







 文章对比了传统顶点着色器与MeshShader在GPU渲染中的性能和效率,指出MeshShader的优势在于能直接控制几何处理,提供更高的顶点重用和灵活性,适用于程序化几何、细分曲面等复杂场景。
文章对比了传统顶点着色器与MeshShader在GPU渲染中的性能和效率,指出MeshShader的优势在于能直接控制几何处理,提供更高的顶点重用和灵活性,适用于程序化几何、细分曲面等复杂场景。
参照AMD官网文章和GDC中其分享内容https://gpuopen.com/learn/mesh_shaders/mesh_shaders-index/总结自用,大佬直接原文。
一、传统顶点着色器管线与Mesh 着色器对比
具体之前也研究过可参照:DX12_Mesh Shaders Render
这里主要针对之前忽略的一些知识点进行补充。
1.1 顶点着色器的弊端
我们先深入了解一下GPU 是如何使用顶点缓冲区和索引缓冲区来处理传统的绘制调用的(可参照:GPU架构与管线总结)。在传统的图形管线中,网格通常被定义为一组顶点,连续的三个顶点构成一个三角形。为了减少数据冗余,可以通过索引缓冲区将三角形定义为一组三个索引,每个索引引用一个不同的顶点。如下图所示:
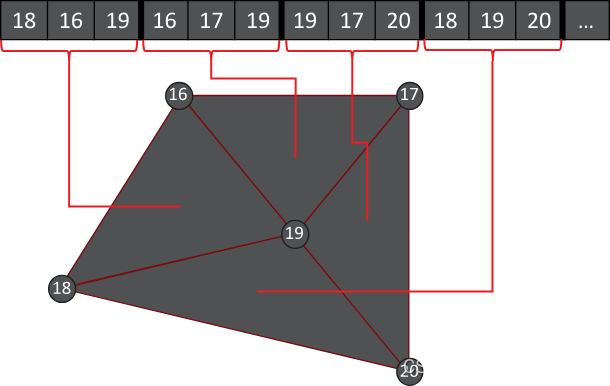
常规流程如下:

对于索引缓冲区引用的每个顶点,GPU都需要运行一个vertex sha
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









