









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种采用图神经网络(Graph Neural Network,GNN)的小样本学习算法,将距离度量由欧式空间转移到非欧空间中,其核心思想还是将有标签支持样例的标签信息传递到无标签的查询样例上去,这种信息的传递可以看做一个图模型根据输入的图像和标签给出的后验推断。那么具体是如何实现的呢?首先,作者将输入数据集划分为三部分
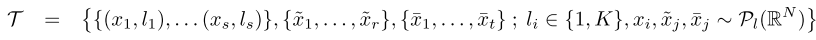
其中
(
x
1
.
.
.
x
s
)
(x_1...x_s)
(x1...xs)表示带有标签的支持集,
(
x
~
1
.
.
.
x
~
r
)
(\tilde{x}_1...\tilde{x}_r)
(x~1...x~r)表示不带有标签的训练集(用于半监督学习和主动学习),
(
x
ˉ
1
.
.
.
x
ˉ
t
)
(\bar{x}_1...\bar{x}_t)
(xˉ1...xˉt)表示不带标签的查询集,三个数据集是独立同分布的。网络的处理过程如下图所示

将支持集图片
x
1
.
.
.
x
4
x_1...x_4
x1...x4和查询集图片
x
ˉ
\bar{x}
xˉ输入到嵌入式网络
ϕ
(
x
)
\phi(x)
ϕ(x)中转化为对应的特征向量,将特征向量与表示标签的独热向量
h
(
l
)
h(l)
h(l)级联起来,共同输入到GNN中,最后得到预测结果。前半部分都很好理解,而且也是非常常见的操作。下面详细介绍一下GNN部分的工作过程。
GNN是由许多节点和边构成的图模型,在本文中,每一个节点都代表一幅输入的图像,而每个边上的权重就表示两幅图之间的关系(可以理解为距离或者相似程度)。本文采用的是稠密连接的图,因此每两个输入图片之间都有边连接起来,邻接矩阵
B
B
B就储存了任意两个节点之间的权重值。那么这个权重值是怎样计算的呢?这里有许多的计算方式,也衍生出许多GNN的变种,本文受信息传递算法的启发,采用学习的方式获取两个节点之间的权重值,计算方法如下
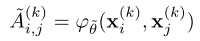
其中
φ
θ
~
(
)
\varphi_{\tilde{\theta}}()
φθ~()是一个MLP,输入两个节点之间的绝对值差,输出对应的权重值
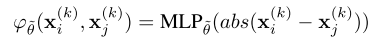
将计算得到的
A
~
i
,
j
(
k
)
\tilde{A}^{(k)}_{i,j}
A~i,j(k)的每一行都进行softmax处理,保证每个节点与其他所有节点之间的权重之和为1,然后得到邻接矩阵
B
B
B。之后就可以利用图卷积神经网络(GCN)计算得到下一层网络,计算过程如下
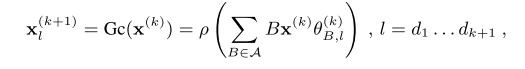
其中
x
l
(
k
+
1
)
x_l^{(k+1)}
xl(k+1)表示第
k
+
1
k+1
k+1层网络的节点,
l
l
l表示节点上特征向量的长度,
ρ
\rho
ρ表示非线性激活层,本文选择Leaky ReLU,
θ
\theta
θ是一个可以学习的参数,累加符号表示邻接矩阵
B
B
B可以采用多种计算方式,并累加起来,但本文中只有两种情况:节点与自己本身的连接权重为1,与其他节点的连接权重为
A
~
i
,
j
(
k
)
\tilde{A}^{(k)}_{i,j}
A~i,j(k)。每一个图卷积模块的计算过如下图所示,在训练过程中还需要将每层网络的输入
V
(
k
)
V^{(k)}
V(k)和Gc block的输出级联起来构成下级网络输入
V
(
k
+
1
)
V^{(k+1)}
V(k+1),测试时不需要这步操作。

整个GNN就是由多个上述的图卷积模块构成的,如下图所示

可以看到图卷积层并不会改变图模型的结构,只改变节点上向量的值(由不同颜色表示),而邻接矩阵的计算,就会更新两个节点之间的连接权重,因此图模型的结构也发生了变换。图中由左向右第三个方框中的
A
~
i
,
j
(
k
)
\tilde{A}^{(k)}_{i,j}
A~i,j(k)改为
A
~
i
,
j
(
k
+
1
)
\tilde{A}^{(k+1)}_{i,j}
A~i,j(k+1)才更合适,表示网络的不同层。
实现过程
网络结构
文中涉及到多个网络,首先是用于特征提取的嵌入式网络 ϕ ( ) \phi() ϕ(),与原型网络、Matching Network中结构相似,不再详述;然后是用于度量矩阵中权重计算的 φ θ ~ ( ) \varphi_{\tilde{\theta}}() φθ~()是由五个全连接层构成的,前四个带有BN和Leaky ReLU层;最后是用于 θ \theta θ学习的网络,代码中显示是由一个全连接层构成的。
损失函数
采用交叉熵损失函数
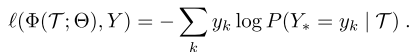
算法推广
本文的算法还可以应用于半监督学习和主动学习的方式。半监督学习比较简单,只需要将表示分类的独热向量
h
(
l
)
h(l)
h(l)改为
K
K
K个单纯型的均匀分布,假设有
K
K
K个类别,每个类别对应的值都为
1
/
K
1/K
1/K。主动学习则需要让网络自己决定是否需要标签信息,实现方法是在GNN的第一个层之后,对所有无标签样例对应的节点增加一个Softmax注意力层
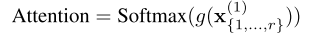
为了保证每次只询问一张图片,因此令
A
t
t
e
n
t
i
o
n
Attention
Attention中只有一个值为1,其余值均为0,测试时是选择最大值置为1,训练时则是基于多项式概率随机选择一个值置为1,得到
A
t
t
e
n
t
i
o
n
′
Attention'
Attention′。然后令
A
t
t
e
n
t
i
o
n
′
Attention'
Attention′与标签向量相乘,就得到了对应的独热向量

创新点
- 提出一种采用图神经网络解决小样本学习的算法,利用图模型计算图像之间的关系
- 受信息传递算法的启发,采用多层感知机计算节点之间的权重,用于构建邻接矩阵
- 将算法推广至半监督学习和主动学习领域
算法评价
本文实际上是将原型网络,Matching Network等一系列采用度量学习思路的网络推广到了非欧空间,相关性的度量方式不再局限于余弦距离,欧式距离等计算方式,而是利用图神经网络来描述这一关系。作者还探究了本文的算法与Siamese Network,Prototypical Network,Matching Network之间的关系,他们都可以看做本文算法在欧式空间中的一个变种。由实验结果来看,本文的算法在多个数据集中都优于Siamese Network,Prototypical Network,Matching Network算法,与TCML相比,也有一定的竞争力,但相比于TCML采用深层网络结构(包含11M的参数量)而言,本文提出的算法仅有400K参数。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。
















 1313
1313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











