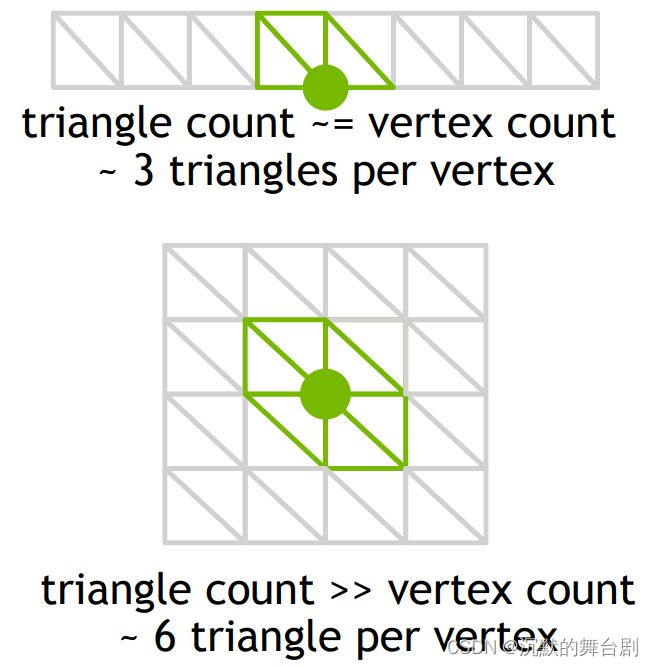
1.2 Meshlet
Meshlet的概念跟刚刚所说的Batch很类似,不过这是我们自定义的数据类型,因此大小也可以由我们自由决定。
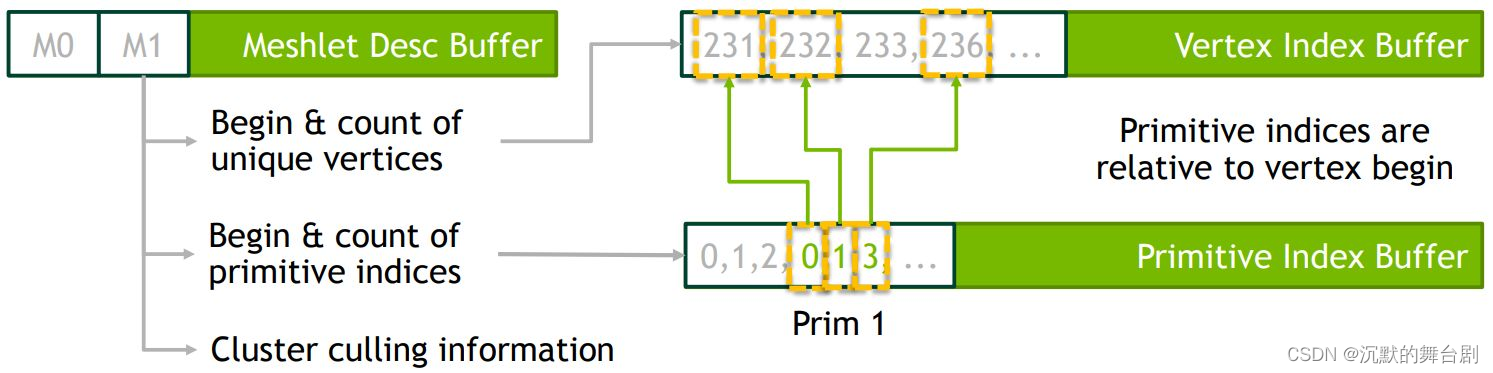
把模型提前组织成Meshlet存下来,可以有两个直接的好处:
- 数据量变小了:和Batch一样,重复的顶点索引变成了代价更小的重复的顶点索引的索引
- 剔除的粒度变小了:以前只能基于一整个模型,现在可以基于一块块小网格了。但是不同于直接拆成几个独立的模型,Meshlet之间相接的顶点数据仍然只有一份。
经过上述处理后一个模型可以被分成多个meshlet,如下图所示:

其中,如何划分meshlet也是很重要的,我们之后的实例中会有专门的划分实践。
还有就是输出限制的事,可以看到每个模型被分成了多份meshlet,先简单的介绍一下:
- Mesh Shader的输出主要分为两大类,per vertex的,以及per primitive的。对于per
vertex的数据,类似以前VS输出的数据,是每一个vertex经过shader处理的结果。同样的,如果需要开启光栅化过程,那么per
vertex中必须带有SV_Position标记的数据。目前规范规定,一个thread group最多输出256个vertex。 - per primitive的数据是Mesh Shader中新增加的部分。Per Primitive的数据分为两类,必须输出的indices数组,以及可选输出的primitives数组。indices数组的作用类似以前用户自己提供的index buffer,其指明了vertex数据是如何组织成为Primitive的。这个由Mesh Shader生成的index buffer只能有line list或者triangle list topology。一个thread group输出的indices的最大长度也是256(最多指定256个primitive)。
1.3 Mesh Shader Pipeline
Mesh Shader与常规管线具有很多异同,具体来说,分为一下几部分:
(1)流程对比
首先我们来看一下常规渲染管线与网格着色器渲染管线对比(NVIDIA介绍 Task Shader即Amplification Shader):

可以明显看得出来光栅化及其之后都会进入PS,所以直观来看,可以直接用以下图片表示两者的异同:

(2)计算着色器对比
mesh shader在分发的时候和Compute Shader启动时候的Dispatch非常相似,相比于Compute Shader,Mesh Shader为图形渲染管线进行了特化,这是因为Mesh Shader的输出需要直接接入到渲染管线中的Rast中,所以Mesh Shader需要满足如下条件,以提供特定的图形学语义(而不像Compute Shader一样,输出没有任何图形学语义约束):

(3)性能对比
上边可以看到mesh shader与computer shader及其类似,而如何高效地在compute pipeline和graphic pipeline中间做同步是一个关键且老生常谈的问题。既然如此,为何不一步到位,直接用CS替换整个VTG vertex shading,直接生成图元,送入RAST中呢?这样一来,就显著避免了额外的compute pipeline/graphic pipeline之间的同步,同时也将原本就是临时数据的部分放入on-chip storage上,带来的性能提升和编程灵活性的改进可不是修修补补原有的渲染管线所能比得上的。
D3D12也正是基于这种想法,新增加了两个Shader Stage,即可选的Amplifying Shader,和Mesh Shader,替换从IA到GS,所有的vertex shading阶段。Mesh Shader可以粗略看作一种特化的带有约束的Compute Shader,可以直接生成可供光栅化使用的图元拓扑,同时还保持了CS的灵活性。
当然还有就是其运行机制的不同了,可以一句话概括:Mesh Shader更适应显卡特性,可以充分发挥显卡性能。
(4)适应性对比
除此之外,当然还有一个最大的区别就是其适应性的问题:常规渲染管线,所有现代显卡都支持,而Mesh Shader则是在图灵架构显卡下才会有很好的支持(VK与DX12皆需要在初始化时进行特性检测)。
(5)缓冲区数据对比
先来看一下常规opengl中的数据结构:

之后看一下mesh shader的,其实大致类似,就是拆分成了更细粒度的meshlet来适配。

二、DirectX 12 API
2.1 D3D API calls
先来看一下在CPU端主要的API:
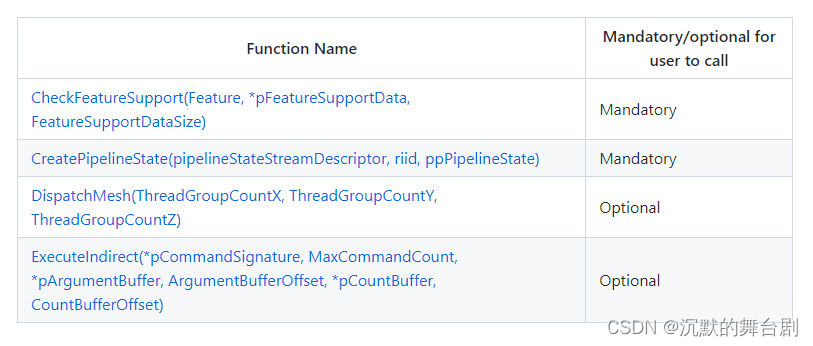
2.1.1 CheckFeatureSupport
HRESULT CheckFeatureSupport(
D3D12_FEATURE Feature,
void *pFeatureSupportData,
UINT FeatureSupportDataSize
);
要确定是否支持Mesh Shader,可以使用新的枚举D3D12_FEATURE来调用 CheckFeatureSupport,其中填充了新的结构D3D12_FEATURE_DATA_D3D12_OPTIONS7。
此结构包含一个字段MeshShaderTier ,该字段引用一个新的枚举D3D12_MESH_SHADER_TIER ,定义如下:
typedef enum D3D12_MESH_SHADER_TIER {
D3D12_MESH_SHADER_TIER_NOT_SUPPORTED,
D3D12_MESH_SHADER_TIER_1,
} ;
要确保硬件是否支持Mesh Shader,请在调用“CheckFeatureSupport”后,需要进行如下判断:
D3D12_FEATURE_DATA_D3D12_OPTIONS7 featureData = {};
pDevice->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS7, &featureData, sizeof(featureData));
VERIFY_ARE_NOT_EQUAL(featureData.MeshShaderTier, D3D12DDI_MESH_SHADER_TIER_NOT_SUPPORTED);
2.1.2 CreatePipelineState
HRESULT CreatePipelineState(
const D3D12_PIPELINE_STATE_STREAM_DESC *pDesc,
REFIID riid,
void **ppPipelineState
);
调用此函数,可以使用填充了AS与MS数据的结构体进行创建渲染管线对象。至于使用Mesh Shader时,必须按照以下规则进行处理:
-
必须禁用 IA 和流输出
-
必须使用Mesh Shader (MS)
-
可任选Amplification Shader(AS)
-
不得附加任何其他着色器类型(VS 、GS 、HS 、DS)
-
必须对所有链接的着色器使用 DXIL 字节码
因此要将AS与MS附加到 D3D12_PIPELINE_STATE_STREAM_DESC streamDesc对象,需要创建一个包含CD3DX12_PIPELINE_STATE_STREAM_AS和CD3DX12_PIPELINE_STATE_STREAM_MS的结构,并将每个结构设置为相应的D3D12_SHADER_BYTECODE 。
例如下边的demo:
struct PSO_STREAM
{
CD3DX12_PIPELINE_STATE_STREAM_ROOT_SIGNATURE pRootSignature;
CD3DX12_PIPELINE_STATE_STREAM_AS AS;
CD3DX12_PIPELINE_STATE_STREAM_MS MS;
...
CD3DX12_PIPELINE_STATE_STREAM_SAMPLE_DESC SampleDesc;
} Stream;
Stream.AS = GetASBytecode();
Stream.MS = GetMSBytecode();
...
D3D12_PIPELINE_STATE_STREAM_DESC streamDesc = {};
streamDesc.pPipelineStateSubobjectStream = &Stream;
streamDesc.SizeInBytes = sizeof(Stream);
CComPtr<ID3D12PipelineState> spPso;
pDevice->CreatePipelineState(&streamDesc, IID_PPV_ARGS(&spPso))
2.1.3 DispatchMesh API
Mesh Shader的引入,直接改变了原有的渲染管线组织。这一点可以从API上看到。DX12中,现阶段使用Mesh Shader的渲染管线,启动draw-call的API为:
void DispatchMesh(UINT ThreadGroupCountX, UINT ThreadGroupCountY, UINT ThreadGroupCountZ);
从这个API可以看出,这个draw-call(实际上更准确地说,应该叫dispatch call)和DX11中所有的draw-call都不太一样:没有instance,没有index,没有vertex。相反,这个draw-call倒是和DX11的Compute Shader启动时候的Dispatch非常相似,这也是为何我们说Mesh Shader实际上就是特化了的Compute Shader的原因。
相比于Compute Shader,Mesh Shader为图形渲染管线进行了特化,这是因为Mesh Shader的输出需要直接接入到渲染管线中的Rast中,所以Mesh Shader需要满足如下条件,以提供特定的图形学语义(而不像Compute Shader一样,输出没有任何图形学语义约束):
- mesh shader的输出需要有vertex的概念
- mesh shader的输出需要有primitive的概念,DX12中mesh shader的输出只支持line或者triangle
- mesh shader输出的per vertex的attribute,必须有SV Position,以辅助RAST阶段完成插值
- mesh shader输出的per vertex可以有其他的attribute,并依此设定不同的插值模式,RAST阶段可以据此完成插值
如果渲染管线配置了AS,那么同样的DispatchMesh则会启动AS,由AS thread group在shader中使用同名的HLSL intrinsics启动MS:
template <typename payload_t>
DispatchMesh(uint ThreadGroupCountX,
uint ThreadGroupCountY,
uint ThreadGroupCountZ,
groupshared payload_t MeshPayload);
例如:
struct payloadStruct
{
uint myArbitraryData;
};
[numthreads(1,1,1)]
void AmplificationShaderExample(in uint3 groupID : SV_GroupID)
{
payloadStruct p;
p.myArbitraryData = groupID.z;
DispatchMesh(1,1,1,p);
}
2.1.4 ExecuteIndirect
void ExecuteIndirect(
ID3D12CommandSignature *pCommandSignature,
UINT MaxCommandCount,
ID3D12Resource *pArgumentBuffer,
UINT64 ArgumentBufferOffset,
ID3D12Resource *pCountBuffer,
UINT64 CountBufferOffset
);
当然也可以将一些工作从 CPU 间接移动到 GPU 执行以提高性能(GPU-Driven思路)。为了将其与DispatchMesh结合使用,传入GPU执行的ID3D12CommandSignature 必须具有D3D12_INDIRECT_ARGUMENT_DESC描述信息,且其中必须D3D12_INDIRECT_ARGUMENT_TYPE_DISPATCH_MESH 类型数据和sizeof(D3D12_DISPATCH_ARGUMENTS)大小字节的偏移 。
例如:
// New enum value of D3D12_INDIRECT_ARGUMENT_TYPE
typedef enum D3D12_INDIRECT_ARGUMENT_TYPE {
...
D3D12_INDIRECT_ARGUMENT_TYPE_DISPATCH_MESH
} D3D12_INDIRECT_ARGUMENT_TYPE;
typedef struct D3D12_INDIRECT_ARGUMENT_DESC {
D3D12_INDIRECT_ARGUMENT_TYPE Type; // = D3D12_INDIRECT_ARGUMENT_TYPE_DISPATCH_MESH
union {
...
// New member D3D12_DISPATCH_MESH_ARGUMENTS
struct {
UINT ThreadGroupCountX;
UINT ThreadGroupCountY;
UINT ThreadGroupCountZ;
} D3D12_DISPATCH_MESH_ARGUMENTS;
};
} D3D12_INDIRECT_ARGUMENT_DESC;
2.2 HLSL attributes and intrinsics
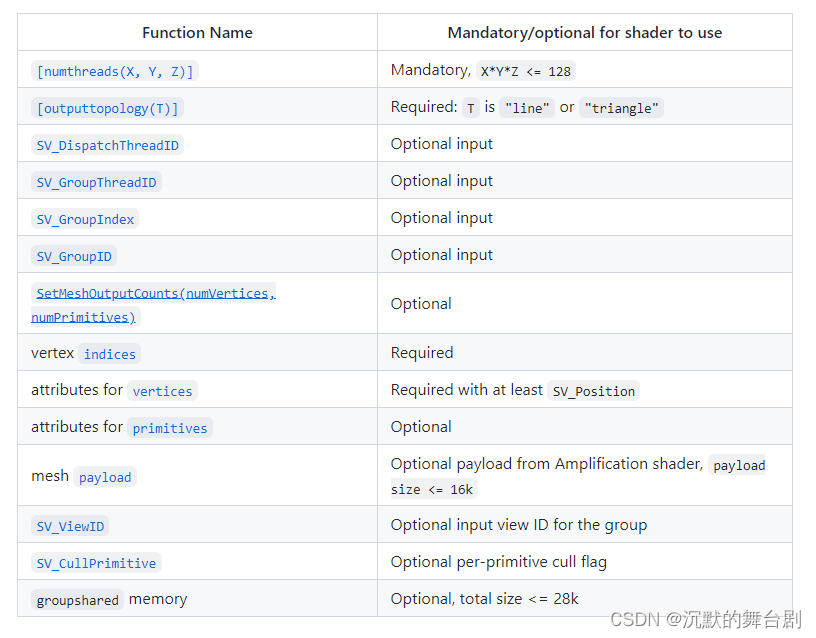
2.2.1 numthreads
[numthreads(X, Y, Z)]
void main(...)
这是Mesh Shader入口上的必要函数属性。它指定Mesh Shader线程组的启动大小,和使用计算着色器一样。但是线程数不能超过 X * Y * Z <= 128。
该实现必须调用Mesh Shader,每个维度中用户可用的线程数等于 X、Y 和 Z,并且它不应提供任何基于硬件 IA 的功能。未来D3D版本中将会提供内置函数来帮助读取索引数据。
所有输出基元的所有输出顶点必须由同一线程组设置。无法在Mesh Shader线程组之间共享输出顶点或输出索引。
还需要注意的是:如果着色器执行数量大于此属性的线程数,那么在调用DispatchMesh时将会直接返回报错。
2.2.2 outputtopology
[outputtopology(T)]
void main(...)
这是Mesh Shader入口上的必要函数属性。它指定Mesh Shader输出基元的拓扑结构为线或三角形(T为"line" or “triangle”)。
2.2.3 System Value Semantics
以下四个系统值中的每一个都按以下方式计算:
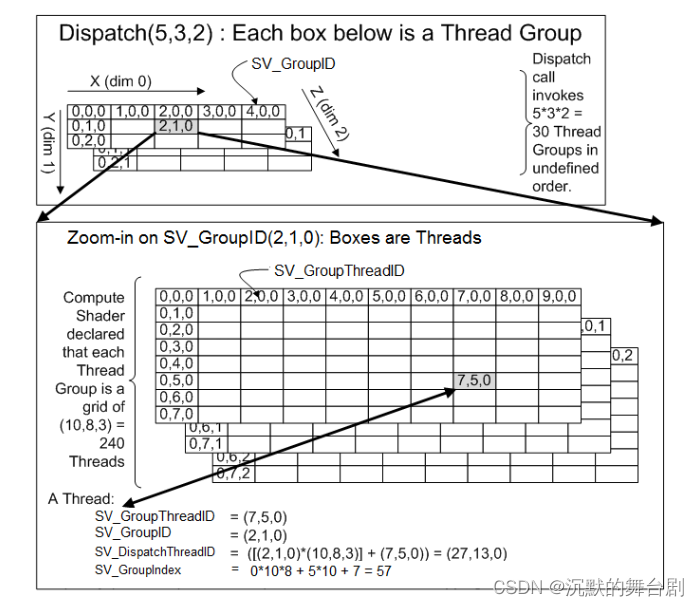
如果使用了AS,则系统值将相对于AS调用的 DispatchMesh 固有值进行计算。
如果未使用AS,则系统值就和DispatchMesh API 调用相关联。
例如,如果使用DispatchMesh(2,1,1)调用AS,并且每个 AS 调用一个Mesh Shader(DispatchMesh(1,1,1)),则每个Mesh Shader线程组中SV_GroupID将为 (0,0,0),因为它们是相对于调用DispatchMesh(1,1,1)计算的。
- SV_DispatchThreadID
void main(..., in uint3 dispatchThreadId : SV_DispatchThreadID, ...)
代表DispatchMesh内当前线程的 uint3 索引。
- SV_GroupThreadID
void main(..., in uint3 groupThreadId : SV_GroupThreadID, ...)
代表当前线程组中当前线程的 uint3 索引
- SV_GroupIndex
void main(..., in uint threadIndex : SV_GroupIndex, ...)
代表线程组中当前线程的 uint 索引位置
- SV_GroupID
void main(..., in uint3 groupId : SV_GroupID, ...)
代表DispatchMesh调用中内当前组的 uint3 索引
2.2.4 SetMeshOutputCounts
void SetMeshOutputCounts(
uint numVertices,
uint numPrimitives);
此函数设置线程组的实际输出数。在着色器的开头,实现在内部设置要从线程组导出的顶点和基元的计数为 0。这意味着,如果网格着色器在未调用此函数的情况下返回,则不会输出任何网格。
然而对函数使用和输出数组也是存在限制的:
-
每个着色器只能调用本函数一次。
-
本函数调用必须在写入任何共享输出数组( shared output arrays)之前进行。验证层会进行本项验证。
-
如果编译时发现未调用此函数,则线程组不会输出任何东西。此时着色器写入任何共享输出数组,则编译和着色器验证将失败。如果着色器不调用这些函数中的任何一个,编译器将发出警告,并且不会进行栅格化工作。
-
仅使用来自第一个活动线程的输入值。
-
此调用必须主导对共享输出数组的所有写入。换句话说就是:在未首先执行此调用的情况下,不会有任何执行途径进行对任何输出数组的写入。
下面通过示例来说明以上几种限制。
正确使用情况如下:
{ //...
SetMeshOutputCounts(...);
for (...) { // uniform or divergent
if (...) { // uniform or divergent
// write to output arrays -> Valid
}
}
}
{ //...
if (uniform_cond) {
SetMeshOutputCounts(...);
for (...) { // uniform or divergent
if (...) { // uniform or divergent
// write to output arrays -> Valid
}
}
}
}
{ //...
if (uniform_cond)
return;
SetMeshOutputCounts(...);
for (...) { // uniform or divergent
if (...) { // uniform or divergent
// write to output arrays -> Valid
}
}
}
无效使用情况:
{ // ...
if (uniform_cond) {
SetMeshOutputCounts(...);
}
if (uniform_cond) {
// write to output arrays
// 无效,因为写不在同一个分支中
// as SetMeshOutputCounts(...);
}
}
{ // ...
if (divergent_cond) {
// 分支可能不走
// 无效,编译器可能不会捕捉到这个导致未定义的行为
// in undefined behavior.
SetMeshOutputCounts(...);
}
...
}
{ //...
if (uniform_cond) {
SetMeshOutputCounts(...);
} else {
SetMeshOutputCounts(...);
//无效:着色器中存在多个调用。
}
}
以下方案会产生未定义的行为。硬件实现不会处理超出边界的写入。可选的运行时验证 (GBV) 可能会捕获这些情况并发出错误警告。
-
该函数是从分支中调用的。
-
numVertices大于顶点的数组维数。
-
numPrimitives大于图元的数组维数。
-
写入顶点时使用的索引大于此处指定的numVertices索引。
-
写入图元的顶点索引或属性时,使用的索引大于此处指定的numPrimitives索引。
2.2.5 Shared Output Arrays
网格着色器上有三个输出参数,用于定义在组中共享的输出数组,以便网格着色器组中的线程可以协作生成数据。
这些数组的维度定义了可以从着色器输出的最大顶点和图元数。输出必须包含数组维数,即使它是1 。如果着色器的最大顶点或图元数大于运行时返回的顶点或基元数,则管道状态对象创建调用将失败。
每个数组都不能读取,并且只能在调用 SetMeshOutputcounts 设置线程组输出的实际顶点和图元输出大小之后写入。。
写入索引时,必须同时写入索引数组的整个 uint2 或 uint3 数据,不能只编写一个组件而让其他组件稍后填充。
例如下边示例:
void main(..., out indices Indices[MAX_OUTPUT_PRIMITIVES], ...) {
...
Indices[i] = uint3(1, 2, 3); // Allowed.
Indices[i].x = 1; // Not Allowed.
写入属性时,可以一次写入属性结构的任何子集,如果光栅化和之后的着色器不读取某些属性,则不要写入这些属性。
如果这些数组中的同一元素被全部或部分写入多次,则写入的最后一个值是将最终有效的值。
有关每个参数的详细信息,请参阅相应的部分。
| 共享数据 | 数据类型 | 必要性 |
|---|---|---|
| 顶点索引(Vertex Indices) | 图元 | 必选 |
| 顶点属性(Vertex Attributes) | 顶点 | 必选 |
| 图元属性(Primitive Attributes) | 图元 | 可选 |
Vertex Indices
[outputtopology("line" or "triangle")]
void main(...,
out indices
[uint2 for line or uint3 for triangle]
primitiveIndices[MAX_OUTPUT_PRIMITIVES],
...)
此必要参数定义网格着色器线程组的共享输出顶点索引数组。每个数组元素定义构成一个输出基元的顶点索引。out和indices修饰符必须与此参数一起使用。uint2类型用于输出拓扑(“线”)或uint3输出拓扑(“三角形”)。此处,数组MAX_OUTPUT_PRIMITIVES的静态大小定义了此网格着色器可以生成的最大基元数,并且必须与基元属性数组的大小相匹配。此数组的最大大小为 256 个元素。
您必须一次写入基元的所有两个或三个顶点索引,否则编译器和验证器将引发错误。如果多次写入同一基元索引,则写入的最后一个值将定义基元为索引。
此数组的写入必须在调用“ SetMeshOutputCounts”之后进行。
备注
由于无法从应用程序级别检查或访问网格着色器的原始输出索引,因此 GPU 底层实现可能会选择以与 uint2 或 uint3 不同的格式存储输出索引。
Vertex Attributes
struct VertexAttributes {
//用户定义的每个顶点属性
//需要语义并使用插值模式
};
void main(...,
out vertices VertexAttributes sharedVertices[MAX_OUTPUT_VERTICES],
...)
此必要参数定义网格着色器线程组的共享输出顶点属性数组。out和vertices修饰符必须与此参数一起使用。
此处数组的静态大小定义了此网格着色器可以产生的最大顶点数。此数组MAX_OUTPUT_VERTICES的最大大小为 256 个元素。此数组是只写的,因此如果您尝试从数组中读取,编译器将发出错误。
您可以编写单个属性,如果其他属性不会在 Pixel 着色器中使用,则不写入这些属性。如果写入同一顶点索引处的相同属性,则写入的最后一个值将从网格着色器导出的值。
此结构必须为所有元素定义系统值或用户定义的语义,并且插值模式适用于顶点属性,就像输出结构的元素用作顶点着色器的返回值一样。
此结构中必须存在一个具有SV_Position语义的 4 分量向量,因为这是光栅化所必要的。
此数组的写入必须在调用“ SetMeshOutputCounts”之后进行。
Primitive Attributes
struct PrimitiveAttributes {
// 需要用户定义的每个原语属性语义,忽略插值模式
};
void main(...,
out primitives PrimitiveAttributes sharedPrimitives[MAX_OUTPUT_PRIMITIVES],
...)
此可选参数定义了网格着色器线程组的共享输出基元属性数组。out和primitives 修饰符必须与此参数一起使用。此处,数组MAX_OUTPUT_PRIMITIVES的静态大小定义了此网格着色器可以生成的最大基元数,并且必须与顶点索引数组的大小相匹配。此数组的最大大小为 256 个元素。
您可以编写单个属性,如果其他属性不会在 Pixel 着色器中使用,则不写入这些属性。如果写入相同基元索引的相同属性,则写入的最后一个值将从网格着色器导出的值。
此结构必须为所有元素定义系统值或用户定义的语义。SV_RenderTargetIndex、SV_ViewportIndex 和 SV_CullPrimitive只能是网格着色器中的每个基元属性。
SV_ShadingRate可通过支持粗力度着色平台上的网格着色器进行设置。在网格着色器设置时,将用作实际的每个基元属性,而不是每个激发顶点的属性。
此数组的写入必须在调用“ SetMeshOutputCounts”之后进行。
2.2.6 Signature Linkage
为了复用在传统图形管道上工作的像素着色器,需要更改网格着色器管道的签名链接规则。
在新的网格着色器管道中,签名元素必须通过匹配的语义名称和语义索引进行链接。对于系统值,链接由系统值类型和语义索引组成。元素不得再由打包位置链接。
仍会为签名中的顶点和基元元素设置打包位置,但由于这些元素是在网格着色器的单独结构中定义的方式,因此这些位置可能与像素着色器位置不匹配。元素将首先使用顶点元素进行填充,基元元素从紧跟顶点元素使用的最后一行之后的行开始打包。顶点和基元属性不会打包到同一行中,即使插值模式匹配也是如此。
所有这些元素都必须适合单个 32 行(128 标量元素)签名。但是,实际使用的组件数将用于网格着色器输出大小限制部分中定义的大小限制计算中。
2.2.7 Mesh Payload
void main(...,
in payload MeshPayloadStruct MeshPayload,
...)
此可选输入提供传递给放大着色器的 DispatchMesh 调用的有效负载。此参数为整个网格着色器线程组提供相同的输入值。
此参数的结构类型应与放大着色器中的 DispatchMesh 调用中使用的用户定义结构匹配。运行时将验证编译器报告的结构大小是否与放大着色器和网格着色器之间匹配。
此结构的数据布局与结构化缓冲区的数据布局相同。此结构的最大大小为 16k 字节。
2.2.8 SV_ViewID
SV_ViewID它的特殊之处在于它允许驱动程序创建着色器的版本,该版本在单个着色器通道中计算所有视图。它通过复制SV_ViewID依赖值、计算和属性来实现此目的。
需要运行时验证来检查是否可以根据依赖属性的数量支持一定数量的视图进行扩展。SV_ViewID
对于网格着色器,由于访问组共享内存,这很复杂。所依赖的组共享内存必须以类似的方式按视图数进行扩展。除了验证属性扩展是否适合可用属性限制(如当前图形管道所做的那样)之外,运行时还将检查组共享扩展是否适合。SV_ViewID
使用依赖值写入的动态索引数组必须通过将大小乘以视图数来扩展。SV_ViewID
注: SV_ViewID仅可用作网格着色器的输入,而不能用作放大着色器的输入。
注: SV_ViewID当前可用作像素着色器的输入,该输入不占用属性空间(系统生成的值),因此无法作为网格着色器的输出写入。
2.2.9 SV_CullPrimitive
这是一个每个基元布尔剔除值,指示是否为当前视图剔除基元(SV_ViewID)。内联扩展视图的硬件可以将其转换为每个视图的掩码值,而不是SV_ViewportID。SV_CullPrimitive不会占用基元签名中的空间。为了验证每个视图的属性扩展,无论是否声明了SV_ViewportID,都将始终将一个 32 位属性计为SV_ViewportID。SV_CullPrimitive不计算任何属性。
2.2.10 SV_PrimitiveID in the Pixel Shader
使用网格着色器时,没有系统生成的基元 ID(uint SV_PrimitiveID)值。如果像素着色器输入SV_primitiveID并与网格着色器配对,则网格着色器必须包含SV_PrimitiveID作为其基元输出的一部分,并且必须为每个基元手动输出其选择的值。因此,这与任何其他没有特殊名称的网格着色器基元输出没有什么不同。此处的基本目的是允许编写为与其他着色器(如几何着色器(其中确实存在SV_PrimitiveID)或顶点着色器(其中基元 ID 是自动生成的)一起使用的像素着色器也与网格着色器共享。
2.2.11 DispatchMesh intrinsic
template <typename payload_t>
DispatchMesh(uint ThreadGroupCountX,
uint ThreadGroupCountY,
uint ThreadGroupCountZ,
groupshared payload_t MeshPayload);
此函数(从放大着色器调用)启动网格着色器的线程组。每个放大着色器必须只调用一次此函数,不得从不均匀的流量控制中调用。DispatchMesh 调用意味着一个组内存与组同步(),并结束放大着色器组的执行。
对于组,参数被视为统一,这意味着如果不是组统一(或组共享),则从第一个线程读取它们。预期用途是让整个线程组在构建MeshPayload时进行合作。这也意味着,除了 API 启动的放大着色器组的数量之外,您无法放大唯一的 MeshPayload 内容的数量。
三个线程组计数中的每一个都必须小于 64k,并且ThreadGroupCountXThreadGroupCountYThreadGroupCountZ 的乘积不得超过 2^22,否则行为未定义。
传递给此调用的所有网格着色器实例的数据负载将通过 MeshPayload 参数传递。
此处指定的负载类型必须是用户定义的结构类型。此类型的大小必须与网格着色器中用于“网格着色器”的“获取网格”Payload 调用的大小相匹配。此结构允许的最大大小为 16k 字节。payload_t
有效负载结构的大小根据组共享内存限制进行计数。重申一下,这些限制是网格着色器的28k和放大着色器的32k。例如,使用最大可能有效负载大小 16k 的应用程序将只剩下 16k 个组共享可用于其放大着色器,12k 可用于其网格着色器。
该结构不会展开到打包的签名布局中,而是与本机结构指定的数据布局一起传递。数据布局应与结构化缓冲区相同。
2.2.12 Rendering of the mesh
网格使用输出函数设置的顶点和基元集进行渲染。运行时验证可能能够检查网格的完整性和索引的正确性,并在不满足规则时发出错误。
Programmable Primitive Amplification(AS)
网格着色器支持有限形式的图元放大,如 GS 放大。可以使用高达 1:V 和/或 1:P 的比率放大输入点几何图形,其中 V 是运行时处理的输出顶点数,P 是运行时处理的输出图元数。
然而,放大着色器的可编程放大不能在单个线程组中完成,因为扩展因子由程序决定,并且可能很大。
放大着色器旨在成为着色器管线的一个阶段,即可放大网格着色器实现可可拓展编程。
Streamout
MeshShader暂时不支持流输出。后续可能会添加一个特殊的附加缓冲区(UAV),并且可以从任何着色器阶段使用,包括常规计算阶段。
2.3 执行顺序
对于一个Mesh Shader thread group的输出,光栅化应当遵循此thread group输出所指定的顺序进行。
如果没有AS, 对于一个Mesh Shader里所有的thread group,光栅化的顺序则是按照X-Y-Z Major的顺序进行,如下所示:
for(z in [0..ThreadGroupCountZ-1])
{
for(y in [0...ThreadGroupCountY-1])
{
for(x in [0...ThreadGroupCountX-1])
{
group (x,y,z) is next
}
}
}
如果有AS,那么AS的Thread Group遵从上边约定的X-Y-Z Major顺序,但这些同一个AS Thread Group输出的MS彼此之间可以是乱序的。
简单来说,如果有AS的时候,一个AS Invocation可以有多个AS Thread Group,每个AS Thread Group输出多个MS,一个MS输出多个MS Thread group。这时候,每个MS Thread Group内部是顺序的(thread group所指定的顺序)。同时,同一个MS发起的MS Thread Groups彼此之间按照X-Y-Z Major顺序。此外,还需要保证一次AS Invocation的时候,AS Thread Group之间按照X-Y-Z Major的顺序生效。但同一个AS Thread Group所输出的MS之间的顺序是没有要求的。
举一个例子。现在我们有一个AS Shader,thread group大小是2x1x1,一个MS Shader, thread group大小为3x1x1。现在一次AS Invocation为4x1x1,这将会启动2个AS Thread Group。每个AS Thread Group中,同时也是用DispatchMesh启动MS,第一个启动6x1x1,第二个则启动9x1x1。这样,我们一共启动了5次MS thread group。前两次MS thread group的启动是由第一个AS Thread Group驱动的(DispatchMesh的参数6x1x1),而后三次MS Thread Group的启动则是由第二个AS Thread Group驱动的(DispatchMesh的参数是9x1x1)。那么,约定的顺序如下:
-
对于这5次Mesh Shader thread group,每个单独的Mesh Shader thread group的结果在光栅化时需要保证顺序,这个顺序由每个Mesh Shader thread group输出的vertices/primitives指定
-
光栅化时,前两次Mesh Shader thread group需要保证在后三次Mesh Shader thread group之前
-
但前两次Mesh Shader thread group内部是没有顺序保证的,同理,后三次Mesh Shader thread group之间也是没有顺序保证的
对比一个只有Mesh Shader,没有AS的场景。此时如果MS thread group大小为3x1x1,从API(而不是AS内部)DispatchMesh参数为9x1x1的话,则会有三次MS Thread group,这三次thread group之间是保证顺序的。这与我们从AS thread group中DispatchMesh时候的行为不同,这也是为何在约定MS顺序的时候,需要区分是否有AS的原因。
有AS的情况下,同一个AS Thread Group启动的MS之间无序,这一特性是为了方便硬件的实现。如果硬件可以从这种无序的约定中获得性能的提升,那么硬件设计的时候就应该考虑这一点。如果无序和有序的性能没有差别,硬件最好还是选择实现有序,这样更方便相关的Debug工作。
后续章节我们根据Mesh Shader的特性分别来看一下DX12Demo实现的Meshlet、Meshlet Instancing、 Meshlet Culling等GPU-Driven算法方案。


















 2429
2429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









