







前言
应用场景
近年来,智慧城市建设显著改变了城市管理和服务。准确的时空预测是智能城市建设的基础技术之一。例如,交通预测系统可以帮助城市预先分配交通资源和智能控制交通信号。一个准确的环境预测系统可以帮助政府制定环境政策,进而提高公众的健康水平。

基础概念
什么是元学习
meta-learning即元学习,也可以称为“learning to learn”。常见的深度学习模型,目的是学习一个用于预测的数学模型。而元学习面向的不是学习的结果,而是学习的过程。其学习的不是一个直接用于预测的数学模型,而是学习“如何更快更好地学习一个数学模型”。
元学习的分类
- learning good weight initializations : 学习一个好的初始化权重,从而在新任务上实现fast adaptation,即在小规模的训练样本上迅速收敛并完成fine-tune。其中MAML[4]属于本类中的经典算法。本方法也属于此类。
- meta-models that generate the parameters of other models :
- learning transferable optimizers :
MAML
此部分主要参考原论文和【经典论文解析】Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,此博客对MAML的讲解更为详细。因此部分只是为了辅助理解,所以只阐述了基本概念和预训练算法,MAML与分类及强化学习结合的算法,本部分并未涉及。
基本概念理解
MAML 的中文名就是模型无关的元学习。意思就是不论什么深度学习模型,都可以使用MAML来进行少样本学习。论文中提到该方法可以用在分类、回归,甚至强化学习上。
本文的代码是基于分类的,那么就从分类的角度展开对MAML的解析。
本文介绍的MAML,其实是一种固定模型的meta learning ,可能会有人问
不是说MAML是模型无关的吗?为什么需要固定模型?
模型无关的意思是该方法可以用在CNN,也可以用在RNN,甚至可以用在RL中。但是MAML做的是固定模型的结构,只学习初始化模型参数这件事。
什么意思呢?就是我们希望通过meta-learning学习出一个非常好的模型初始化参数,有了这个初始化参数后,我们只需要少量的样本就可以快速在这个模型中进行收敛。
那么既然是learning to learn,那么输入就不再是单纯的数据了,而是一个个的任务(task)。就像人类在区分物体之前,已经看过了很多中不同物体的区分任务(task),可能是猫狗分类,苹果香蕉分类,男女分类等等,这些都是一个个的任务task。那么MAML的输入是一个个的task,并不是一条条的数据,这与常见的机器学习和深度学习模型是不同的。
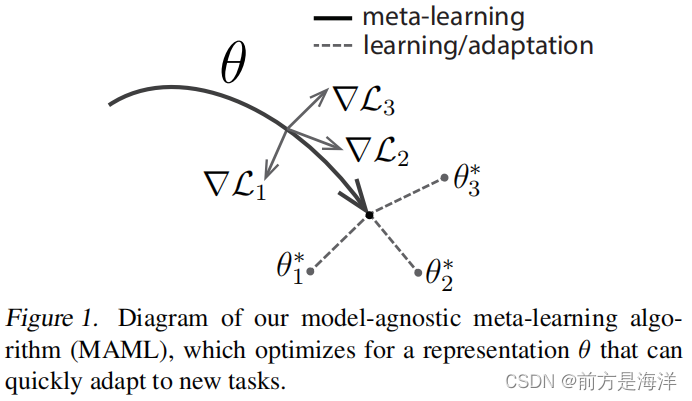
MAML算法实际上优化的是一个可以快速适应新任务的表示 θ \theta θ
MAML中的N-way K-shot learning:
这里的N是用于分类的类别数量。K为每个类别的数据量(用于训练)
MAML中的Task
MAML的论文中多次出现名词task,模型的训练过程都是围绕task展开的,而作者并没有给它下一个明确的定义。要正确地理解task,我们需要了解的相关概念包括Dmeta-train, Dmeta-test, support set, query set, meta-train classes, meta-test classes等等。
我们假设这样一个场景:我们需要利用MAML训练一个数学模型模型 Mfine-tune ,目的是对未知标签的图片做分类,类别包括 P1-P5 (每类5个已标注样本用于训练。另外每类有15个已标注样本用于测试)。我们的训练数据除了 P1-P5 中已标注的样本外,还包括另外10个类别的图片C1-C10(每类30个已标注样本),用于帮助训练元学习模型 Mmeta 。我们的实验设置为5-way 5-shot。
关于具体的训练过程,会在MAML算法详解中介绍。这里只需要有一个大概的了解:
- MAML首先利用 C1-C10的数据集训练元模型Mmeta,再在P1~P5的数据集上精调(fine-tune)得到最终的模型 Mfine-tune。
- 此时,C1-C10即meta-train classes,C1-C10包含的共计300个样本,即 Dmeta-train ,是用于训练Mmeta的数据集。与之相对的,P1-P5 即meta-test classes,P1~P5 包含的共计100个样本,即 Dmeta-test ,是用于训练和测试 Mfine-tune 的数据集。
- 根据5-way 5-shot的实验设置,我们在训练 Mmeta 阶段,从 C1~C10 中随机取5个类别,每个类别再随机取20个已标注样本,组成一个task T 。其中的5个已标注样本称为 T 的support set,另外15个样本称为 T 的query set。这个task T, 就相当于普通深度学习模型训练过程中的一条训练数据。那我们肯定要组成一个batch,才能做随机梯度下降SGD对不对?所以我们反复在训练数据分布中抽取若干个这样的task T ,组成一个batch。在训练 Mfine-tune 阶段,task、support set、query set的含义与训练 Mmeta 阶段均相同。
MAML算法详解
以下为预训练阶段的算法,目的是得到模型Mmeta:

第一个Require指的是在 Dmeta-train中task的分布。结合我们在上一小节举的例子,这里即反复随机抽取task T ,形成一个由若干个(e.g., 1000个)T 组成的task池,作为MAML的训练集。有的小伙伴可能要纳闷了,训练样本就这么多,要组合形成那么多的task,岂不是不同task之间会存在样本的重复?或者某些task的query set会成为其他task的support set?没错!就是这样!我们要记住,MAML的目的,在于fast adaptation,即通过对大量task的学习,获得足够强的泛化能力,从而面对新的、从未见过的task时,通过fine-tune就可以快速拟合。task之间,只要存在一定的差异即可。再强调一下,MAML的训练是基于task的,而这里的每个task就相当于普通深度学习模型训练过程中的一条训练数据。
第二个Require就很好理解啦。step size其实就是学习率,MAML是基于二重梯度的(gradient by gradient),每次迭代包括两次参数更新的过程,所以有两个学习率可以调整。
步骤1,随机初始化模型的参数。
步骤2,是一个循环,可以理解为一轮迭代过程或一个epoch,当然预训练的过程是可以有多个epoch的。
步骤3,相当于pytorch中的DataLoader,即随机对若干个(e.g., 4个)task进行采样,形成一个batch。
步骤4~步骤7,是第一次梯度更新的过程。注意这里可以理解为copy了一个原模型,计算出新的参数,用在第二轮梯度的计算过程中。我们说过,MAML是gradient by gradient的,有两次梯度更新的过程。步骤4~7中,利用batch中的每一个task,我们分别对模型的参数进行更新(4个task即更新4次)。注意这一个过程在算法中是可以反复执行多次的,伪代码没有体现这一层循环,但是作者再分析的部分明确提到" using multiple gradient updates is a straightforward extension"。
步骤5,即对利用batch中的某一个task中的support set,计算每个参数的梯度。在N-way K-shot的设置下,这里的support set应该有NK个。作者在算法中写with respect to K examples,默认对每一个class下的K个样本做计算。实际上参与计算的总计有NK个样本。这里的loss计算方法,在回归问题中,就是MSE;在分类问题中,就是cross-entropy。
步骤6,即第一次梯度的更新。
步骤4~步骤7结束后,MAML完成了第一次梯度更新。接下来我们要做的,是根据第一次梯度更新得到的参数,通过gradient by gradient,计算第二次梯度更新。第二次梯度更新时计算出的梯度,直接通过SGD作用于原模型上,也就是我们的模型真正用于更新其参数的梯度。换句话说,第一次梯度更新是为了第二次梯度更新,而第二次梯度更新才是为了更新模型参数。
关于以上过程,这里再补充一下解释:假设原模型是 θ a \theta_a θa,我们复制了它,得到 θ b \theta_b θb。在 θ b \theta_b θb上,我们做了反向传播及更新参数,得到第一次梯度更新的结果 θ b ′ \theta'_b θb′。接着,在 θ b ′ \theta'_b θb′上,我们将计算第二次梯度更新。此时需要先在 θ b ′ \theta'_b θb′上计算梯度(计算方法如接下来的步骤8所述),但是梯度更新的并非是 θ b ′ \theta'_b θb′而是原模型 θ a \theta_a θa。这就是二重梯度在代码中的实现。
步骤8即对应第二次梯度更新的过程。这里的loss计算方法,大致与步骤5相同,但是不同点有两处。一处是我们不再是分别利用每个task的loss更新梯度,而是像常见的模型训练过程一样,计算一个batch的loss总和,对梯度进行随机梯度下降SGD。另一处是这里参与计算的样本,是task中的query set,在我们的例子中,即5-way*15=75个样本,目的是增强模型在task上的泛化能力,避免过拟合support set。步骤8结束后,模型结束在该batch中的训练,开始回到步骤3,继续采样下一个batch。
θ ← θ − β ∇ θ ∑ T i − p ( T ) L T i ( f θ i ′ ) \theta\gets\theta-\beta\nabla_{\theta}\sum_{T_i-p(T)}\mathcal{L}_{T_i}(f_{\theta'_i}) θ←θ−β∇θ∑Ti−p(T)LTi(fθi′)
m i n θ ∑ T i − p ( T ) L T i ( f θ i ′ ) = ∑ T i − p ( T ) L T i ( f θ − α ∇ θ L i ( f θ ) ) min_{\theta}\sum_{T_i-p(T)}\mathcal{L}_{T_i}(f_{\theta'_i})=\sum_{T_i-p(T)}\mathcal{L}_{T_i}(f_{\theta}-\alpha\nabla_\theta\mathcal{L}_{i}(f_\theta)) minθ∑Ti−p(T)LTi(fθi′)=∑Ti−p(T)LTi(fθ−α∇θLi(fθ))
以上即时MAML预训练得到的全部过程。接下来,面对心得task,在目前的基础上,精调得到方法。
fine-tune的过程与预训练的过程大致相同,不同的地方主要在于以下几点:
步骤1中,fine-tune不用再随机初始化参数,而是利用训练好的初始化参数。
步骤3中,fine-tune只需要抽取一个task进行学习,自然也不用形成batch。fine-tune利用这个task的support set训练模型,利用query set测试模型。实际操作中,我们会随机抽取许多个task(e.g., 500个),分别微调模型,并对最后的测试结果进行平均,从而避免极端情况。
fine-tune没有步骤8,因为task的query set是用来测试模型的,标签对模型是未知的。因此fine-tune过程没有第二次梯度更新,而是直接利用第一次梯度计算的结果更新参数。
摘要
时空预测是构建智能城市的一个基本问题,对交通控制、出租车调度、环境决策等任务具有重要意义。由于数据采集机制,数据采集的空间分布不平衡是很常见的。例如,一些城市可能会发布多年的出租车数据,而另一些城市则只发布几天的数据;一些地区可能有由传感器监测的固定水质数据,而一些地区只有少量的水样本收集。在本文中,作者解决了只有短时间数据采集的城市的时空预测问题。作者的目标是通过迁移学习来利用来自其他城市的长期数据。与以往将知识从单一来源城市转移到目标城市的研究不同,本文是第一个利用来自多个城市的信息来提高迁移的稳定性的研究。具体来说,本文提出的模型被设计为一个具有元学习范式的时空网络。元学习范式学习了时空网络的广义初始化,可以有效地适应目标城市。此外,还设计了一种基于模式的时空记忆机制来提取长期的时间信息(即周期性)。本文在交通(出租车和自行车)预测和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









