










note
- DAPO (Decoupled clip & Dynamic sampling Policy Optimization),核心思想:在长 CoT 的大规模 RL 实践中,DAPO 指出样本级 汇总会让长答案的惩罚不足、训练不稳;因此采用 token 级归并的目标、非对称裁剪区间( ε low \varepsilon_{\text{low}} εlow, ε high \varepsilon_{\text{high}} εhigh),并配合动态采样/过滤(剔除极端样本以保持有效梯度)、超长样本的特殊处理等工程策略,显著提升稳定性与可复现性。
- 算法对比:
- GRPO:组相对优势+token 级比率与裁剪;实现简单、无需价值函数,但在长序列/大模型时可能不稳。
- DAPO:工程向增强:token 级归并+非对称裁剪+动态采样+超长样本处理,用于长 CoT 的大规模可复现 RL。
- GSPO:把比率/裁剪移到序列级,与序列级奖励匹配,报告在稳定性与效率上优于 GRPO,MoE 训练尤甚。
文章目录
一、DAPO强化学习
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO (Decoupled clip & Dynamic sampling Policy Optimization)
1、研究背景:
- 问题:测试时扩展(如OpenAI的o1和DeepSeek的R1)为大型语言模型(LLMs)带来了深刻的范式转变,使得模型在竞争性数学和编程任务中表现出色。然而,现有的推理模型的实际算法和关键配方仍然不透明,社区在复现其RL训练结果时仍面临困难。
- 难点:该问题的研究难点在于现有的强化学习训练技术和关键细节被隐藏,导致社区在复现这些结果时遇到挑战,如熵崩溃、奖励噪声和训练不稳定性等问题。
- 相关工作:现有工作主要集中在通过测试时扩展提升LLMs的推理能力,但具体的强化学习算法和训练细节通常不公开,导致复现困难。
2、研究目标:
提出DAPO算法,并开源一个大规模RL系统,该系统在Qwen2.5-32B基础模型上实现了AIME 2024的50分成绩,使用50%的训练步骤超越了之前的最先进结果。
二、研究方法
提出了DAPO算法,包含四个关键技术:Clip-Higher、Dynamic Sampling、Token-Level Policy Gradient Loss和Overlong Reward Shaping。
核心思想:在长 CoT 的大规模 RL 实践中,DAPO 指出样本级 汇总会让长答案的惩罚不足、训练不稳;因此采用 token 级归并的目标、非对称裁剪区间( ε low \varepsilon_{\text{low}} εlow, ε high \varepsilon_{\text{high}} εhigh),并配合动态采样/过滤(剔除极端样本以保持有效梯度)、超长样本的特殊处理等工程策略,显著提升稳定性与可复现性。
目标(token 级、非对称裁剪,最大化):
J DAPO ( θ ) = E [ 1 ∑ i ∣ y i ∣ ∑ i = 1 G ∑ t = 1 ∣ y i ∣ min i ( r i , t ( θ ) A ^ i , clip ( r i , t ( θ ) , 1 − ε low , 1 + ε high ) A ^ i ) ] , J_{\text{DAPO}}(\theta)=\mathbb{E}\left[\frac{1}{\sum_{i}|y_{i}|}\sum_{i=1}^{G}\sum_{t=1}^{|y_{i}|}\min_{i}\left(r_{i,t}(\theta)\hat{A}_{i},\text{clip}(r_{i,t}(\theta),1-\varepsilon_{\text{low}},1+\varepsilon_{\text{high}})\hat{A}_{i}\right)\right], JDAPO(θ)=E ∑i∣yi∣1i=1∑Gt=1∑∣yi∣imin(ri,t(θ)A^i,clip(ri,t(θ),1−εlow,1+εhigh)A^i) ,
其中
r
i
,
t
(
θ
)
r_{i,t}(\theta)
ri,t(θ) 同 GRPO;论文同时详细描述了动态采样与超长截断样本的处理/惩罚等做法。
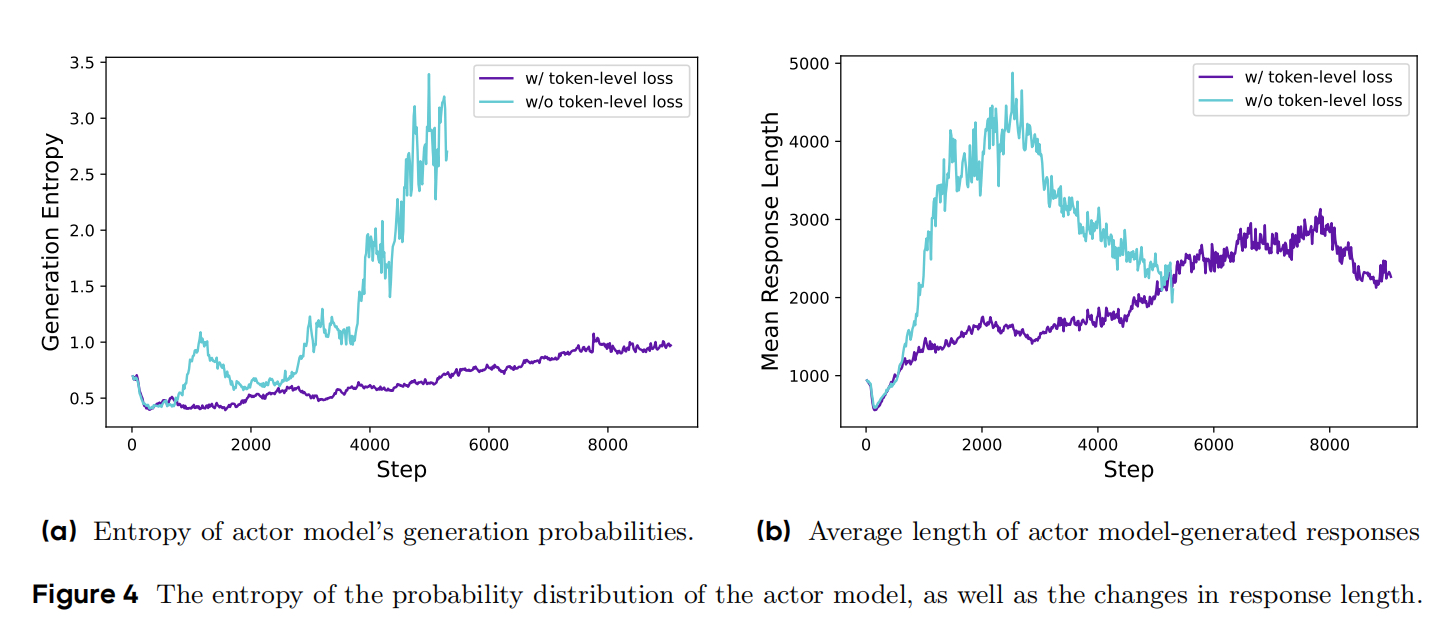
实验证明,DAPO在长思维链任务中表现更稳定,收敛更快(见对比曲线图)。
提出了DAPO算法,包含四个关键技术:Clip-Higher、Dynamic Sampling、Token-Level Policy Gradient Loss和Overlong Reward Shaping。
1、Clip-Higher
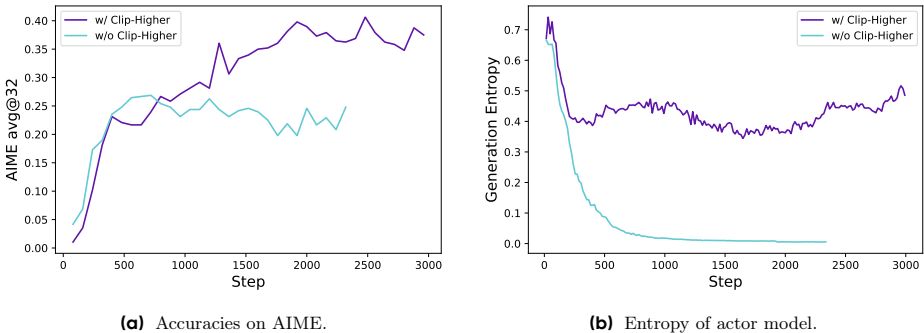
- Clip-Higher:通过解耦上下剪切范围(ε low 和ε high ),提高低概率探索令牌的概率增加空间,增强策略的多样性和熵。
- 为了避免熵崩溃,提出将重要性采样比的上限和下限分离,增加低概率探索令牌的概率上升空间。公式如下:
π θ ( o i ∣ q ) = min ( π θ old ( o i ∣ q ) ⋅ ( 1 + ϵ high ) , 1.08 ) \pi_\theta(o_i \mid q) = \min\left( \pi_{\theta_{\text{old}}}(o_i \mid q) \cdot (1 + \epsilon_{\text{high}}),\ 1.08 \right) πθ(oi∣q)=min(πθold(oi∣q)⋅(1+ϵhigh), 1.08),其中, ϵ high \epsilon_{\text{high}} ϵhigh 设置为 0.28,以允许低概率令牌的概率上升。
- 为了避免熵崩溃,提出将重要性采样比的上限和下限分离,增加低概率探索令牌的概率上升空间。公式如下:

2、Dynamic Sampling
- Dynamic Sampling:通过过采样和过滤掉准确率为0和1的提示,确保每个批次中的提示都有有效的梯度,减少梯度信号的方差。
过采样与过滤:持续采样直到批次中所有prompt的准确率既非0也非1,确保每个批次包含有效梯度信号。
3、Token-Level Policy Gradient Loss
- Token-Level Policy Gradient Loss:在长链推理(long-CoT)场景中,使用基于令牌的损失计算,使较长的序列对整体梯度更新有更大的影响,避免过长样本的低质量模式。
- 问题背景:传统样本级损失平均会削弱长序列中 token的贡献,导致模型忽视长链推理模式。
技术实现:
-
令牌级损失计算:直接对每个token的梯度求和而非按样本平均;
L token = ∑ t = 1 T clip ( r t ) A ^ t log π θ ( o t ∣ q ) L_{\text {token }}=\sum_{t=1}^T \operatorname{clip}\left(r_t\right) \hat{A}_t \log \pi_\theta\left(o_t \mid q\right) Ltoken =t=1∑Tclip(rt)A^tlogπθ(ot∣q) -
效果:
- 长序列获得与其token数量成正比的梯度权重
- 抑制低质量长序列的生成(如重复文本)
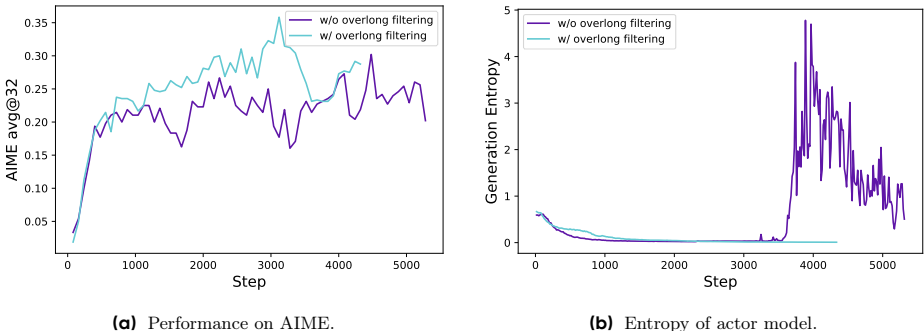
4、Overlong Reward Shaping
- Overlong Reward Shaping:通过软过长的惩罚机制,减少因截断样本导致的奖励噪声,稳定训练过程。
问题背景:直接截断长序列并施加固定惩罚会混淆模型对推理质量的判断。
技术实现:
软惩罚区间:设置16K tokens为理想长度,4K tokens为缓冲区间(总上限20K)。超长部分按比例惩罚:
R
shaped
=
R
origimal
−
λ
max
(
0
,
L
−
16
K
)
4
K
R_{\text {shaped }}=R_{\text {origimal }}-\lambda \frac{\max (0, L-16 K)}{4 K}
Rshaped =Rorigimal −λ4Kmax(0,L−16K)
两阶段策略:
- 过滤阶段:完全屏蔽截断样本的损失
- 惩罚阶段:对16K-20K样本施加线性衰减奖励
三、实验设计
- 数据集:数据集来源于网络和官方竞赛主页,通过网络爬取和手动注释获得。答案格式多样,最终转换为整数形式以便于解析。数据集包括17K个提示,每个提示配对一个整数作为答案。
- 训练框架:使用Verl框架进行训练,采用Naive GRPO作为基线算法,优势估计使用组奖励归一化。
- 超参数配置:使用AdamW优化器,学习率设为1 x 10^-6,线性预热20个展开步骤。展开批次大小为512,每个提示采样16个响应。训练批次大小为512,即每个展开步骤16个梯度更新。超长奖励塑形的最大长度为16384个令牌,额外分配4096个令牌作为软惩罚缓存,总生成长度为20480个令牌。
四、实验结果
- 主要结果:在AIME 2024上的实验表明,DAPO成功将Qwen-32B基模型训练成一个强大的推理模型,性能优于DeepSeek的R1方法。具体来说,DAPO在AIME 2024上的准确率从接近0%提高到50%,且仅用了DeepSeek-R1-Zero-Qwen-32B所需训练步骤的一半。
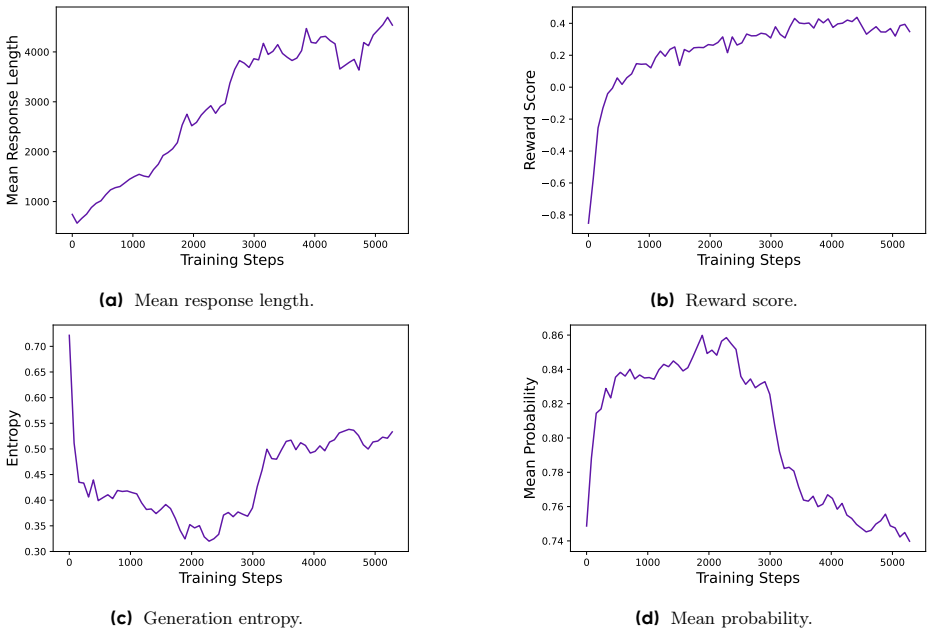
- 训练动态监控:生成的响应长度与训练稳定性和性能密切相关。奖励在训练过程中的增长趋势相对稳定,最终奖励与验证集准确率的相关性较低,表明存在过拟合现象。演员模型的熵和生成概率与模型的探索能力和稳定性密切相关。
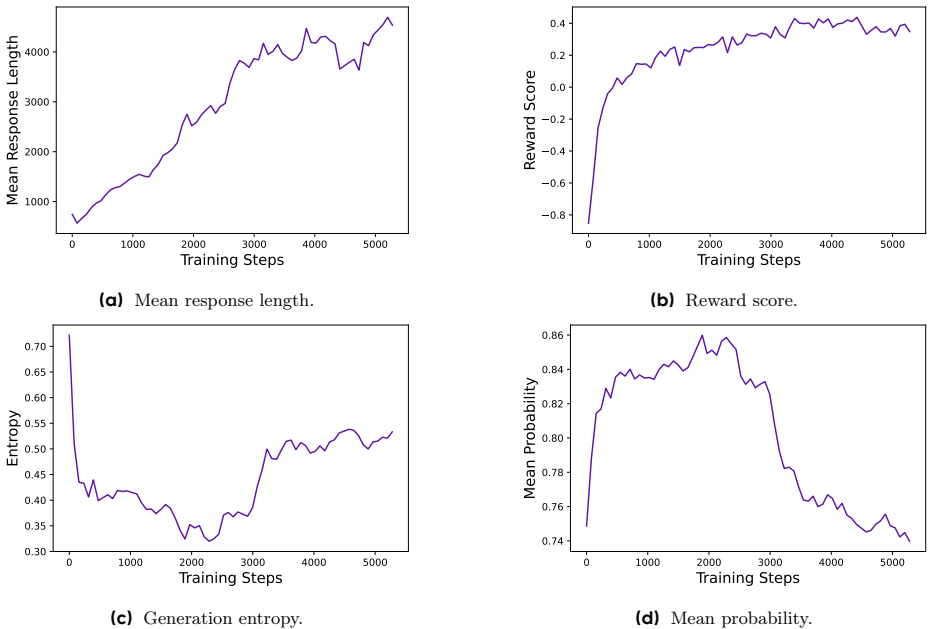
- 案例分析:在RL训练过程中,观察到演员模型的推理模式随时间动态演变。早期阶段几乎没有反思和回溯行为,但随着训练的进行,模型逐渐展现出这些行为。
五、论文分析
1、优点和创新
- 提出了DAPO算法:论文提出了D decoupled Clip and Dynamic sAmpling Policy Optimization)算法,用于解决大规模LLM强化学习中的关键问题。
- 开源系统:完全开源了一个先进的大规模RL系统,包括算法、训练代码和数据集,增强了可重复性并支持未来的研究。
- 关键技术:引入了四项关键技术,包括Clip-Higher、Dynamic Sampling、Token-Level Policy Gradient Loss和Overlong Reward Shaping,显著提升了RL在长链推理任务中的表现。
- 高得分:使用Qwen2.5-32B基础模型在AIME 2024上取得了50分的高分,超过了DeepSeek的47分。
- 数据集转换:对数据集进行了转换和筛选,提供了准确且易于解析的奖励信号,减少了公式解析器引入的错误。
- 详细的实验和分析:提供了详细的实验设置和结果分析,展示了每种训练技术的贡献和改进效果。
2、不足与反思
- 初始性能不足:在初始的GRPO运行中,AIME得分仅为30分,显著低于DeepSeek的47分,表明初始基线存在显著的性能差距。
- 技术细节公开:尽管论文公开了训练代码和数据集,但某些关键的技术细节(如KL惩罚项的移除)可能仍需要进一步的研究和理解。
- 长链推理的复杂性:长链推理任务的复杂性和模型在训练过程中表现出的动态推理模式仍需进一步探索和研究。
- 未来研究方向:论文提到需要进一步研究解释RL算法在推理能力出现过程中的机制,这为未来的研究提供了新的方向。
Reference
[1] DAPO (Decoupled clip & Dynamic sampling Policy Optimization)


















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











