




论文题目:Improving Factuality and Reasoning in Language Models through Multiagent Debate
来源:ICML 2024
话题:大语言模型;多智能体
作者:
![]()
论文链接:https://openreview.net/forum?id=zj7YuTE4t8
一、摘要
近年来,大型语言模型(LLMs)在语言生成、理解和少样本学习方面展现出了卓越的能力。大量研究探索了如何通过提示(prompting)工具进一步提升其性能,例如验证(verification)、自一致性(self-consistency)或中间草稿(intermediate scratchpads)。本文提出了一种互补的方法,通过多个语言模型实例进行多轮辩论,各自提出并辩论其回答和推理过程,最终达成一致的最终答案。研究结果表明,该方法在多个任务上显著提升了数学和策略推理能力。我们还发现,该方法提高了生成内容的事实准确性,减少了当代模型容易产生的错误答案和幻觉现象。我们的方法可直接应用于现有的黑盒模型,并在所有研究任务中使用相同的流程和提示。总体而言,我们的发现表明,这种“心智社会”(society of minds)的方法有望显著提升大语言模型的能力,并为语言生成领域的进一步突破铺平道路。
二、引言
近年来,大型语言模型(LLMs)在语言生成、理解和少样本学习方面表现出了卓越的能力。这些方法通常是在海量的互联网文本数据上进行训练的,而这些文本的质量和准确性并不能得到保证。因此,当前的模型可能会自信地编造事实,或在推理链条中出现不合理的跳跃。
近期有大量研究致力于提升语言模型的事实准确性和推理能力。这些方法包括使用少样本或零样本的思维链(chain-of-thought)提示、验证机制、自一致性方法,或引入中间推理步骤(如草稿板)等。我们注意到,这些技术通常是在单个模型实例上进行的。
相比之下,我们提出了一种互补的方法,受《心智社会》(Society of Mind,Minsky,1988)和多智能体系统的启发,其中多个语言模型实例(或智能体)分别提出自己的回答和推理过程,并通过多轮辩论共同达成一个一致的最终答案。具体来说,给定一个查询,多个语言模型实例首先独立生成各自的候选答案。然后,每个模型实例阅读并批评其他模型的回答,并基于这些内容更新自己的答案。这一过程在多个轮次中重复进行。
这种辩论过程促使模型构建出既符合其内部批评逻辑,又与其他智能体的回答相一致的答案。最终,这组模型可以在提出最终答案之前,同时维持多个推理链条和可能的答案。
我们发现,这种辩论方法在六项推理、事实准确性和问答任务上,均优于单模型基线方法,如零样本思维链(zero-shot chain of thought)和反思机制(reflection)。我们发现,使用多个模型智能体以及多轮辩论对于实现最佳性能都是至关重要的。
给定一个初始查询,尽管这些模型实例属于同一类模型,它们仍会提出多样化的答案(我们也研究了混合使用不同类型模型的情况,如ChatGPT和Bard)。在辩论并审查其他模型实例的回答后,我们发现这些模型几乎总是会收敛到一个更准确的一致答案。辩论结果也更少包含模型内部不确定的错误事实。这是因为随着辩论的进行,单个模型实例倾向于对不确定的事实产生分歧,并最终在答案中省略这些内容(见图12)。Notes:图12说明了多智能体辩论能有效减少传记生成中的事实错误,提高内容的一致性和准确性。

最后,我们发现,辩论的作用不仅仅是在一个模型群体中放大正确答案——我们还发现了许多案例,其中所有模型最初都给出了错误预测,但随着辩论的进行,最终得出了正确答案(见图4和图13)。
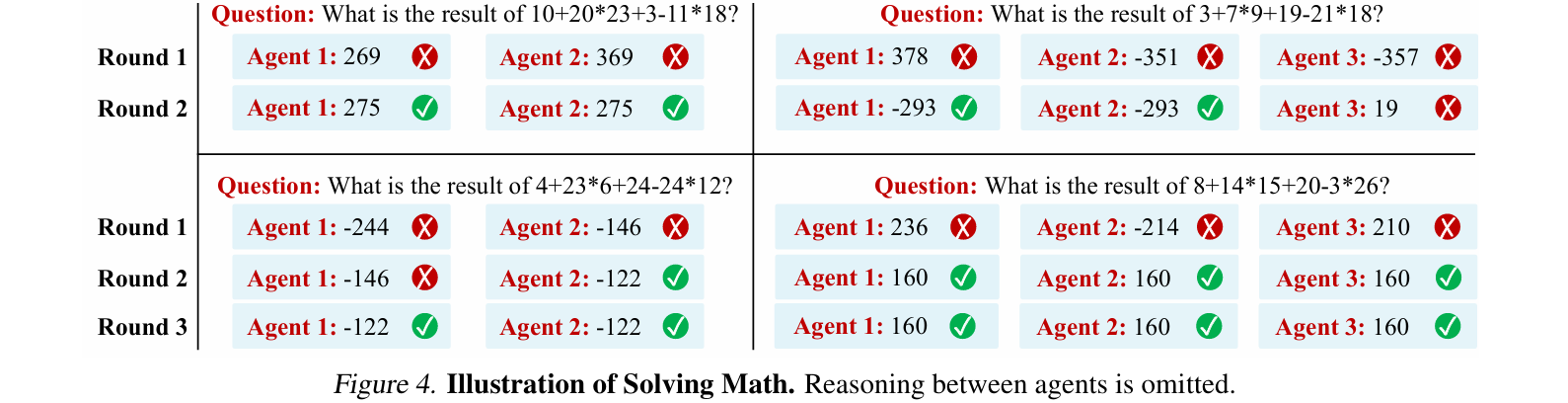
Note:图4展示了多个智能体在数学推理任务中的辩论过程。初始阶段(Round 1):多个智能体对同一个数学表达式给出了不同的错误答案。辩论阶段(Round 2-3):通过相互审查和更新,智能体逐步纠正了推理错误,最终达成了一致的正确答案。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











