






摘要
This week I read an article that proposed an efficient data augmentation method, termed text smoothing, by converting a sentence from its one-hot representation to a controllable smoothed representation.The lack of data status shows that text smoothing greatly outperforms various mainstream data enhancement methods. In addition, text smoothing can be further combined with various data enhancement methods to achieve better performance.
本周学习了一篇文章,该文章提出了一种有效的数据增强方法–text smoothing,它主要是把句子从独热编码的表示转换为可控的平滑表示。在缺乏数据的情况下表明,text smoothing的性能大大优于各种主流数据增强方法。此外,text smoothing可以进一步与各种数据增强方法相结合,以获得更好的性能。
文献阅读
论文:Text Smoothing: Enhance Various Data Augmentation Methods on Text Classification Tasks
作者:Xing Wu, Chaochen Gao, Meng Lin, Liangjun Zang, Zhongyuan Wang, Songlin Hu
研究背景
数据增强是一种广泛使用的技术,特别是在资源匮乏的情况下。它增加了训练数据的大小,以缓解过拟合,提高了深度神经网络的鲁棒性。在自然语言处理(NLP)领域,各种各样地提出了数据增强技术。最常用的方法之一是在一个句子中随机选择标记,然后用语义上相似的标记替换它们来合成一个新的句子。
BERT(Devlin等人,2018年)的掩码语言建模(MLM)任务完成的上下文增强工作。MLM将被掩蔽的句子作为输入,通常句子中15%的原始代币将被[MASK]代币取代。
一个不可忽视的情况是,在训练前,一些标记比其他标记在类似的环境中出现得更频繁,这将导致模型对这些标记有偏好。这对细粒度高情绪分类等下游任务有害的。
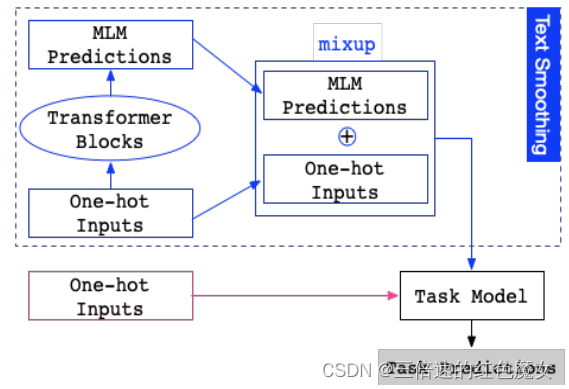
于是作者提出了text smoothing来解决该问题:用插值平滑的表示原始独热编码。通过插值,作者可以扩大原始标记的概率,并且概率仍然主要分布在上下文兼容的单词上,如下图所示。

Text Smoothing
Text Smoothing如下图所示。蓝色部分为使用文本平滑数据增强用于下游任务,可以看出主要分为两个部分,首先从 one-hot 输入开始,经过 MLM 得到 token 的概率分布,然后再和 one-hot 进行加权和,得到的结果来代替 one-hot。红色部分则为原来的输入。
使用文本平滑表示代替 one-hot 表示作为模型的输入,可以看作是一种有效的加权数据增强方法。为了在 MLM 中只用一个前向过程获得整个句子的所有标记的平滑表示,论文中没有显式地Mask输入。相反,则是打开 MLM 的 dropout,并在每一层动态随机丢弃一部分权重和隐藏状态。
mixup融合公式为:
其中ti为单热表示,MLM(ti)为平滑表示,λ为控制插值强度的平衡超参数。在下游任务中,作者使用插值表示,而不是原始的单热表示作为输入。
实验
作者首先比较了Text Smoothing和基线数据增强方法在低资源条件下对不同数据集的影响。然后,作者进一步探讨了将文本平滑与每种基线方法相结合的效果。考虑到组合后的数据量增加到2倍,为了比较的公平性,将基线实验中使用的数据扩展到相同的量。
纯Text Smoothing在缺少数据环境下不同数据集上与其他数据增强方法的比较如下图所示:
与其他数据增强方法相比,文本平滑在三个数据集上的模型效果最好。与不增加数据的训练相比,文本平滑在三个数据集上的性能平均提高了11.62%,效果显著。
在缺少数据条件下,Text Smoothing结合其他数据增强方法的效果如下图所示:
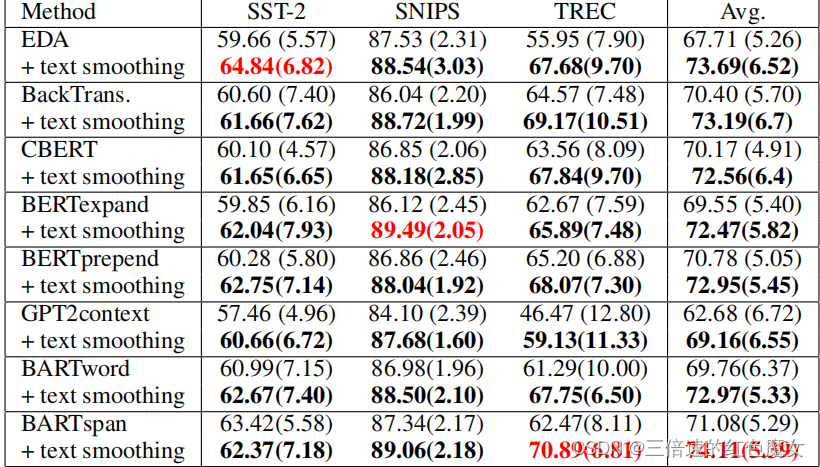
如图所示,Text Smoothing可以很好地与各种数据增强方法结合并可以进一步改进原来的数据增强方法。
研究贡献
(1)在缺乏数据状态的情况下,文本平滑算法的性能大大优于各种主流数据增强方法。(2)文本平滑可以进一步与各种数据增强方法相结合,以获得更好的性能。
总结
本周因为考试耽误了不少时间,下周会继续深入研究时序模型和阅读NLP相关论文。















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









