







变分自编码器(Variational Auto Encoder, VAE)
李宏毅机器学习笔记。转载请注明出处。
自编码器(Autoencoder):
Autoencoder = Encoder + Decoder

希望输入(原始数据)和输出(重建数据)尽可能一样。中间的code就是隐变量,也叫Embedding, Representation,Bottleneck…名字花样很多,其实本质都是同一个东西,都是原始数据的低维表示。
● Encoder: Convolution + Leaky Relu +Batch normalization
● Decoder: Convolution transpose + Leaky Relu + Batch normalization
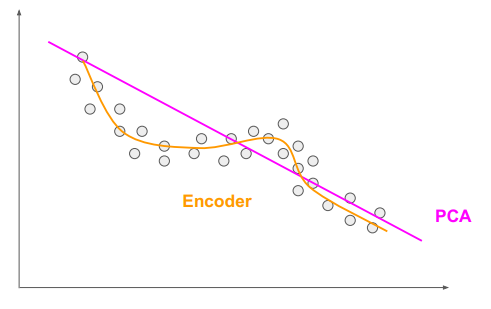
注:PCA和Encoder一样吗?
都有降维作用,PCA学习的是线性关系,Encoder能够学习非线性关系,当Encoder中用线性激活函数的时候,可将其等效于PCA。
自编码器的应用:生成任务、去噪、异常检测…
自编码器存在问题:

变分自编码器:
简介
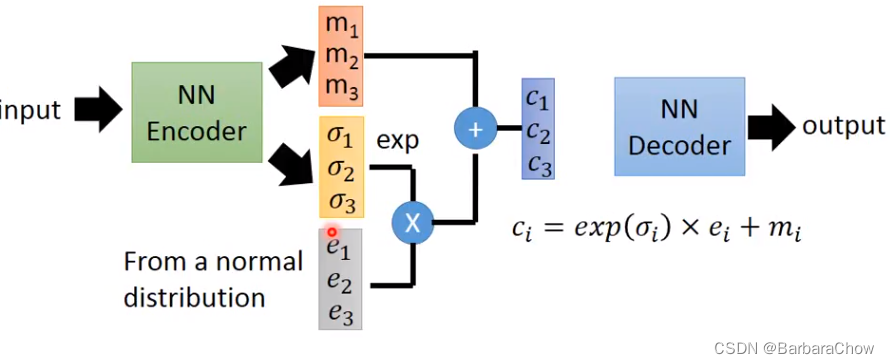
可以看到与自编码器的区别,就是中间多了一部分。
其中的m相当于原来的(自编码器)的code,c是加噪声后的code,σ表示现在噪声的方差(噪声需要多大),是机器学出来的, 取指数e是为了确保得到的值一定是正的,参数e是从一个正态分布里采样出来的(方差固定)。
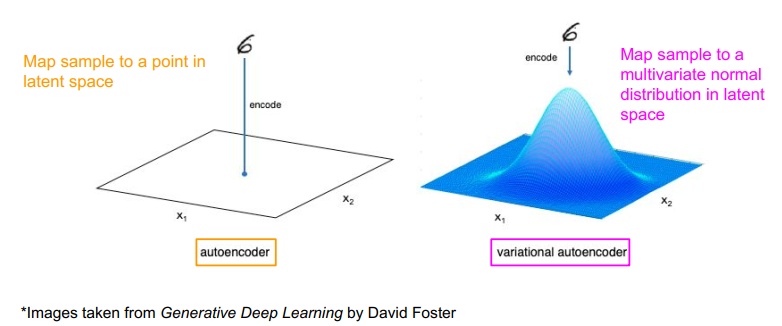
可以看作机器在训一组均值和方差,不像自编码器是让机器学会生成一个具体的向量,而是让机器学习一个数据分布,从这个分布中sample出一个样本,这样就扩大了生成的范围。
VAE假设所有维度相互独立。
损失函数:最小化重建误差
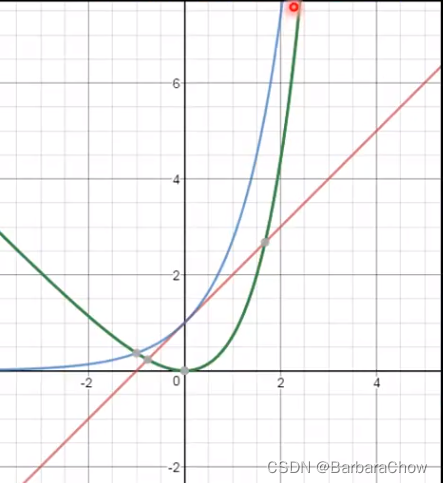
这个式子具体怎么来的,后面有详细介绍,可以先直观了解其物理含义。

含义如下图,蓝曲线对应蓝下划线公式部分,红也是。绿色曲线表示蓝减去红,其最低点等于0(loss最小),所以我们希望σ接近0,方差e^0=1…所以让机器知道方差不能太小。
最后的一项m^2,就是L2正则项,为了不过拟合。
VAE与自编码器比较
为什么要用VAE?原来的自编码器有什么问题?
1.首先从直观上看:
如果是自编码器,就是把每个图片都变成一个code,那么
藏从满月和半月的code中间取一个点,输入decoder,会输出什么呢?现在我们用的神经网络都是非线性的,所以很难预测会输出什么。可能会输出一个看起来什么都不像的图片。
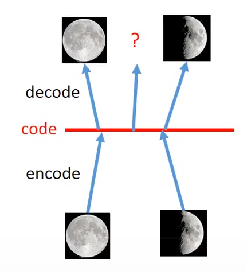
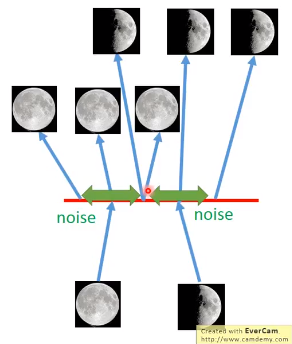
VAE的话,
code上加了些噪声,那么就从一个点变成了一个范围,绿色双箭头的范围内,都会被decoder成满月,半月同理。
此时选中间某个点的话,他被希望重建回满月,也希望是半月,但只能重建回一张图片,VEA会最小化均方误差,所以会得到一张介于满月和半月的图。
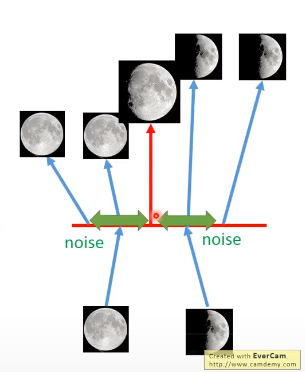
2.比较正式的解释
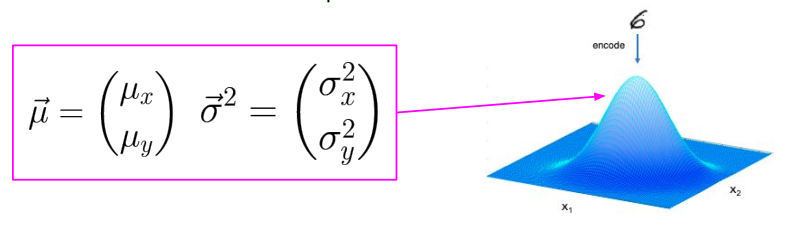
VAE中是个多元正态分布
Defined by 2 variables:
○ 𝜇 - mean value -> centre of the distribution
○ σ - standard deviation -> variability of the distribution
如下原理。
VAE
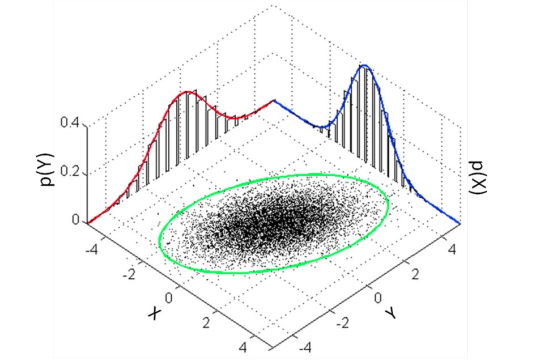
假设现在想让机器生成pokeman宝可梦的图, 每张图20*20,就是高维空间400维的一个点(一)。现在要做的是:估计高维空间上这个点的概率分布P(x),x是一个向量。得到P(x),就可以从这个分布中采样到一张宝可梦的图啦。
下图,曲线高的地方代表像宝可梦的概率大。

如何估计这个概率分布?
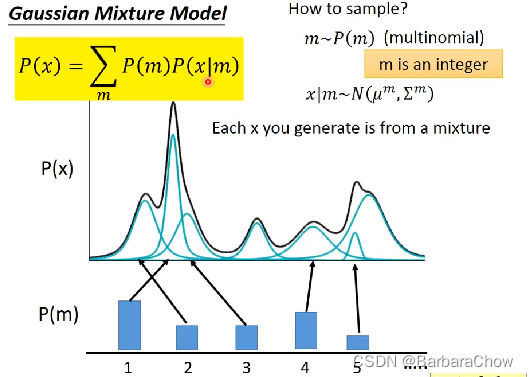
(1)可以用高斯混合模型
如有100个高斯模型,给你一些数据,让你去估计这100个高斯的权重,均值,方差,很容易。
每个高斯都得到自己的权重,首先根据权重选择你要哪个高斯模型P(m),然后从这个高斯模型里就能采样一个x出来P(x|m),就能用EM算法求解。
每个x都是来自于某一个混合分布,看起来像分类,但不能看作分类或聚类问题,更好的表示方式是用分布表示,即不是把x分成固定的一类,而是用一个向量来表示它,来体现它各个不同面的特性。
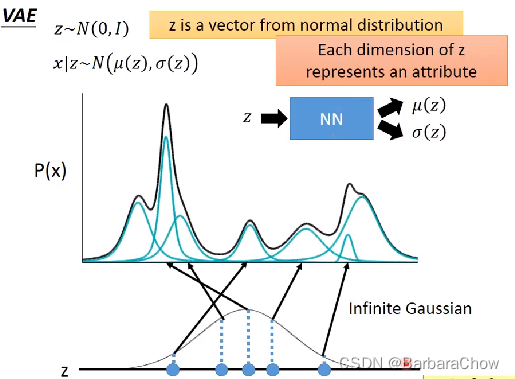
(2)可以用VAE
VAE就是高斯混合模组中混合分布的版本。
从正态分布中采样一个z,z~N(0,1),z可以是很多维(自己决定),那么每一维都代表一种特性。假设均值方差都有它的公式,把z带入,就能得到均值μ(z),方差σ(z)的公式。之前都是定128,512…个混合高斯,现在定无穷个高斯。
下图假设一个一维的z,从隐空间得到,从z空间任意sample一个点,每个点都会有其对应的高斯,那么怎么知道这个高斯分布什么样(均值&方差)?用神经网络,输入z,输出两个向量,均值μ(z),方差σ(z),(方差是矩阵怎么办?你可以拉平,或只训对角线元素)
最后,对所有z的值积分(因为z连续):
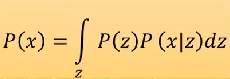
-
有人问:为什么z是高斯分布呢?
也可以不是高斯分布,可以是一朵花的样子,可以是任何样子。但假设高斯也是合理的。 -
会不会假设的z的分布太复杂,神经网络算不出P(x)?
不会的,神经网络有能力拟合任何函数,就算假设z服从标准正太分布,最后算出来的P(x)也是很复杂的。
P(x)如何求
最大似然估计:

均值μ(z),方差σ(z)的估计:
我们首先知道P(z)是什么分布,如z~N(0,1),标准正态分布。现在z服从(均值μ(z),方差σ(z))的分布,然后就可以知道x是从什么样的分布中出来的,但均值μ(z),方差σ(z)的函数是不知道的,怎么算?
用神经网络NN计算,调NN的参数,使得似然函数最大。
还需另一个参数P(z|x),同理,调NN’的参数,使得似然函数最大。
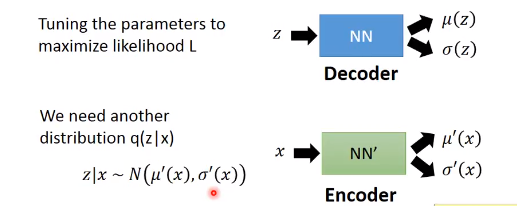
下面展开似然函数logP(x):
可以看到红线式子就是KL散度,用来度量两个分布的相似性(越相似值越小)。

这样就的到最低边界Lb,式子可以写成如下:
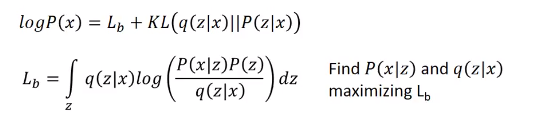
我们想最大化这个最低边界Lb,但同时会影响后一项KL散度的值,如出现下面情况:
Lb的值增大的同时,KL减小(减小使得q(z|x)与p(z|x)越来越接近),最后似然值并未变。
为什么呢?
这个式子中,P(z)是已知的(正态分布),所以要找P(x|z)和q(z|x),让Lb最大。
首先q(z|x)这项压根和P(x)没关(P(x)只和P(x|z)有关),所以改变q(z|x),对最终的目标似然函数log P(x)没影响,即蓝线高度不变。所以Lb增大,会让KL散度那项减小。
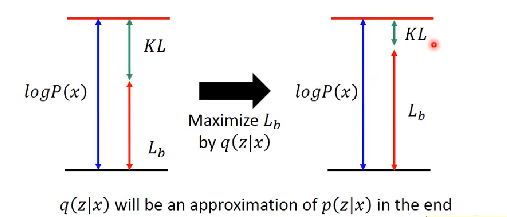
那我们把Lb式子继续分解:
公式第一项:
可以看到第一项是有关q(z|x)的散度,q就是一个神经网络NN’,当你输入一个x,就会得到均值,方差,就知道它是从什么样的分布得来的。

我们目的是最大化Lb,那此时就想最小化该散度(因为是负的):
那就通过调该NN’的参数,让q(z|x)的分布与P(z),(已知是正太分布)越接近越好,从而来使得该KL最小。

最小化该散度,就等同于下面的式子,就是VAE网络的目标函数。
具体公式推导可以看VAE这篇论文。
公式第二项:
让它最大,就是最大化log P(x|z)。从q(z|x)中sample一个z,这个能让log P(x|z)的概率越大越好。这件事本质也是自编码器做的事情。 此时,可以发现,原来q(z|x)中q就是编码器NN’ , P(x|z)中P就是解码器NN。
怎么才能让log P(x|z)的概率越大?
在实做中,一般不考虑方差方差σ(z),只考虑均值μ(z)的话,如果是假设是高斯分布,就希望均值μ(z)与x越接近越好,若μ(z)=x时,log P(x|z)最大。
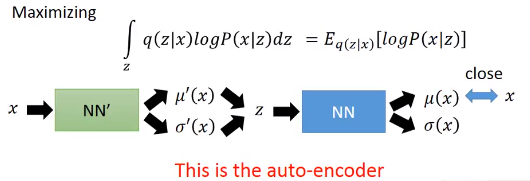
VAE还有另外的形式,如Conditional VAE
Conditional VAE
如想让它产生同一书写风格的手写体数字。
如下图,给一个粗体的4,它可以抽出它的特性(笔画数,粗细等等),然后输入decoder有关它特性的向量,以及告诉是数字几,产生同种书写风格的其他数字。

VAE存在的问题
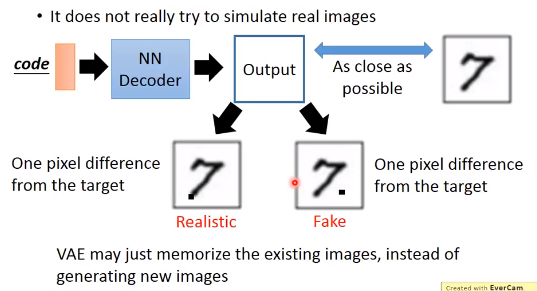
VAE它没有去学怎么产生一张新的像真的的图片,而是学习怎么产生一张图片能与database里的图片一模一样。他只是模仿而已,这样来看其实没有太intelligient。
如图,decoder产生的两张数字7,第一个在7的下端多了一点像素,第二个在7的右边多了一点像素,在我们看来第一个(也能完全接受)比第二个好,但在机器看来都是一样好或一样坏(比较与目标图片的每个像素的最小均方误差损失等等)。
所以接下来2014年有人提出生成对抗网络。















 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









