







 本文介绍了参与2018年中国高校计算机大赛大数据挑战赛的经历,详细解析了预测快手用户活跃度的问题,涉及数据集分析、模型架构、特征提取、标签制作以及RNN模型的构建和训练。通过实例展示了如何利用python、深度学习库tensorflow处理序列数据,预测用户未来七天的活跃度。
本文介绍了参与2018年中国高校计算机大赛大数据挑战赛的经历,详细解析了预测快手用户活跃度的问题,涉及数据集分析、模型架构、特征提取、标签制作以及RNN模型的构建和训练。通过实例展示了如何利用python、深度学习库tensorflow处理序列数据,预测用户未来七天的活跃度。
文章目录
大赛
第三届BDC——快手活跃用户预测
全称
2018中国高校计算机大赛——大数据挑战赛(Big Data Challenge)
地址
https://www.kesci.com/home/competition/5cb80fd312c371002b12355f
前言
不知道你是否遇到过这样的一些疑惑,就是涉足一个新领域的时候,比如数据挖掘,先非常努力的花时间学习python,numpy,pandas,scipy,sklearn这些基础知识,但是当后面真的遇到实际问题的时候,却不知道如何下手去分析,再回头想掏之前学会的工具时,发现这些工具依然在,但已记不清它们的使用说明。难不成之前学习过的这些都白学了? 其实不是的,这些工具都在,只不过我们之前没有真正的去用过它, 所以,比赛就是一个让我们大展身手的舞台,通过解决实际问题,我们才能真正掌握之前的工具,也是学习知识的一个融合,毕竟解决实际问题,需要各个领域的知识交融和碰撞。在这个过程中,我们还可以认识一些志同道合的伙伴,一起进步和交流,进行思维的碰撞并得到成长。
所以这个数据竞赛修炼系列我会把我的所思所学都记录下来并分享,一是因为解决问题的思路可以迁移和变换,这样或许会帮助更多的人,二是通过整理和总结,可以使得知识和技能在自己脑海中逗留的时间长一些吧。
首先声明这个系列的每一篇都会很长,并且会有一大波代码来袭,毕竟每一篇都是一个完整的数据竞赛,每一篇都需要很长的时间消化整理,因为我想用最朴素,最详细的语言把每个比赛的思路和代码说给你听。
今天是数据竞赛修炼笔记的第一篇,带来的比赛是2018年科赛网上的一个比赛快手用户活跃度的预测,我们拿到了一份快手平台记录的关于快手用户的30天一个行为数据集(记录用户注册,登录,视频观看与发布,互动的记录),我们的目标就是根据这个行为数据集预测在未来七天的活跃用户。
首先我们会对任务的目标和数据进行分析,然后会概览模型的架构,从模型的角度提取特征和标签构建数据集,然后基于tensorflow建立模型并训练得到结果。最后会再结合一些好的解决方案,对解决这个问题的思路和知识点进行总结。
大纲如下:
- 任务目标与数据分析
- 整理模型架构
- 构建用户特征,生成汇总表
- 制作标签
- 建立模型并训练,得到最后的结果
- 知识点和思路的总结(两个知识点温习:pandas的iterrows()和groupby())
一、任务目标与数据分析
开始之前,需要导入包:
import numpy as np
import pandas as pd
import tensorflow as tf
from deep_tools import f
from deep_tools import DataGenerator
1.数据集介绍
app_launch_log.txt 用户30天内登陆的日子
user_activity_log.txt 用户行为数据集 比如对哪个视频进行了点赞转发
user_register_log.txt 用户当前是在哪天进行注册的
video_create_log.txt 视频的创建
2.数据集说明
为期30天的用户数据
但是如果是第七天注册的,就没有前七天的数据
我们这里就是一个月的用户数据
难点:所有用户的长度不是固定的!!!
解决:从哪天注册的就从哪天算起,预测未来一个周期的活跃度,比如从第七天的预测第14天的、第21天的活跃度这样。
3.读取数据并命名列名
import pandas as pd
register = pd.read_csv('./data/user_register_log.txt',sep='\t',names=['user_id', 'register_day', 'register_type', 'device_type'])
launch = pd.read_csv('./data/app_launch_log.txt',sep='\t', names = ['user_id', 'launch_day'] )# sep="\t" 表示以tab(制表符)为分隔符
create = pd.read_csv('./data/video_create_log.txt',sep='\t', names = ['user_id', 'create_day'])
activity = pd.read_csv('./data/user_activity_log.txt', sep='\t', names = ['user_id', 'act_day','page', 'video_id', 'author_id', 'act_type'])
4.查看每个数据集的前五行
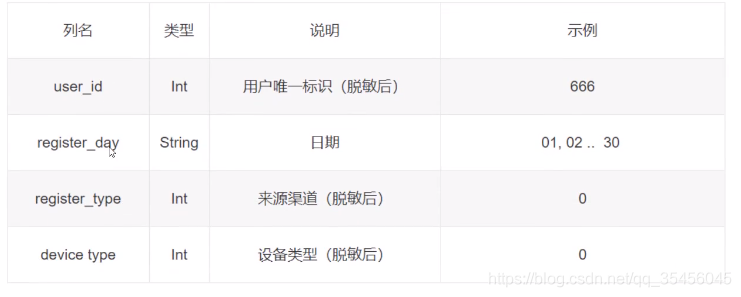
(1)注册日志
register.head()

注册日志说明
第一列是用户的id,第二列是注册的时间,不是具体的某一天,1就是第一天,第三列是当前注册的类型,类似于微信登陆,手机登录等等,第四列是设备类型,脱敏后数据,直接拿过来用
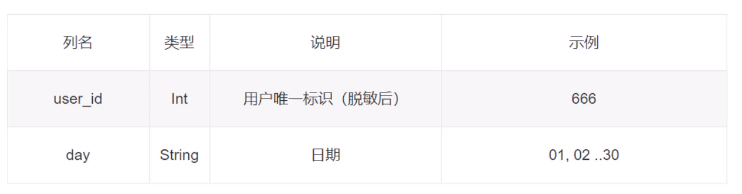
(2)APP启动日志
launch.head()

APP启动日志说明
第一列是用户id,第二天是启动app的天,是启动的某一天,比如330966用户在4,9,11,12都启动了
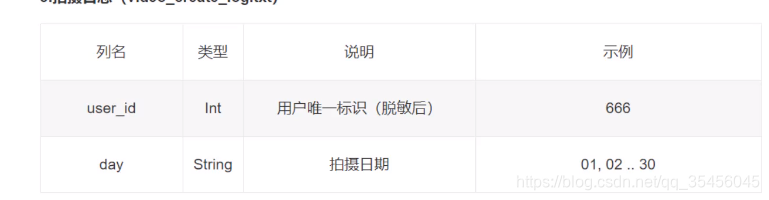
(3)拍摄日志
create.head()

拍摄日志说明
只有这个用户的id和用户在哪一天创建了视频
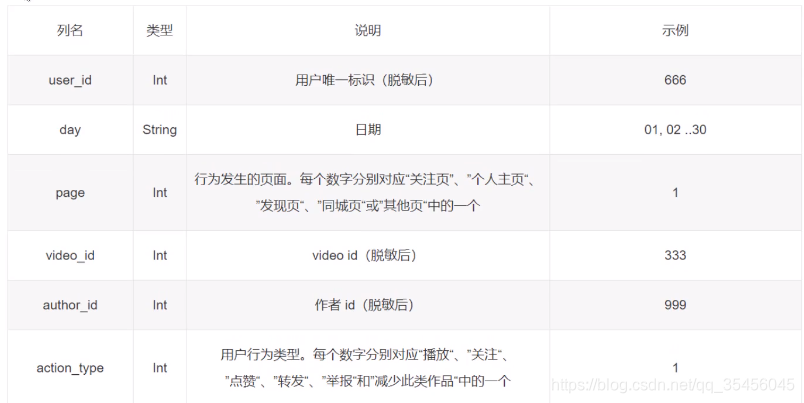
(4)行为日志
activity.head()

行为日志说明
用户id,进行行为的哪一天,行为发生在哪一页(比如自己的主页),操作了什么视频id,看的作者的id,操作的动作是什么(比如点赞,转发)
二、整体模型架构
目的:预测一个二分类
方法还是很多的,比如xgboost,神经网络都可以
我们拿到的是序列数据
比如一个用户第七天到第三十天的数据,预测第37天的数据
我们打算用RNN神经网络来做,如果要预测第37 天的可以根据前的每一天都预测一下下一个七天的数据
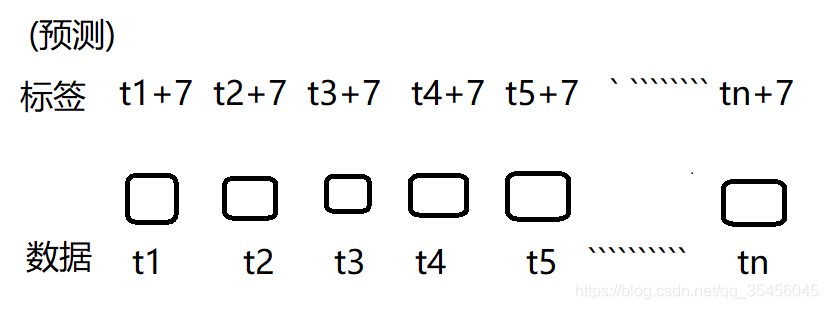
活跃:当天有登陆就是活跃的为1,label序列可以构建出来的,11100001110101011001类似的
以上就是RNN的基本模型架构
三、构建用户特征序列
这个月第一天注册的用户序列数有30
第二天注册的用户序列数只有29
···
第三十天注册的用户序列数就只有1
那我们要查看一下数据的这个情况
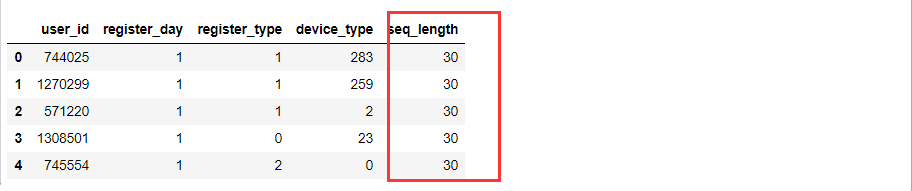
给register表多加一个序列长度seq_length
#给register表多加一个序列长度seq_length
register['seq_length'] = 31-register['register_day']
register.head()
构建字典存储用户在持续时间内,不同日期的数据
序列为1的:【用户id,用户id】
序列为2的:【用户id,用户id】
······················
序列为30的:【用户id,用户id】
# 会产生user_queue = {1:[], 2:[], 3:[], ...,30:[]}
user_queue = {
i:[] for i in range(1,31)}
当前用户里面的索引和值都提取出来,row[-1]就是注册的长度,row[0]就是用户的id。(取到注册的长度,把用户的id放进去)
实现:
for index,row in register.iterrows():
user_queue[row[-1]].append(row[0])
user_queue

我们模型中的t1,t2,tn都需要传入数据的
比如用户持续了三十天
构造数据:

构建数据特征:
class user_seq:
def __init__(self,register_day,seq_length,n_features):
self.register = register_day
self.seq_length = seq_length
self.array = np.zeros([self.seq_length,n_features])#构建矩阵:持续天数*特征个数,后续新创建的特征来往里面填充
self.array[0,0] = 1
self.page_rank = np.zeros([self.seq_length])
self.pointer = 1
def put_feature(self, feature_number, string):
for i in stringing.split(','):
pos, value = i.split(':')#注册第几天进行了登陆,1为指示符
self.array[int(pos) - self.register_day, feature_number] = 1
def put_PR(self,string):
for i in string.split(','):
pos, value = i.split(':')
self.page_rankge_rank[int(pos) - self.register_day] = value
def get_array(self):
return self.array
def get_label(self):
self.label = np.array([BNone]*self.seq_length)
active =self.array[:,:10].sum(axis =1)
for i in range(self.seq_length-7):
self.label[i] =1*(np.sum(active[i+1:i+8])>0)
return self.lable
n_features = 12
data = {
row[0]:user_seq(register_day=row[1],seq_length=row[-1], n_features = n_features) for index, row in register.iterrows()}
data
在注册日志中的每一个样本进行操作的
每一个id都对应着特征
data的结果是
每一个id对应着一个特征矩阵
不过到此为止特征矩阵里面的值都是0
四、序列特征提取方法
我们要在特征中进行选择了,一共有十二个特征
1.登陆信息
预处理次数每个用户每天登陆的次数设置为1
launch.head()

launch['launch'] = 1
launch.head()

重复出现的数据进行加和,处理一天登录多次
比如一直出现用户id为16 登录天数为第23天
launch_table = launch.groupby(['user_id','launch_day'], as_index = False).agg({
'launch':'sum'})
launch_table.head()

我们要把它整理成这种格式
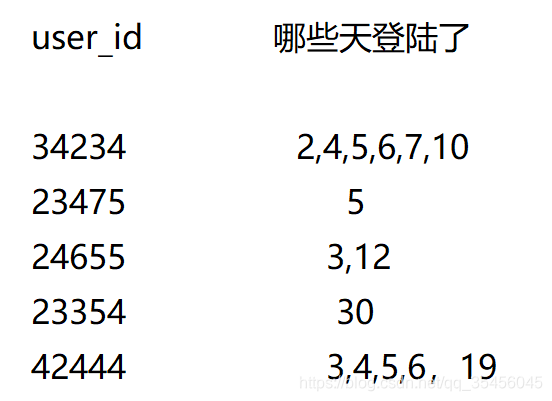
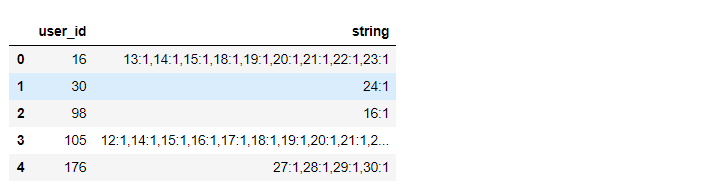
自己定义的将表格变成用户特征序列表
def record_to_sequence(table): #得到用户特征序列表
table.columns=['user_id','day','value']
table.sort_values(by=['user_id','day'],inplace=True)
table['string']=table.day.map(str)+':'+table.value.map(str)
table=table.groupby(['user_id'],as_index=False).agg({
'string':lambda x:','.join(x)})
return table
launch_table = record_to_sequence(launch_table)
launch_table.head()
for index,row in launch_table.iterrows():
data[row[0]].put_feature(1,row[1])
data
五、生成特征汇总表
2.创作视频信息
create.head()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









