







目录
4.tokenizer的细节,tokenizer的计算方式,各种tokenizer的优缺点
1.在指令微调中,如何设置、选择和优化不同的超参数,以及其对模型效果的影响?
2.在指令微调中,如何选择最佳的指令策略,以及其对模型效果的影响?
5.RLHF完整训练过程是什么?RL过程中涉及到几个模型?显存占用关系和SFT有什么区别?
知识杂谈
1.transformer 八股文
a.Self-Attention的表达式
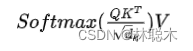
b.为什么上面那个公式要对QK进行scaling
scaling后进行softmax操作可以使得输入的数据的分布变得更好,你可以想象下softmax的公式,数值会进入敏感区间,防止梯度消失,让模型能够更容易训练。
c.self-attention一定要这样表达吗?
不一定,只要可以建模相关性就可以。当然,最好是能够高速计算(矩阵乘法),并且表达能力强(query可以主动去关注到其他的key并在value上进行强化&

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











