









note
InternVL-1.5的三个重要改进:
- InternViT增强:V1.2版本去掉了模型的最后3层,将分辨率扩展为固定448x448,而V1.5进一步扩展为动态448x448,即每张训练图像可分块,每块大小为448x448,支持1~12个块。此外,还增强了数据规模、质量和多样性,提高了OCR和高分辨率处理能力。
- 动态高分辨率:基于图像的分辨率和纵横比,将图像切分为448x448的分块,训练阶段最多12块,测试阶段可以外推到40块,即4K分辨率,这样模型训练和推理能适应多种分辨率和纵横比,避免了强行resize带来的失真和细节丢失。如下图,具体来说,对于一张800x1300的图像,从预定义的纵横比中匹配一个最接近的纵横比2:3,然后将图像resize到896x1344,并切分为多个448x448的图像块,再添加一个缩略视图 (直接resize到448x448) 用于图像全局理解。
- 高质量中英双语数据集:包含自然场景、图表、文档、对话等多样化的数据,借助LLM实现数据集英文到中文的转换。
文章目录
一、InternVL模型
可以参考几个经典的指标:

- 多模态性能提升:InternVL 1.5在OCR、多模态、数学和多轮对话等18个基准测试中的8个中取得了最先进的结果,显示了其在多模态理解方面的卓越性能。
- 强视觉编码器:模型采用了一种持续学习策略,显著提升了视觉理解能力,并且能够在不同的大型语言模型(LLM)中迁移和重用。
模型效果:

和以往模型架构的区别:

1. 训练过程

三阶段训练:
- 视觉-语言对比训练:进行对比学习,将InternViT-6B与多语言LLaMA-7B在网络规模上的嘈杂图像文本对进行对齐
- 视觉-语言生成训练:QLLaMA在第一阶段继承了LLaMA-7B的权重。我们保持InternViT-6B和QLLaMA冻结,仅训练新添加的可学习查询和交叉注意力层。
- 使用过滤后的高质量数据。表2总结了第二阶段的数据集。可以看到,我们进一步过滤了低质量标题的数据,将第一阶段的49.8亿个数据减少到了10.3亿(1.03 billion)个
- 有监督微调:为了强化对话、问答能力,通过MLP层将其与现成的LLM解码器(如Vicuna或InternLM)连接,并进行监督微调
相关训练数据:

2. 使用InternVL的不同方法

3. 模型效果
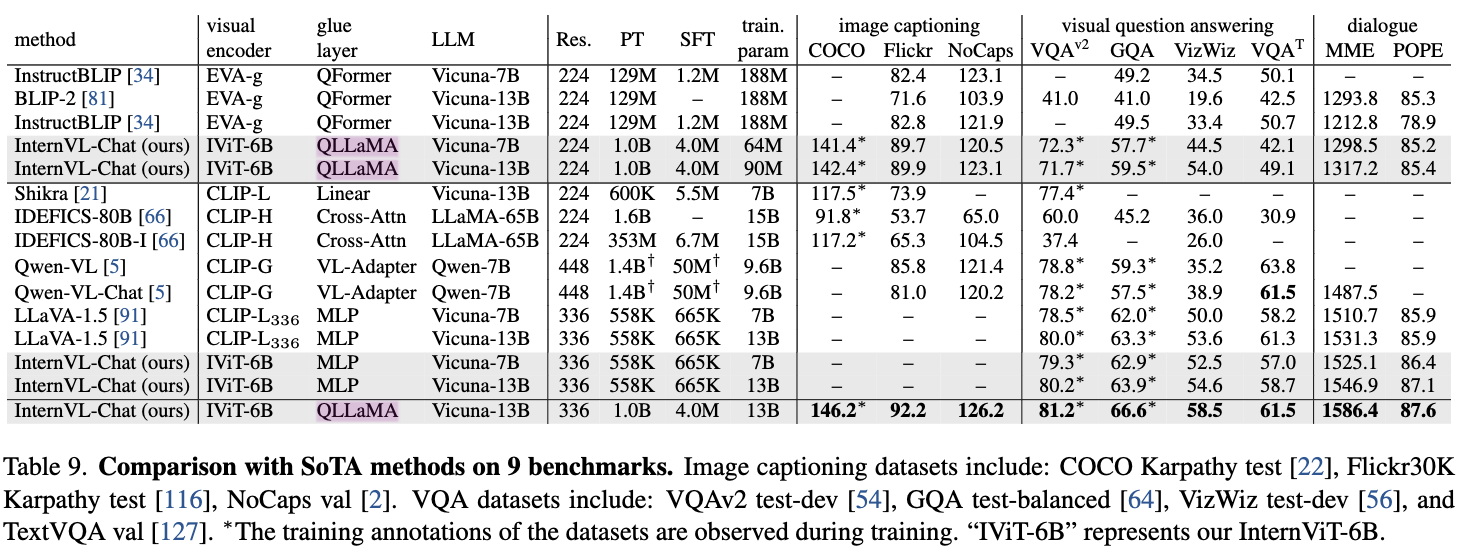
在9个benchmark上和以往sota模型的对比:
二、Intern-VL 1.5模型

- 动态高分辨率:InternVL 1.5能够根据输入图像的长宽比和分辨率,动态地将图像划分为不同大小的图块,最高支持4K分辨率的输入。
- 双语数据集:通过收集和注释高质量的双语数据集,InternVL 1.5在OCR和中文相关任务中表现出色。
- ViT-MLP-LLM架构:模型采用了与流行的多模态大模型相似的架构,通过MLP映射器将预训练的视觉编码器与语言模型结合在一起,并通过Pixel Shuffle技巧减少了视觉标记的数量。
最近的多模态LLM进展:
- 谷歌的 Gemini 系列从 Gemini 1.0 [107] 到 Gemini 1.5 [92] 进行,增强了 MLLM,能够处理文本、图像和音频并支持多达 100 万个标记,从而显着提高了性能
- QwenVL-Plus/Max 是阿里巴巴在 QwenVL 系列 [5] 中的领先模型,在不需要 OCR 工具的情况下在多模态任务中表现出色
- 其他模型:Anthropic 的 Claude-3V 系列 [3]、HyperGAI 的 HPT Pro [35]、Apple 的 MM1 [84]、StepFun 的 Step-1V [102] 和 xAI 的 Grok-1.5V
视觉编码器的研究进展:
- 当前很多MLLM使用CLIP-ViT [91] and SigLIP [136]作为视觉编码器
- LlaVA-HR[76]引入了一种双分支视觉编码器,利用CLIP-ViT进行低分辨率路径,使用CLIP-ConvNext进行高分辨率路径。
- DeepSeek-VL [71] 采用双编码器设计,对低分辨率图像使用 SigLIP-L 和高分辨率图像使用 SAM-B
1. 模型介绍
- 视觉编码器:InternViT-6B
- 动态高分辨率(和很多多模态LLM不一样的地方):我们将图像根据输入图像的纵横比和分辨率划分为1到40块,每块为448×448像素(图像很大则会被切分,每个块被模型独立处理,可以更好地处理图像的细节),从而支持高达4K分辨率的输入(40个小块)。具体的处理方法如下图。
- 采用动态高分辨率:从预定义的比率中动态匹配一个最优的宽高比,将图像划分为448×448像素的瓦片,并创建一个缩略图以捕捉全局上下文。采用这种方法最小化了宽高比的失真,并适应了训练过程中的不同分辨率。
- 使用pixel shuffle将视觉token减少到原来的四分之一(原始为1024个token)。PixelUnshuffle操作(即Space2Depth操作,即把相邻区块的特征从空间维度往通道维度上堆叠,来降低分辨率,但是最近的论文总是写成Pixel Shuffle,与经验叫法相悖)
- InternVL-6B图像编码器:在纯视觉任务和图生文任务上逼近或超过了谷歌的闭源 ViT-22B 模型,并在多模态大模型评测上与 GPT4V、Gemini 等模型竞争相当。
- 动态高分辨率(和很多多模态LLM不一样的地方):我们将图像根据输入图像的纵横比和分辨率划分为1到40块,每块为448×448像素(图像很大则会被切分,每个块被模型独立处理,可以更好地处理图像的细节),从而支持高达4K分辨率的输入(40个小块)。具体的处理方法如下图。

InternVL模型中的动态分辨率操作(Dynamic High-Resolution)是一种适应不同输入图像分辨率和宽高比的方法。这种方法通过将图像分割成固定大小的瓦片(tile),来增强模型处理详细视觉信息的能力,同时适应多样化的图像分辨率。具体来说,操作包括以下几个步骤:
-
动态宽高比匹配(Dynamic Aspect Ratio Matching):首先,模型会从预定义的宽高比集合中动态地匹配最优的宽高比,以保持图像的自然宽高比。例如,集合中可能包含1:1, 1:2, 2:1等宽高比,模型会根据输入图像的宽高比与这些预定义的宽高比进行匹配。
-
图像分割与缩略图(Image Division & Thumbnail):确定合适的宽高比后,图像会被调整到相应的分辨率,然后分割成448×448像素的瓦片。此外,为了捕获全局上下文,模型还会生成整个图像的缩略图,这个缩略图也被缩放至448×448像素。
-
像素洗牌(Pixel Shuffle)操作:这是一种用于减少视觉令牌数量的操作,通过这种操作,可以将图像表示的视觉令牌数量减少到原始数量的四分之一。这有助于提高模型处理高分辨率图像时的计算效率。
- 这里的pixel shuffle操作来源于16年的一篇论文(https://arxiv.org/abs/1609.05158), 本质是对特征元素进行重排列, 将 ( C × r 2 , H \left(C \times r^2, H\right. (C×r2,H, W ) W) W) 的特征变换为 ( C , H × r , W × r ) (C, H \times r, W \times r) (C,H×r,W×r), 对特征进行了空间维度的上采样, 但通道维度缩小为原来的 1 / r 2 1 / r^2 1/r2。这里输出的视觉token数可以理解为通道数, 主要目的是通过提升特征维度换取更少的token数, 从而可以支持更高的图像分辨率。
- 这样, 448 × 448 448 \times 448 448×448 的输入图像, patch size=14, 总共有 32 × 32 = 1024 32 \times 32=1024 32×32=1024 个 token,设置上采样系数 r = 2 r=2 r=2, 则该图像可以表示为 256 个token。
在InternVL 1.5模型中,使用像素洗牌操作是为了在保持图像表示的同时减少模型在处理时所需的视觉令牌数量。这样,即使在测试阶段图像瓦片的数量可以增加到40个(即4K分辨率),模型也能够高效地处理高分辨率输入,实现对高分辨率图像的零样本适应性。总的来说,动态分辨率操作使得InternVL 1.5能够灵活地处理不同尺寸和宽高比的图像,同时通过像素洗牌技术提高处理高分辨率图像时的计算效率。
其他方面:
- 训练语料:大量中英文
- 模态对齐方法:对比-生成融合的渐进式对齐技术
- 模型效果:在OCR和中英文理解评测集上表现出色
- 主要的benchmark:OCR-related, general multimodal, mathematical, and multi-turn conversation benchmarks.
模型架构:

两阶段训练:
- 预训练:对vit和mlp参数更新
- 微调:全参更新参数
翻译的prompt(可参考):
System:
You are a translator proficient inEnglishand{language}.Your task is to translate the following English text into{language}, focusing on a natural and fluent result that avoids “translationese.”Please consider these points:
1.Keep proper nouns, brands,and geographical names inEnglish.
2.Retain technical terms or jargon inEnglish, but feel free to explain in{language}if necessary.
3.Use{language} idiomatic expressions forEnglish idioms or proverbs to ensure cultural relevance.
4.Ensure quotes or direct speech sound natural in{language}, maintaining the original’s tone.
5.For acronyms, provide the full form in{language}with the English acronym in parentheses.
User:
Textfor translation:{text}
Assistant:
{translation results}
2. 训练数据
为了重点提高OCR效果,训练集中还加入了PaddleOCR。

3. 模型效果
和sota模型在16个benchmark的效果对比:

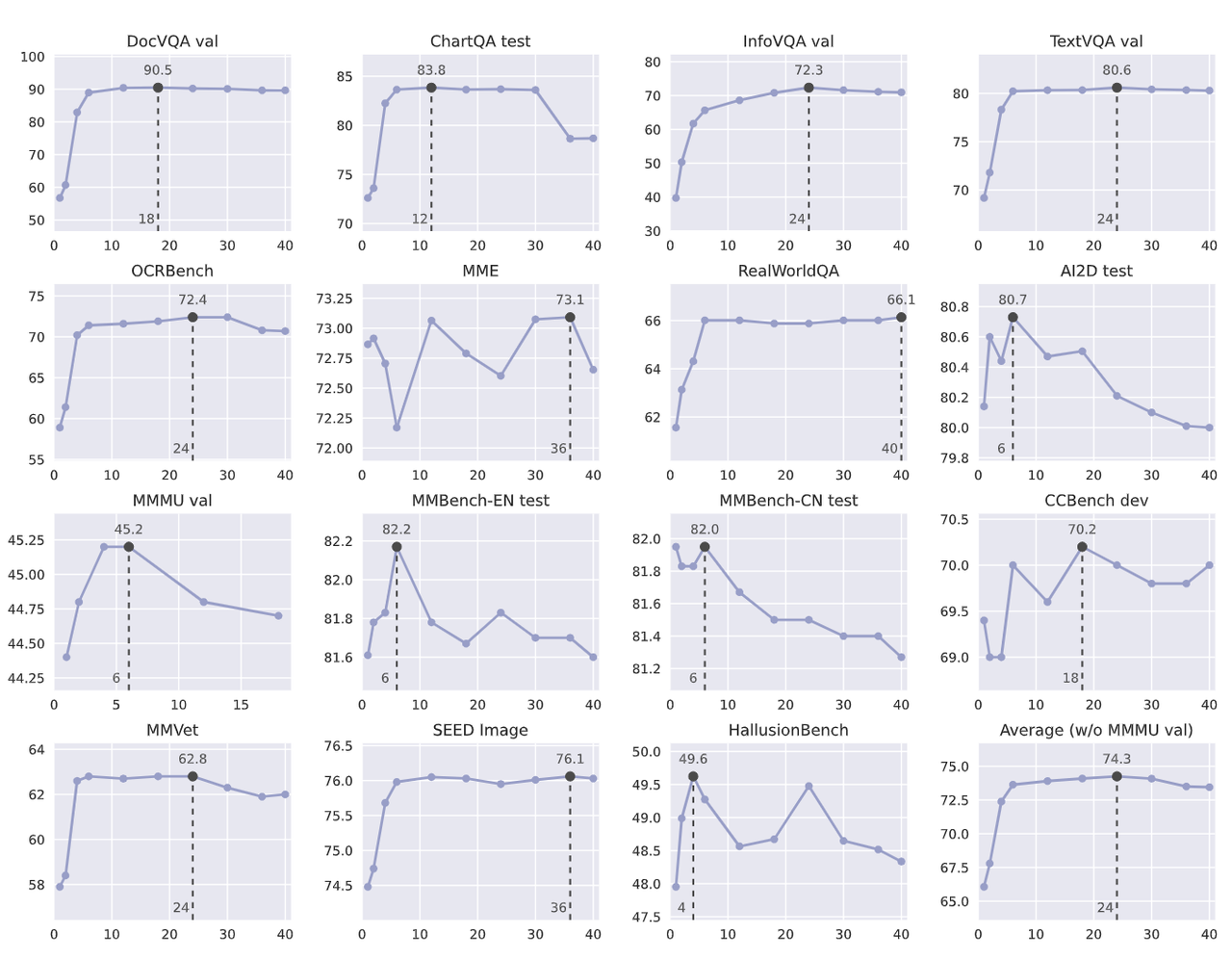
动态分辨率对性能的影响因任务而异。在某些基准测试中,高分辨率可能因增加计算成本而降低性能;而在OCR和文档理解等任务中,高分辨率则能显著提升性能。这强调了为不同任务选择合适分辨率的重要性,并表明动态分辨率是提升多模态模型性能的有效工具。这一结论与mPlug-DocOwl1.5和LLaVa-UHD的研究结果相一致。
其他benchmark:
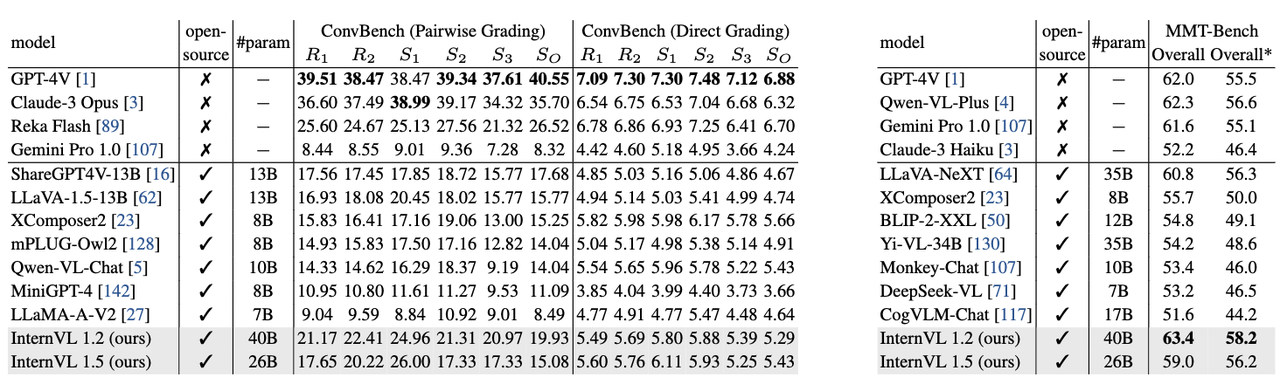
- ConvBench:多轮对话测试集
- R2=(S1 + S2 + S3)/3, 其中S1、S2、S3分别是感知、推理、创造层面的分数。
- R1=(R2 + S0)/2 表示模型的整体能力
- 在多轮对话上,和GPT-4V差距减少
- MMT-Bench:多模态综合评测集,涉及视觉识别、推理、规划等任务
在不同的图像分辨率上的效果如下,不同tiles代表不同分辨率:
相关消融实验:
更大的LLM需要更大的VFM:LLM参数量和LLAVA-NeXT模型相同、训练数据相同,但是intern-vl 1.5有更大VFM情况下效果会更好(但是LLAVA-NeXT处理的分辨率是672 × 672,也没完全控制变量,论文中还是有参考意义)。
三、Intern-VL 2模型
InternVL 2.0的技术报告暂未开源。但模型结构方面和InternVL 1.5没有较大的改动。动态分辨率输入方面,训练中最多12个448×448的patch,测试中最多40个patch(4K分辨率)
- 使用渐进式对齐的训练方法:模型从小到大,数据从粗到精
- 多模态编码器:支持图像,视频,文字,语音、三维点云等模态
- 多模态输出,如images, bounding boxes, and masks
模型架构:

相关模型信息如下,分为两阶段训练:

最近的排名也是非常靠前:

四、LLaVA-UHD模型
背景:LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
- 以往的处理高分辨率图像的做法:
- resize到448x448等(会扭曲;丢失图像细节,比如文字)
- 将图片切片然后把多个patch拼接组成图像emb,作为VIT的输入(但图像token很长)
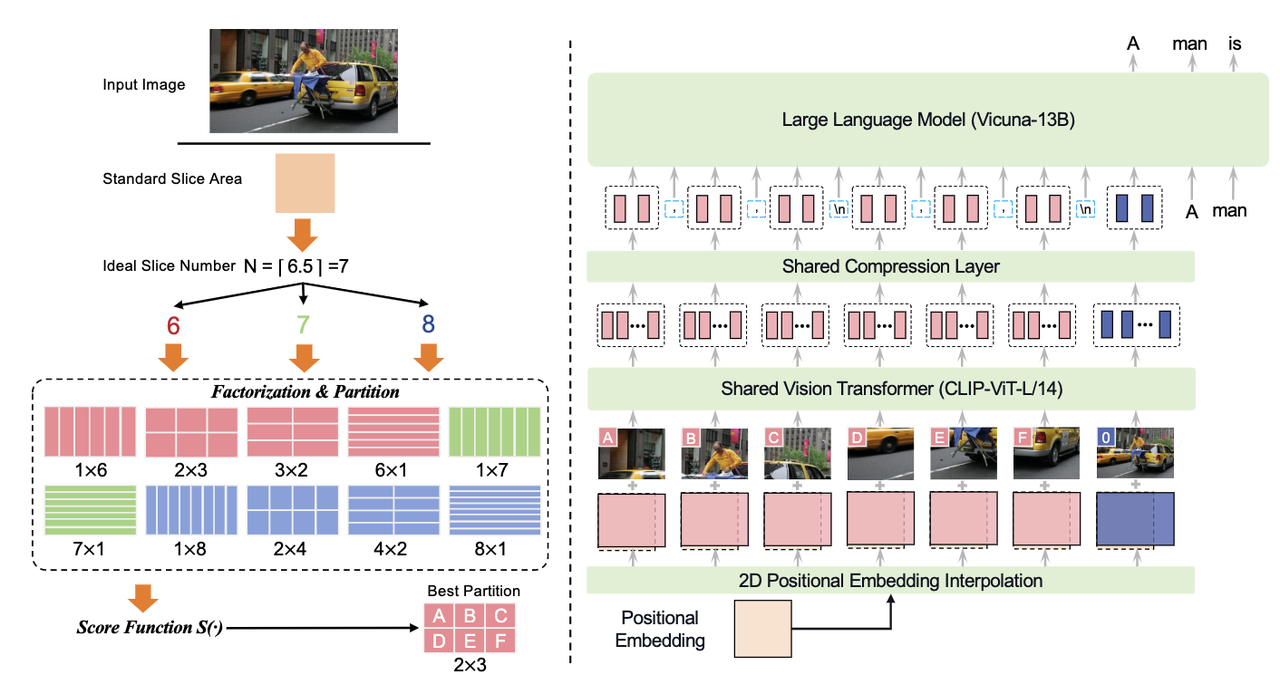
- LLaVA-UHD模型:处理高分辨率图片
- 能处理任何宽高的图片:将原始图片切分为大小不同的切片
- 引入一个压缩层resampler(和q-former类似),压缩视觉token数
- 切片的组织形式:使用特殊字符如\n标记切片在图像中位置(同一行的切片间隔则是,),保证LLM理解图像切片的空间组织
- 模型训练:
- 预训练:对resampler微调
- 指令微调:对resampler+语言模型微调
- 模型效果:
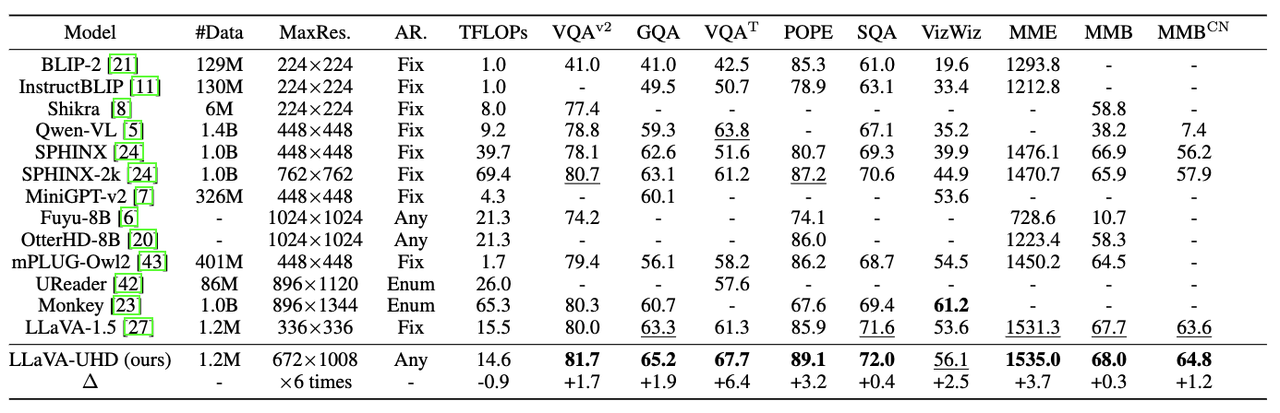
- 和llava-1.5相比,大部分benchmark上都有所提升(且比大部分主流模型强)
- 在处理高分辨图像效果较好,在VQA上提升6.4%
Reference
[1] Intern-vl 2技术博客:https://internvl.github.io/blog/2024-07-02-InternVL-2.0/
[2] 通向高分辨率VLM (5): InternLM-XComposer-4KHD
[3] InternVL-1.5:开源社区最强的多模态大模型成长记录
[4] PixelShuffle面面观(附不同框架的pytorch等价实现)
[5] 多模态MLLM都是怎么实现的(11)–从SadTaler到快手LivePortait
[6] 2024 SOTA多模态大模型架构设计的最佳实践
[7] Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
[8] PixelShuffle详解和cuda实现
[9] 超分任务中的转置卷积、pixelshuffle 和插值上采样
[10] 上海AI Lab:书生大模型 InternLM
[11] InternLM/InternVL系列多模态大模型核心技术解析
[12] 多模态排行榜:https://rank.opencompass.org.cn/leaderboard-multimodal/?m=REALTIME
[13] 【论文学习】InternVL多模态大语言模型
[14] 【论文学习】InternVL 1.5开源的多模态大语言模型
[15] InternLM2.5登顶HuggingFace大模型榜单12B以下榜首有什么亮点,能做哪些有趣应用
[16] AI论文精读之多模态基础模型InternVL.b_zhan
[17] 王文海 InternVL1.5. b_zhan
[18] 深度学习中的各类上采样算子(包括pixel shuffle等)
[19] 低分辨率feature maps的上采样方法:pixelshuffle
[20] https://github.com/thunlp/llava-uhd
[21] 多模态大模型笔记:LLaVA-UHD
[22] 模型权重:https://hf-mirror.com/OpenGVLab/InternVL2-2B


















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











