










小样本学习&元学习经典论文整理||持续更新
基本思想
模仿学习,顾名思义就是机器人通过模仿示教动作(Demonstration)从而学会完成某项任务的过程,这里包含几个重要的概念:状态(State,
S
t
S_t
St),动作(Action,
A
t
A_t
At),示教动作(Demo)和策略(表现为神经网络的参数
θ
\theta
θ),模仿学习就要利用神经网络实现根据当前的状态,示教动作和学习策略得到要执行的动作,
A
t
=
f
(
S
t
,
D
e
m
o
,
θ
)
A_t=f(S_t,Demo,\theta)
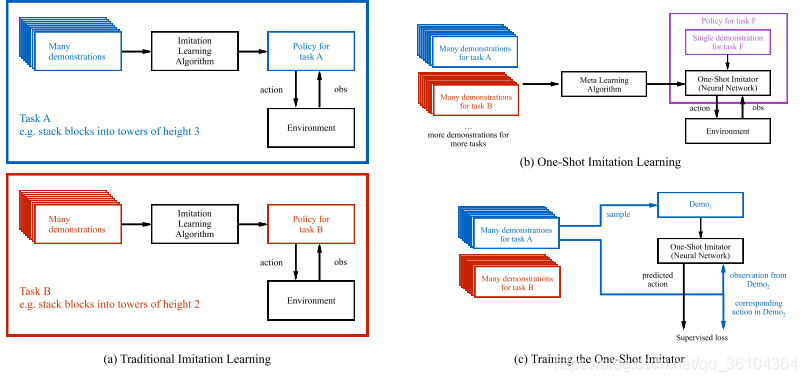
At=f(St,Demo,θ)。通常机器人需要观察大量的示教动作,进行长时间的反复训练才能掌握某项动作,例如把箱子摞起来。但本文希望让机器人只观察一遍示教动作就能完成相应的任务。为实现该目标,作者采用了一种带有柔性注意力机制(Soft-attention)的元学习模型。作者将目光聚焦在摞箱子这一类任务中,并准备了大量的示教动作数据集。在训练时同时输入一个示教动作和从另一个示教动作采样得到的状态信息(State),输出的是与状态对应的预测动作。而在测试时,只需要观察一次新任务的完整示教动作,该模型就能在这个新任务的其他实例中取得较好的表现。通俗点讲,就是教机器人学会如何从示教动作中学习知识并完成指定任务,也就是一个元学习的过程。
本文设计的模型的结构多次用到了柔性注意力机制(Soft-attention),为方便大家理解后文,这里简要的介绍一下。因为本文设计的算法要处理包含不同数量箱子的任务,因此输入向量的维度也是在变化的(与箱子的数量成线性关系),而输出的维度是固定的。Soft-attention正适用于处理输入维度可变,而输出维度固定的问题。
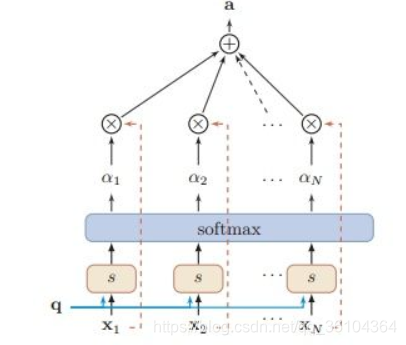
Soft-attention原理如上图所示,输入是一个查询向量(Query Vector,
(
q
)
\text(q)
(q))和一个输入向量(
(
X
)
=
[
x
1
,
x
2
.
.
.
.
x
N
]
\text(X)=[x_1,x_2....x_N]
(X)=[x1,x2....xN]),利用s函数计算输入向量和查询向量之间得分
s
(
q
,
x
i
)
=
v
T
t
a
n
h
(
W
x
i
+
U
q
)
s(q,x_i)=v^Ttanh(Wx_i+Uq)
s(q,xi)=vTtanh(Wxi+Uq),再利用softmax转化成注意力分布
α
i
\alpha_i
αi,其表示在查询
(
q
)
\text(q)
(q)时,第i个输入
x
i
x_i
xi的重要性,最后通过加权求和的形式得到输出
a
=
∑
i
=
1
N
α
i
x
i
a=\sum_{i=1}^N\alpha_ix_i
a=∑i=1Nαixi。
实现过程
网络结构
本文的主要贡献在于其网络结构的设计过程,整个算法模型分为三个部分:示教网络(Demonstration Network),上下文网络(Context Network)和执行网络(Manipulation Network)
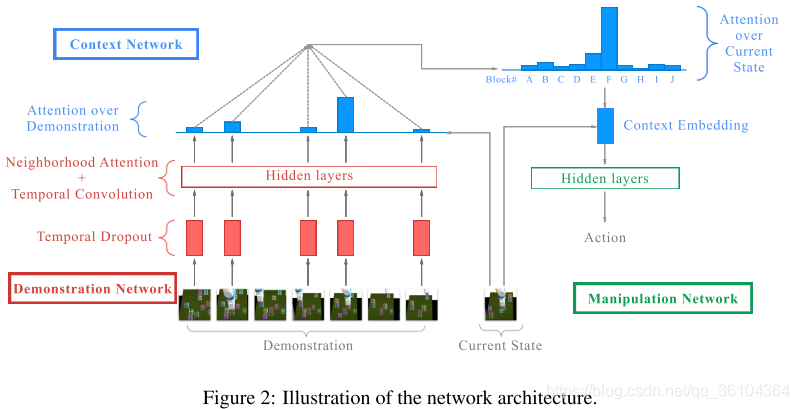
- 示教网络
因为观察成百上千帧的示教动作序列计算成本实在是太高了,因此作者首先采用了一种称为“时间剪枝(Temporal Dropout)”的下采样操作,将示教动作序列的长度缩减为原来的1/20。然后将示教动作分成两个部分:箱子的状态(即所有箱子的三维坐标,block_state),机器人的状态(机器人的开或关,robot_state)。箱子状态经过一个通道数为64的1 * 1卷积(此处的卷积是在时间维度上的一维卷积)后得到隐藏向量 h h h,经过ReLU激活层得到 h i n h^{in} hin。将 h i n h^{in} hin输入到一个叫做相邻注意力(Neighborhood Attention)的模块中,这个模块就是一个柔性注意力机制的变形,用两个相互独立的线性层分别计算查询向量 q i = L i n e a r ( h i i n ) q_i=Linear(h^{in}_i) qi=Linear(hiin)(对应上文中的 U q Uq Uq)和上下文向量 c i = L i n e a r ( h i i n ) c_i=Linear(h^{in}_i) ci=Linear(hiin)(对应上文中的 W x i Wx_i Wxi),此处查询向量的长度与输入向量 h i n h^{in} hin是相同的,都等于箱子的数量。然后对查询向量中的每一项 q i q_i qi分别计算得分 w j = v T t a n h ( q i + c j ) w_j=v^Ttanh(q_i+c_j) wj=vTtanh(qi+cj),再利用softmax函数转换成注意力权重,最后对输入 h i n h^{in} hin经过加权求和得到结果 r e s u l t i result_i resulti,这一结果暗含着每个箱子和其他箱子之间的关系信息。将输入向量 h i n h^{in} hin,结果 r e s u l t result result、箱子状态block_state和机器人状态robot_state级联起来,输入到一个通道为64的2 * 2卷积(一维时间卷积)中得到示教网络的最终输出。示教网络中还采用了空洞卷积和残差连接的结构因为与主体结构关系不大,因此不再详细介绍。 - 上下文网络
上下文网络是该模型的重点,他的输入包含当前的状态(用于预测动作的状态)和经过示教网络编码的嵌入式隐藏变量,输出是一个上下文嵌入式信息,其维度既不依赖于示教动作序列的长度,又不依赖于箱子的数量,因此他被强制性地学习执行网络(Manipulation Network)所需要的相关信息。针对两个输入,上下文网络中包含两个注意力机制——示教注意力( Attention over demonstration)和当前状态注意力(Attention over current state)。示教注意力部分为经过示教网络编码的嵌入式隐藏变量计算权重,当前状态注意力部分为当前状态中的每个箱子状态计算权重,整个过程利用LSTM网络反复执行多次。最终输出一个固定长度的向量,应用于执行网络。 - 执行网络
执行网络相对比较简单,采用一个多层感知机MLP,用于输出动作。
损失函数
对于连续动作序列采用L2损失函数,对于离散动作序列采用交叉熵损失函数。
创新点
- 采用元学习的方式解决模仿学习中的小样本学习任务
- 设计了一种新型的包含soft-attention机制的网络结构,根据示教动作和当前状态可以输出动作
算法评价
在机器人模仿学习领域,一眼学习(One-shot)可能是众多研究者的最终目标,即希望机器人看一遍示教动作,就能够学会该任务,并且能够泛化到相类似的任务中。本文给出了一种非常有潜力的解决方案——元学习。这一学习如何学习的思想非常切合模仿学习的模式,因此得到了众多机构的重视,也是模仿学习中重要的发展方向。本文是Pieter Abbeel组在小样本模仿学习系列文章的第一篇,其解决的问题相对比较简单,首先任务非常固定——摞箱子,其次示教动作是通过给定箱子的三维坐标和机器人的开关状态来输入的,而不是通过视觉学习机器人的动作。因此在接下来的研究中,该组又陆续推出利用视觉实现一眼模仿学习,并且可以实现人类动作的一眼模仿学习。接下来我会继续学习相关的论文。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。















 1730
1730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











