










小样本学习&元学习经典论文整理||持续更新
核心思想
本文是利用元学习实现小样本模仿学习系列文章的第二篇,相对于上一篇文章,本文实现了视觉模仿学习,通过输入示教动作的视频或图像序列就能实现模仿学习,引入了MAML元学习算法,并且在此基础上进行了改进,使其能够实现在元测试时只提供示教的图像而没有对应的action的情况下,学会完成一项新的任务。
MAML算法简单讲就是把元训练过程分为内训练和外训练。首先采样得到一系列任务样本Task,对于每个任务
T
i
T_i
Ti至少包含两个示教图像序列,一个用于内训练的
π
i
\pi_i
πi,一个用于外训练的
π
i
′
\pi'_i
πi′。网络的参数为
θ
\theta
θ,内训练过程就是用每个任务的
π
i
\pi_i
πi对网络进行训练,分别得到每个任务对应的
θ
i
′
=
θ
−
α
▽
θ
L
T
i
(
f
θ
)
\theta'_i=\theta-\alpha\triangledown _{\theta }L_{T_i}(f_{\theta })
θi′=θ−α▽θLTi(fθ)。当所有的任务内训练过程完成后,再利用
π
i
′
\pi'_i
πi′进行外训练,得到网络最终的权重
θ
=
θ
−
β
▽
θ
∑
T
i
∼
p
(
T
)
L
T
i
f
(
θ
i
′
)
\theta=\theta-\beta\triangledown _{\theta }\sum_{T_i \sim p(T)}L_{T_i}f(\theta'_i)
θ=θ−β▽θ∑Ti∼p(T)LTif(θi′),注意此处是对所用任务的外训练损失之和进行梯度下降,前向过程使用的参数是每个任务对应的
θ
i
′
\theta'_i
θi′。对于连续动作其损失函数计算方法如下:
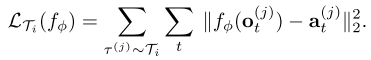
外训练的优化目标为
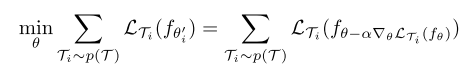
本文在此基础上做了三点改进:“双头”结构(Two-Head Architecture),学会无专家动作条件下的模仿学习(Learning to Imitate without Expert Actions),偏置变形(Bias Transformation)。下面依次介绍三个改进方案。
- “双头”结构(Two-Head Architecture)
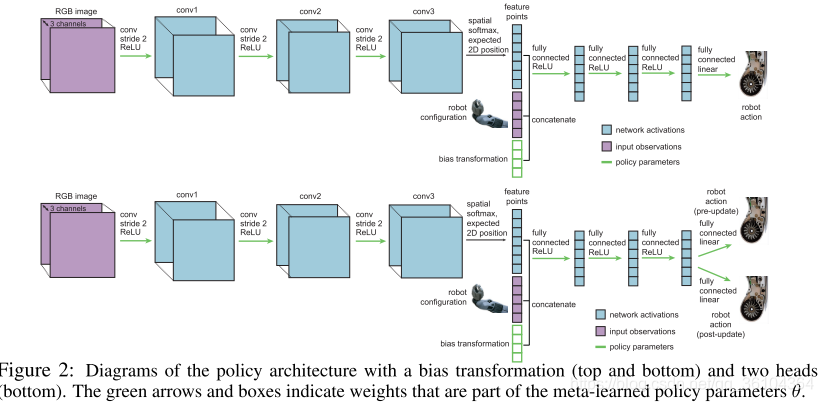
原本MAML的网络结构如图中上半部分所示,整个网络只有一个输出,无论是内训练还是外训练过程都是利用这一个输出对网络进行参数更新的。而双头结构(图中下半部分所示)则是保持网络大部分结构是共用的,但是最后一个全连接层分成两个,这样可以得到两个输出,一个用于pre-update head(内训练),一个用于post-update head(外训练)。令
y
t
(
j
)
y_t^{(j)}
yt(j)表示前一个隐藏层的输出,
W
W
W和
b
b
b表示最后一个全连接层的权重和偏置,则内训练的损失函数可以表示为:
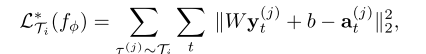
而外训练的优化目标变成了
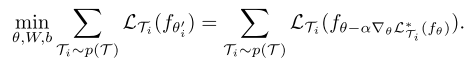
对于每个任务而言,其对应的
W
W
W和
b
b
b都成为一个用于优化的参数,类似于为每个任务都学习一种损失函数,这使得各个任务的内训练的目标可以不一致,因为外训练时不会使用pre-update head输出的结果。
- 学会无专家动作条件下的模仿学习(Learning to Imitate without Expert Actions)
一个示教动作序列(Demonstration)包含两个部分:观察(Observation)和动作(Action)。观察顾名思义就是另一个机器人或者人类完成任务的图像序列,动作则是指每个图像对应的机器人的运动指令,通常情况下图像序列是很容易采集的,但对应的动作指令就很难获得,因此本文提出该方法缓解了这一难题。需要声明的是这里的无专家动作是指在内训练和测试环节可以没有专家动作,在外训练中还是需要对应的专家动作引导网络训练的。这一改进得益于上面提到的双头结构,令内训练的损失函数改为
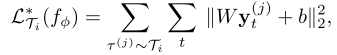
外训练的优化目标不变,为了使外训练的损失函数下降,在每个内训练过程中就强行优化 W W W和 b b b使其组成的损失函数更好的引导网络参数的更新。经过多次反复迭代训练后,网络逐渐具备了仅利用观察进行参数更新的能力,在测试时,仅需要输入一个不带有专家动作的新任务的视频序列,网络就能够进行参数微调,从而学会新的任务。 - 偏置变形(Bias Transformation)
对于标准的神经网络结构 y = W x + b y=Wx+b y=Wx+b,损失函数对偏置的梯度 ∂ L ∂ d = ∂ L ∂ y ∂ y ∂ d = ∂ L ∂ y \frac{\partial L}{\partial d}=\frac{\partial L}{\partial y}\frac{\partial y}{\partial d}=\frac{\partial L}{\partial y} ∂d∂L=∂y∂L∂d∂y=∂y∂L,因此偏置的更新是与权重更新耦合在一起的,而作者希望消除这一耦合关系(原文表达是eliminating this decoupling,消除解耦?不知道是不是笔误写错了),引入了参数向量 z z z,使得 y = W 1 x + W 2 z + b y=W_1x+W_2z+b y=W1x+W2z+b,偏置变形为 d ~ = W 2 z + b \tilde{d}=W_2z+b d~=W2z+b,偏置的梯度下降过程为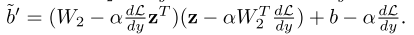
其数值更大程度上是由 W 2 W_2 W2和 z z z控制的,而这两个参数的更新又不会影响网络中其他权重的更新,因此减轻了偏置和权重之间的耦合关系。作者称这一改变使得偏置变形增强了梯度的表示能力,而没有影响整个网络自身的表示能力,有助于提高元学习的效率和稳定性。
实现过程
网络结构
示教动作图像序列经过首先经过3个步长为2的卷积层,然后利用空间soft-argmax函数转换成空间特征点,并且与机器人的配置信息和引入的偏置变形级联起来,在经过三个全卷积层后进入双头结构,分别得到两个输出。
损失函数
对于连续任务通常为均方差损失如上文所述,对于离散任务通常为交叉熵损失函数。
创新点
- 利元学习算法实现了视觉模仿学习任务的一眼学习
- 改进了MAML算法,设计了双头结构实现了在无专家动作条件下的模仿学习,进一步降低了模仿学习的学习成本,仅需要录制一段机器人动作视频,就可以完成对应的任务学习
- 引入了偏置变形,提高了网络的学习过程的效率和稳定性
算法评价
相对于前一篇文章,本文提出的模型有进一步接近了模仿学习的理想状态,不仅可以实现一眼学习,而且摆脱了对于物体空间位置和机器人状态信息的依赖,可以直接通过视觉进行学习,甚至可以不需要示教中的专家动作,就能完成新任务的学习工作,这使得模仿学习的学习成本大大下降了。该系列的最后一篇文章则是将这一学习过程进一步拓展到人类动作视频的学习中去,仅需要观察人类完成一个任务,就能学会并完成相似的任务。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











