






摘要
This week I read an article about the Transformer model,Because the pre-trained model GPT used by ChatGPT is modified based on the decoder in Transformer. The innovation point of the article is the transformer based solely on attention mechanisms,dispensing with RNN and CNN entirely.On experiment,the transformer model outperforms the best previously models。In addition, I calculated the structure of the model.
本周我学习了一篇关于Transformer模型的文章,因为ChatGPT 使用的预训练模型 GPT,是在 Transformer 中的 decoder 基础上进行改造的。该文章的创新点在于Transformer模型基于注意机制并完全摒弃了RNN和CNN。实验证明,Transformer比以前的模型效果更好。此外,我还计算了该模型的结构。
Transformer
transformer是一个seq2seq结构的模型,Encoder 和 Decoder 都包含 6 个 block。
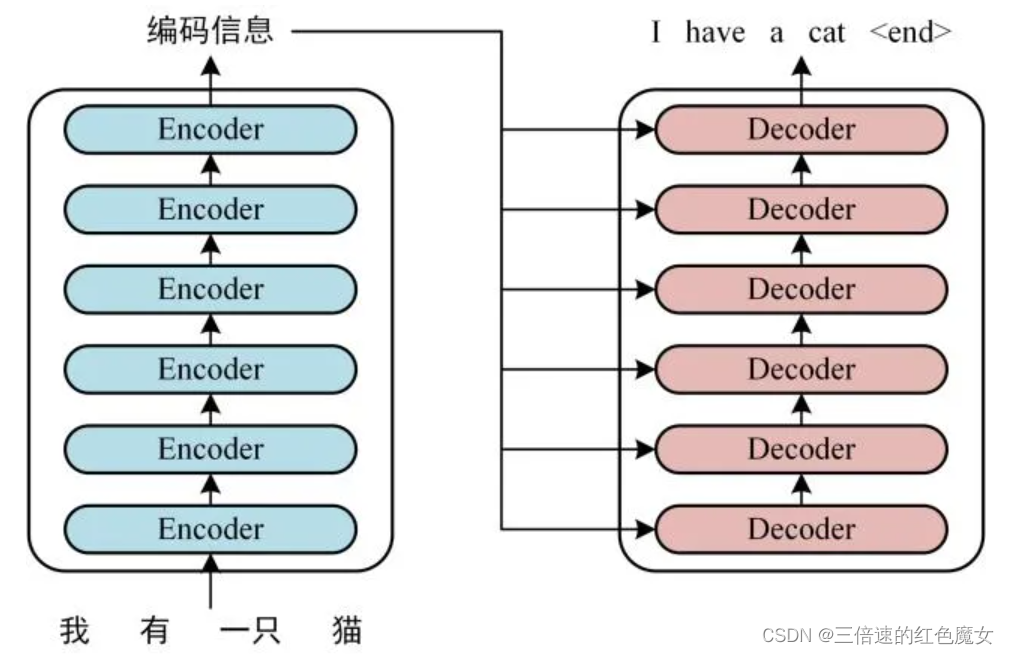
Transformer 的工作流程大体如下,下面将会分Encoder和Decoder部分进行流程运算。
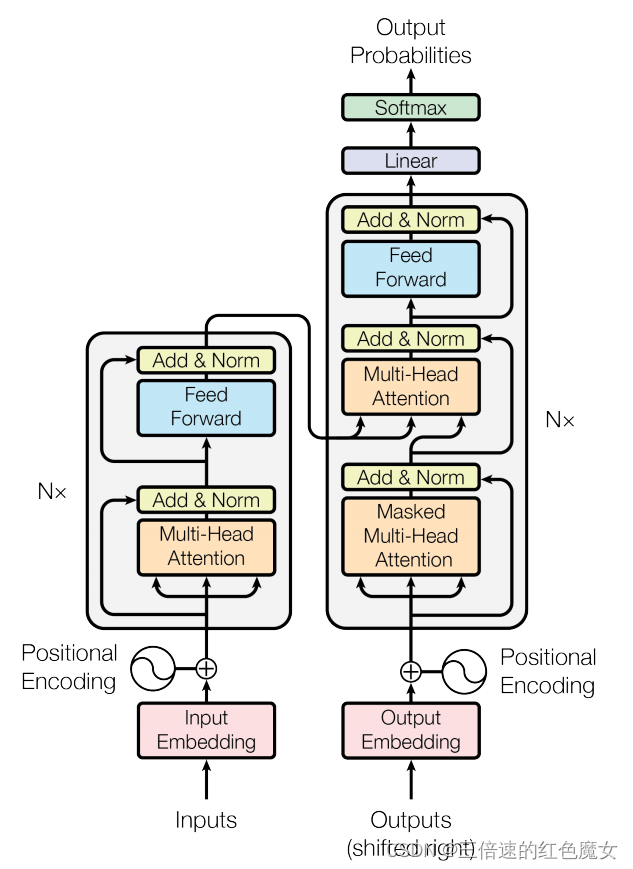
Encoder
Encoder部分首先会获取输入句子的每一个单词的表示向量 ,由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
其次输入向量会分成多个向量通过Multi-Head Attention,它是由多个 Self-Attention组成,对拆分后的多个输入向量计算多个Attention值后再将其相加。
通过FC层后最后会通过 Add & Norm 层,Add 表示残差连接 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
Decoder
Decoder部分的第一个 Multi-Head Attention 采用了 Masked,因为Decoder部分的任务是需要根据之前的翻译,求解当前最有可能的翻译,所有要用Masked把后面的词进行掩盖,让模型通过当前的词和以前词进行预测分类。 Masked-Multi-Head Attention得到的值作为query,Encoder的输出作为value和key,再次进入Multi-Head Attention 剩下操作与Encoder部分相同。
文献阅读
论文名:《Attention Is All You Need》
作者:Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Aidan N. Gomez
摘要
主流的序列转换模型都是基于复杂的循环神经网络或卷积神经网络,且都包含一个encoder和一个decoder。表现最好的模型还通过attention机制把encoder和decoder联接起来。作者提出了第一个完全基于attention的序列转换模型–Transformer,用multi-headed self-attention取代了encoder-decoder架构中最常用的RNN。
该模型完全避免使用循环和卷积,在两个翻译任务上表明,Transformer在质量上更好,同时具有更高的并行性,且训练所需要的时间更少。通过在大量和少量训练数据上所做的英语选区分析工作的成功,表明Transformer能很好的适应于其它任务。
研究背景
循环神经网络在序列建模和转换任务上,已经是公认的最先进方法。但这种内部的固有顺阻碍了训练样本的并行化,在序列较长时,这个问题变得更加严重,因为内存的限制限制了样本之间的批处理。最近的工作通过因子分解技巧和条件计算在计算效率方面取得了显著的提高,同时也提高了后者的模型性能。然而,顺序计算的基本约束仍然存在。
作者认为注意力机制可以很好的解决这个问题,因为它允许对依赖关系建模,而不需要考虑它们在输入或输出序列中的距离。
但在多数情况下,这种注意机制都与一个递归网络结合使用。作者提出了Transformer,这是一种避免使用循环的模型架构,完全依赖于注意机制来绘制输入和输出之间的全局依赖关系。并且Transformer允许更显著的并行化,使用8个P100 gpu只训练了12小时,在翻译任务上就可以达到一个更好的表现。
Why Self-Attention?
将self-attention layers与常用的recurrent layers和convolutional layers进行以下三方面的比较:
(1)每一层的计算复杂度

如上表所示,在计算复杂度方面,当序列长度N小于表示维度D时,self-attention layers比recurrent layers更快。
(2)并行的计算量
self-attention layer用 O(1)复杂度的操作连接所有位置,而recurrent layer需要O ( n ) 顺序操作。
(3)网络中长距离依赖关系之间的路径长度。
self-attention层的好处是能够一步到位捕捉到全局的联系,解决了长距离依赖,因为它直接把序列两两比较,相比之下,RNN 需要一步步递推才能捕捉到,并且对于长距离依赖很难捕捉。而 CNN 则需要通过层叠来扩大感受野,使得模型更为复杂。
实验
作者在WMT 2014英语-德语数据集上进行了训练,其中包含约450万个句子对。 这些句子使用byte-pair编码,源语句和目标语句共享大约37000个词符的词汇表。除此之外,作者还使用了WMT 2014英法数据集,它包含3600万个句子,并将词符分成32000个word-piece词汇表,实验结果如下: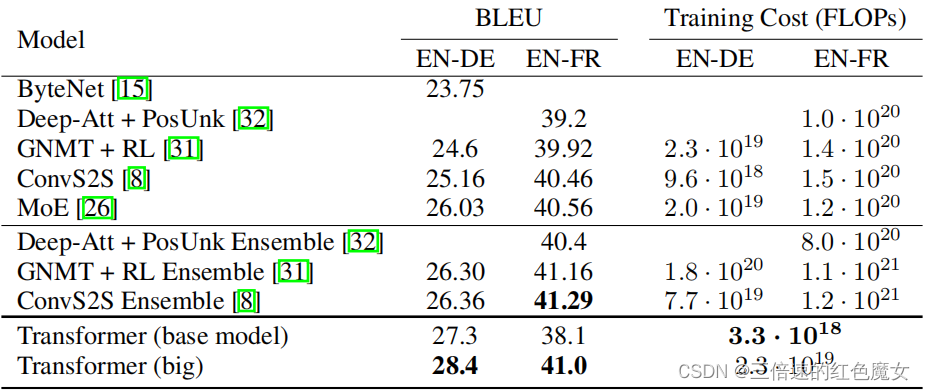
由上图可知,在WMT 2014英语-德语翻译任务中,Transformer (big)比以前报道的最佳模型(包括整合模型)高出2个以上的BLEU评分,以28.4分建立了一个全新的SOTA BLEU分数。 且基础模型也超过了以前发布的所有模型和整合模型,且训练成本只是这些模型的一小部分。
研究贡献
(1)突破了 RNN 模型不能并行计算的限制。
(2)相比 CNN,计算两个位置之间的关联所需的操作次数不随距离增长。
(3)多个注意头(Multi-attention head)关注点不同,可以学会执行不同的任务。
(4)由于 self-attention 没有循环结构,Transformer提出了一种新的方式来表示序列中元素的相对或绝对位置关系----Position Embedding (PE) 。
总结
本周对Transformer进行了学习,对它的运行流程和矩阵运算有了一定的了解,下周会用代码实习Transformer,以及继续了解chatgpt和与其相关的模型。















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









