









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种采用元学习解决小样本学习任务的方法MetaNet,学习一种跨任务的元级别知识,并实现对泛化任务的快速参数化。MetaNet由两部分组成:基学习器(Base Learner)和带有额外记忆模块的元学习器(Meta Learner)。学习也在连个分离的空间内进行,基学习器在输入任务空间,而元学习在与任务无关的元空间,基学习器向元学习提供一种由高阶的元信息构成的反馈,用于解释他在当前任务空间内的状况。此外,MetaNet的权重还涉及不同的时间尺度:快速权重(Fast Weight)和慢速权重(Slow Weight),在训练过程中,快速权重是利用另一个网络根据梯度信息生成的,而慢速权重则需要利用SGD方法进行更新得到。

整个网络训练过程包含三个阶段:获取元信息、快速权重的生成和慢速权重的优化。用于训练的数据集同样包含两个部分:支持集
{
x
i
′
,
y
i
′
}
i
=
1
N
\left \{x'_i,y'_i\right \}^N_{i=1}
{xi′,yi′}i=1N和训练集(查询集)
{
x
i
,
y
i
}
i
=
1
L
\left \{x_i,y_i\right \}^L_{i=1}
{xi,yi}i=1L。正如上文提到的整个算法包含两个层级的学习:基学习器和元学习器,因此权重也分成:样例级别的权重(Example-level Weight)和任务级别的权重(Task-level Weight)。而元学习器是由动态表征学习函数
u
u
u和两个快速权重生成函数
m
m
m和
d
d
d构成。具体的学习过程如下:
- 从支持集中采样得到T个样例,利用动态表征学习函数
u
u
u(其权重参数为任务级别的慢速权重
Q
Q
Q)对这T个样例进行预测,并计算得到表征损失和梯度(元信息)
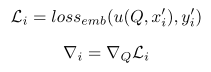
- 利用快速权重生成函数
d
d
d(其权重参数为G),根据上面得到的梯度(元信息)生成任务级别的快速权重
Q
∗
Q^*
Q∗。
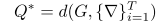
- 利用基学习器
b
b
b(其权重参数为样例级别的慢速权重
W
W
W)对支持集中的全部
N
N
N个样例进行预测,并计算得到任务损失和梯度(元信息)
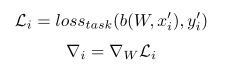
- 利用快速权重生成函数
m
m
m(其权重参数为Z),根据上面得到的梯度(元信息)生成样例级别的快速权重
W
∗
W^*
W∗。
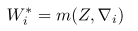
- 然后我们将每个样例对应的快速权重值
W
i
∗
W^*_i
Wi∗储存到外部储存器
M
M
M中,并利用表征学习函数
u
u
u计算得到对应的表征
r
i
∗
r^*_i
ri∗,并将其储存到外部索引储存器
R
R
R中。
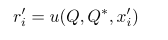
- 利用表征学习函数
u
u
u计算得到训练集中的
L
L
L个样例对应的表征
r
i
r_i
ri
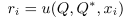
- 计算表征
r
i
r_i
ri与外部索引储存器
R
R
R中储存的表征
r
i
∗
r^*_i
ri∗之间的余弦距离,并利用sofmax函数将其转化为权重,将外部储存器
M
M
M中储存的值进行加权求和,得到当前样例的快速权重值(该过程就是一种注意力机制)
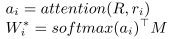
- 利用基学习器
b
b
b对训练集中的样例进行预测,并得到任务损失,将所有的任务损失
l
o
s
s
t
a
s
k
loss_{task}
losstask累加起来得到训练损失
l
o
s
s
t
r
a
i
n
loss_{train}
losstrain,并通过梯度下降方式更新网络中的参数
θ
=
{
W
,
Q
,
Z
,
G
}
\theta=\left \{W, Q, Z, G \right \}
θ={W,Q,Z,G}

整个学习过程还是比较复杂的,涉及到四种学习器( u , b , m , d u, b, m, d u,b,m,d)和对应的四套权重参数( Q , W , Z , G Q,W, Z, G Q,W,Z,G),其中 Q Q Q和 W W W还分为快速权重 Q ∗ , W ∗ Q^*, W^* Q∗,W∗和慢速权重 Q , W Q, W Q,W两种类别。为方便大家理解,作出以下几点说明。
-
四个学习器分别是做什么用的?
四种学习器中 u u u和 b b b采用普通的卷积神经网络结构, m m m和 d d d采用LSTM结构, m m m和 d d d是利用梯度信息(也就是文中所谓的元信息)得到对应的快速权重 W ∗ W^* W∗和 Q ∗ Q^* Q∗, u u u是利用任务级别权重 Q Q Q和 Q ∗ Q^* Q∗获得样例 x i x_i xi对应的表征信息 r i r_i ri, b b b是利用样例级别的权重 W W W和 W ∗ W^* W∗获得样例 x i x_i xi对应的类别信息。 -
为什么需要计算表征信息 r i r_i ri还要把样例级别的快速权重值 W ∗ W^* W∗保存起来呢?
我们把支持集中每个类别图像对应的权重值 W ∗ W^* W∗保存起来,并计算得到一个表征信息 r i ′ r'_i ri′,这样在我们对训练集中的样本进行预测时,就可以将新样本的表征信息 r i r_i ri与 R R R中储存的表征信息一一比对,利用余弦函数得到相似性程度 α i \alpha_i αi,并利用softmax函数将其转化成对应的权重,以加权求和的形式提取到快速权重值 W ∗ W^* W∗,并利用其对新样本进行预测。因为支持集中样本类别包含训练集中的样本类别,因此利用保存下来的快速权重值 W ∗ W^* W∗对网络进行快速参数化,能够更容易地获取正确分类结果。 -
u u u和 b b b是怎样同时利用快速权重和慢速权重的呢?
作者提出一种层增强(Layer Augmentation)技术,具体实现方法如图所示
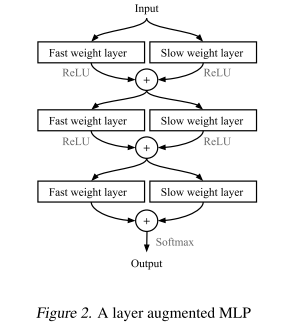
输入的信息分别进入快速权重层和慢速权重层,两者的结构完全相同,只是权重不同。慢速权重是由梯度下降法慢慢更新得到的,而快速权重则是由上文介绍的加权求和的形式直接计算得到的。将两个层的输出经过ReLU激活层后,逐元素相加得到对应的输出。本身两个层的输出在不同是数值域上,经过ReLU函数后统一在 [ 0 , + ∞ ] \left [ 0,+\infty \right ] [0,+∞]范围内。 -
测试过程是如何实现的?
测试集同样要分成支持集和查询集两个部分,支持集中要包含查询集中所有样本类别,但每个类别可以只包含少量的样本,甚至一个样本。在测试时,同样需要在支持集上计算得到每种类别的快速权重值 W i ∗ W^*_i Wi∗和对应的表征信息 r i ′ r'_i ri′,并保存起来。处理查询集上的样本时,过程与训练过程相同:先计算对应的表征信息 r i r_i ri,计算与各个 r i ′ r'_i ri′的相似性,转换为权重并提取得到快速权重 W i ∗ W^*_i Wi∗,基学习器 b b b利用快速权重 W i ∗ W^*_i Wi∗和慢速权重 W i W_i Wi计算得到预测结果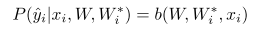
这里的输入 x i x_i xi也可以替换成表征信息 r i r_i ri.
实现过程
网络结构
基学习器 b b b采用普通的卷积神经网络结构,包含5个卷积层,卷积核尺寸为3 * 3,通道数为64,每层后面都跟随ReLU层和2 * 2的最大池化层,最后是一个全卷积层和softmax层得到预测结果,表征信息学习器 u u u的结构与 b b b基本相同,只是取消了最后的softmax层,全连接层输出的特征向量就是表征信息。这两个CNN网络的最后三层采用了上文介绍的层增强技术。快速权重学习器 m m m和 d d d采用一个单层的LSTM结构,包含20个隐藏单元和一个3层的MLP和ReLU激活层,输入的序列顺序不影响结果。
损失函数
对表征学习损失函数而言,如果每个类别仅包含一个样例,可采用交叉熵损失函数,如果每个类别包含多个样例,可采用contrastive损失,计算过程如下
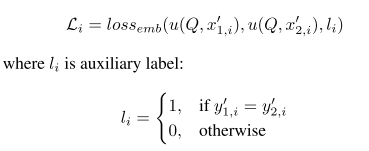
对任务学习损失函数,其选择是广泛的,可根据任务需要选择。对于本文的图像分类任务而言,选择了交叉熵损失函数。
训练策略
如上文所述。
算法推广
一方面作者通过实验发现,本文提出的算法能够实现连续学习,在Omniglot数据集上训练得到的网络,可以进一步在MNIST数据集上继续训练,在学习MNIST数据集的同时,并不会产生严重的“遗忘灾难”(即忘记Omniglot数据集上的信息)。另一方面作者指出该算法可以应用于强化学习,模仿学习,或者基于RNN用于序列模型和自然语言理解等任务。
创新点
- 提出一种新型的元学习算法用于解决小样本学习任务,利用外部记忆模块储存每个类别对应的权重信息和表征信息,然后利用该信息进行预测。
- 提出一种层增强技术,同时利用快速权重和慢速权重得到预测结果
算法评价
利用外部储存模块的元学习方法已经从保存类别的特征信息升级为直接保存权重信息了,由实验结果来看,其在多个任务中都取得了不错的表现。本文引入的快速权重、慢速权重和层增强技术都是一些新的思路和概念,值得进一步学习。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。
















 5985
5985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











