







 本文介绍了一种名为ASFF(Adaptive Spatial Feature Fusion)的方法,该方法旨在改善多尺度特征融合过程,尤其适用于目标检测任务。通过自适应学习不同尺度特征地图的空间权重,ASFF能够更有效地融合多层特征,从而提升模型的整体性能。实验结果显示,在不增加大量计算成本的情况下,基于ASFF的模型在COCO数据集上的表现显著优于原始YOLOv3。
本文介绍了一种名为ASFF(Adaptive Spatial Feature Fusion)的方法,该方法旨在改善多尺度特征融合过程,尤其适用于目标检测任务。通过自适应学习不同尺度特征地图的空间权重,ASFF能够更有效地融合多层特征,从而提升模型的整体性能。实验结果显示,在不增加大量计算成本的情况下,基于ASFF的模型在COCO数据集上的表现显著优于原始YOLOv3。
https://github.com/ruinmessi/ASFF
文章:https://arxiv.org/pdf/1911.09516v2.pdf
1070 416 50ms ( 20fps)
1 增强的 baseline
为了更好地证明我们提出的ASFF方法的有效性,我们基于这些先进技术建立了一个比origin yolov3强得多的基线。
在高级训练技巧[43]( Bag of freebies for training object detection neural networks)之后,我们介绍了训练过程中的一些技巧,
如混合算法[12]、余弦[26]学习速率调度和同步批处理规范化技术[30]。除了这些技巧之外,我们还像[45]一样添加了一个无锚分支来与基于锚的分支一起运行,并利用[38]提出的锚引导机制来改进结果。此外,为了更好地进行包围盒回归,在原光滑L1损失上使用了额外的交并(IoU)损失函数[41]。
训练技巧
[43]( Bag of freebies for training object detection neural networks)
[12] Zhang Hongyi, Cisse Moustapha, N. Dauphin Yann, and David Lopez-Paz. mixup: Beyond empirical risk minimization. ICLR, 2018.
[26] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983,2016.
[30] Chao Peng, Tete Xiao, Zeming Li, Yuning Jiang, Xiangyu Zhang, Kai Jia, Gang Yu, and Jian Sun. Megdet: A large mini-batch object detector. In CVPR, 2018
无锚点
[38] Jiaqi Wang, Kai Chen, Shuo Yang, Chen Change Loy, and
Dahua Lin. Region proposal by guided anchoring. In CVPR,
2019.
[45] Chenchen Zhu, Yihui He, and Marios Savvides. Feature selective anchor-free module for single-shot object detection.In CVPR, 2019.
bbox损失函数
Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao, and Thomas Huang. Unitbox: An advanced object detection network. In ACMM, 2016.
利用上述先进技术,在COCO[22]2017 val集合上以50 FPS的(在特斯拉V100上)获得38.8%的mAP,大大提高了原始的YOLOv3-608基线(33.0%的mAP,52 FPS[31]),而无需大量的计算成本。
2 改进特征融合
不同于以往的基于元素和或级联的多层次特征融合方法,核心思想是自适应地学习各尺度特征地图融合的空间权重。如图2所示,它由两个步骤组成:相同的重新缩放和自适应融合。
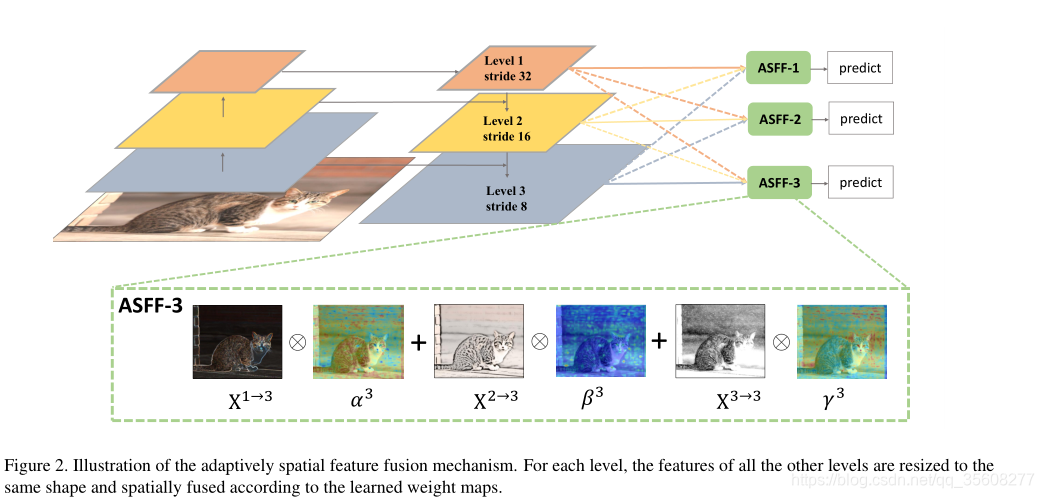
尺度调整
x1 x2 x3 具有不同的分辨率和不同的通道数,去、为了融合要一致。

因此我们相应地修改了每个尺度的上采样和下采样策略。对于上采样,我们首先使用1×1卷积层将特征的通道数压缩到l级,然后分别使用插值来提高分辨率。对于1/2比例的下采样,我们简单地使用一个3×3的卷积层(步长为2)来同时修改通道数和分辨率。对于1/4的比例,我们在2步卷积之前添加了一个2步最大池层。
特征融合
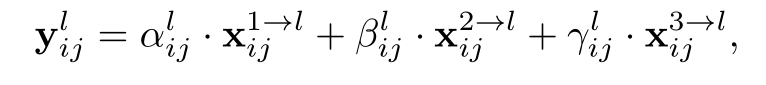
alpha beta gama是0~1权重,并和为一。用三者加权。
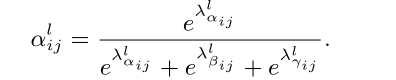
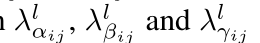
为训练的参数
各层三部分可视化和融合后结果


梯度计算
链式法则+近似
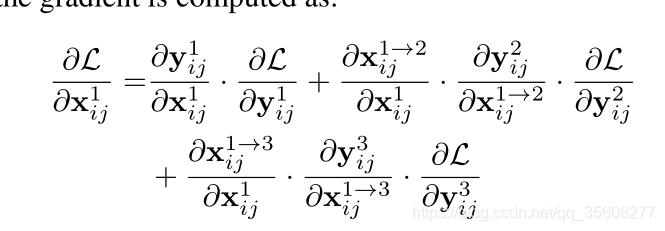
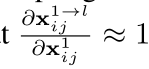
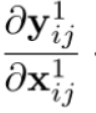
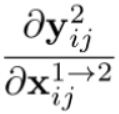
对应融合系数
所以:
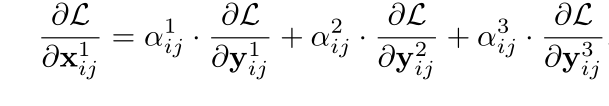
结果

class ASFF(nn.Module):
def __init__(self, level, rfb=False, vis=False):
super(ASFF, self).__init__()
self.level = level
self.dim = [512, 256, 256]
self.inter_dim = self.dim[self.level]
# 每个level融合前,需要先调整到一样的尺度
if level==0:
self.stride_level_1 = add_conv(256, self.inter_dim, 3, 2)
self.stride_level_2 = add_conv(256, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 1024, 3, 1)
elif level==1:
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.stride_level_2 = add_conv(256, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 512, 3, 1)
elif level==2:
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.expand = add_conv(self.inter_dim, 256, 3, 1)
compress_c = 8 if rfb else 16 #when adding rfb, we use half number of channels to save memory
self.weight_level_0 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c*3, 3, kernel_size=1, stride=1, padding=0)
self.vis= vis
def forward(self, x_level_0, x_level_1, x_level_2):
if self.level==0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level==1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized =x_level_1
level_2_resized =self.stride_level_2(x_level_2)
elif self.level==2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=4, mode='nearest')
level_1_resized =F.interpolate(x_level_1, scale_factor=2, mode='nearest')
level_2_resized =x_level_2
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)
# 学习的3个尺度权重
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
# 自适应权重融合
fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\
level_1_resized * levels_weight[:,1:2,:,:]+\
level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out
ubuntu环境
安装apex
https://github.com/NVIDIA/apex
Compile the DCN layer
./make.sh
更新torchvision
torchvision’ has no attribute ‘ops’
https://pypi.org/project/torchvision/#files
下载whl文件安装

















 8500
8500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









