







大模型幻觉的检测与消除
背景
大语言模型(Large Language Models, LLM)在许多下游任务上展现了杰出的性能,然而其中潜藏的幻觉问题 1 2 仍然不能被忽视。大模型有时会弄错用户的指令,这时产生的幻觉我们或许可以很快意识到,如前段时间大火的“3.11与3.9哪一个更大”,以及“strawberry中有多少个r”。而另一些幻觉则涉及常识或领域知识,通常表现为对事实的捏造等现象,当缺乏相关背景时很难直接发现。
一些通用的提示方法对缓解幻觉似乎有帮助,例如大家在使用大模型时,会让其采用思维链(Chain-of-Thought, CoT)3、回退推理(Step-Back Reasoning)4 等方式进行思考。但我们不能过于依赖这些方法。例如,近期的报告 5 指出,朴素的 CoT 主要在涉及数学、逻辑、算法的任务上展现出了优势,而在其他类型的任务上获得的收益较小。因此,为了解决幻觉现象,应当需要设计更加具有针对性的方法。
基于现有综述对幻觉检测与消除的分类,本文从下列三个方向来介绍一些相关工作:
- 分类器
- 不确定性度量
- 模型的评价能力
相关工作
分类器
论文名:Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs (2024.4) 6
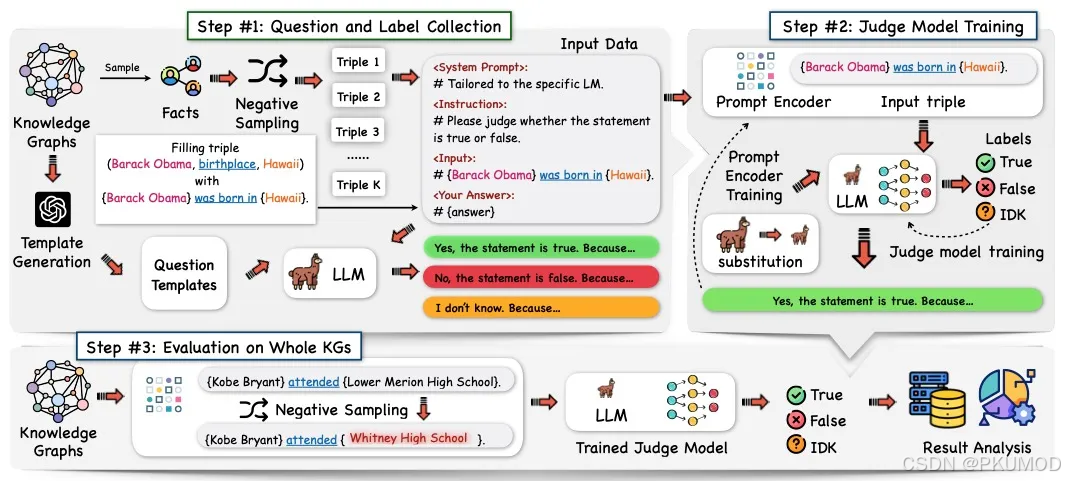
作者提出了名为 GraphEval 的框架,用知识图谱评估大模型的事实性。已有的方法从大规模的知识图谱中抽取子图,或者从文本文档中抽取知识子集来构建问答对评估大模型幻觉,只关注了特定领域下的幻觉。并且,许多方法需要大模型生成完整的回答文本,有更高的推理开销。若使用大模型生成的下一个 token logits 获得答案,这种方式得到的答案与大模型实际生成的文本答案存在一定的偏差。
与一些知识探测类工作类似,该方法从知识图谱中采样一部分三元组,通过模版转化为 statement,让大模型判断 statement 是否为真。考虑到开销问题,作者训练了一个评价模型(小模型)来模拟大模型对该 statement 的响应。评价模型以大模型的隐藏层为输入来预测 statement 的正确性,这样便同时解决了上文提到的开销与偏差问题,并且能轻易地扩展到更大规模的知识图上。
论文名:Knowledge-Augmented Language Model Verification (EMNLP’23) 7
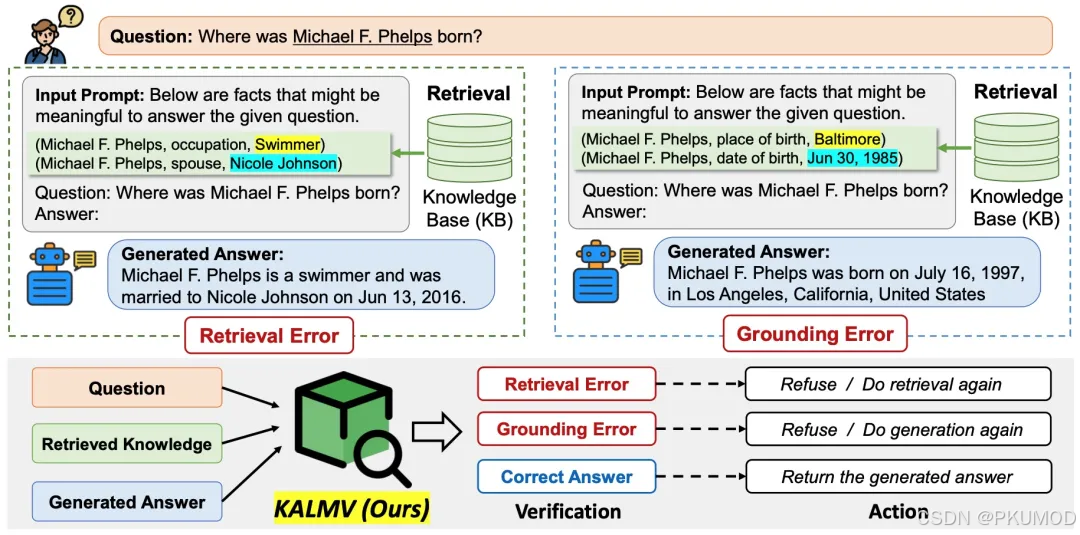
KALMV 主要关注 RAG 过程中的幻觉。在这个工作中,作者主要探讨了两种类型的幻觉:第一种是模型可能无法检索到与给定查询相关的知识,而第二种是模型可能不能在生成的文本中忠实地反映检索到的知识。作者设置了一个分类任务,并训练了一个独立的验证器来基于给出的问题、检索到的知识检测已生成的答案中出现的幻觉。分类的错误标签为 retrieval error(检索到的内容不符合意图)、grounding error(生成的内容没有基于知识)、correct,对应的操作为重检索、重生成与答案返回。
作者用启发式方法为用于指令微调的样本三元组 (问题,检索到的知识,答案) 赋予标签。对于输入,当检索到的知识不包含正确答案时,将其标记为 retrieval error,当检索正确,但大模型生成的答案与检索到的知识没有重叠的 token 时,则标记为 grounding error。剩下的样本标记为正确。
不确定性度量
论文名:A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation (2023.7) 8
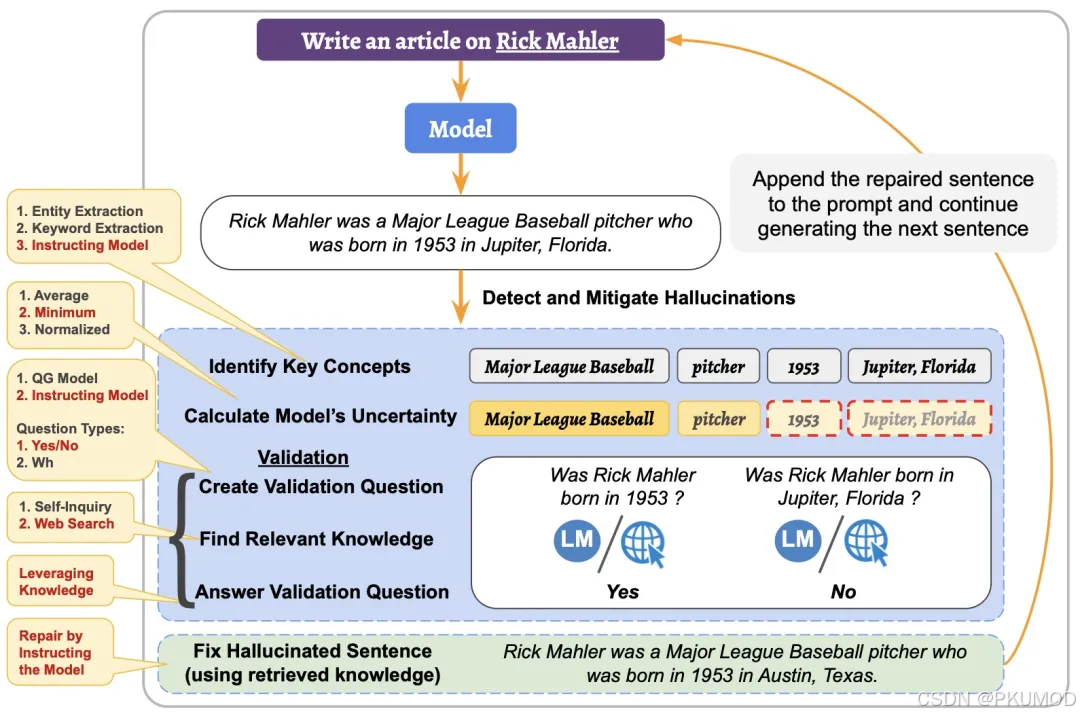
基于分类器的方法更多探测句子级别的幻觉,缺乏细粒度的幻觉检测能力。本工作从模型生成的内容中识别关键概念,包括实体、关键词等,并利用大模型给出的 logits 对应的 softmax 概率探测幻觉。对概念(包含 n n n 个 token)级别的不确定性,可以通过每个 token 概率的最小值、平均等方式计算:
s c o r e = MIN ( p 1 , p 2 , . . . , p n ) score=\text{MIN}(p_1,p_2,...,p_n) score=MIN(p1,p2,...,pn)
对不确定性高的概念,该方法通过指令创造一个针对大模型生成内容中,关于概念内容的验证问题并查询相关知识来回答,从而实现细粒度幻觉的检测。
论文名:Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval (2024.5) 9
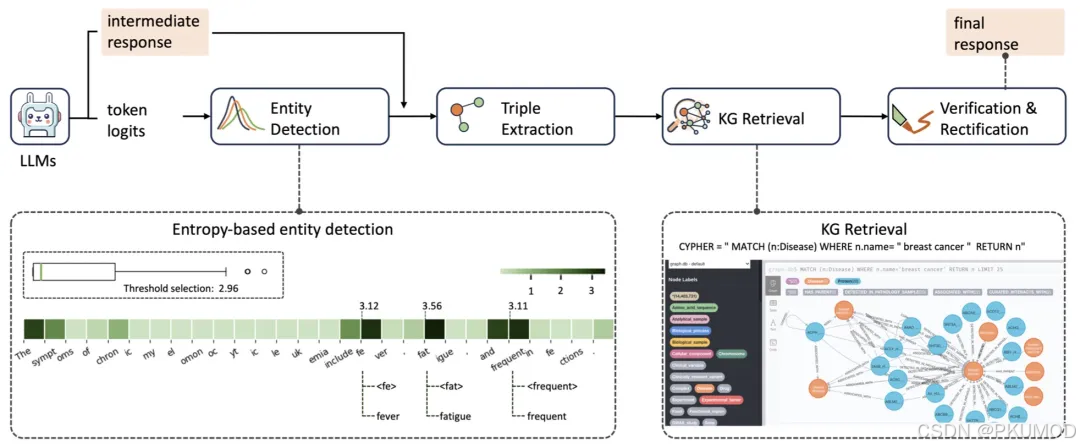
Re-KGR 聚焦于减少医学领域的检索工作量。相比上一工作,该方法采取了类似的方法定位生成响应中的高不确定性实体。进一步地,Re-KGR 提示大模型提取响应中包含的三元组,并重点探索包含上述实体的响应三元组中的幻觉现象。作者选用知识图谱作为可靠知识源,利用这些三元组中实体、谓词以及它们的同义词在知识图谱中搜索背景三元组。这些背景知识将用于校验与修改原始响应。当某个响应三元组与另一个背景三元组具有超过阈值且最高的 spaCy 相似度时,作者替换原始响应中的文本,并采用语法纠正模型来维持完整的输出。
模型的评价能力
论文名:SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (EMNLP’23) 10
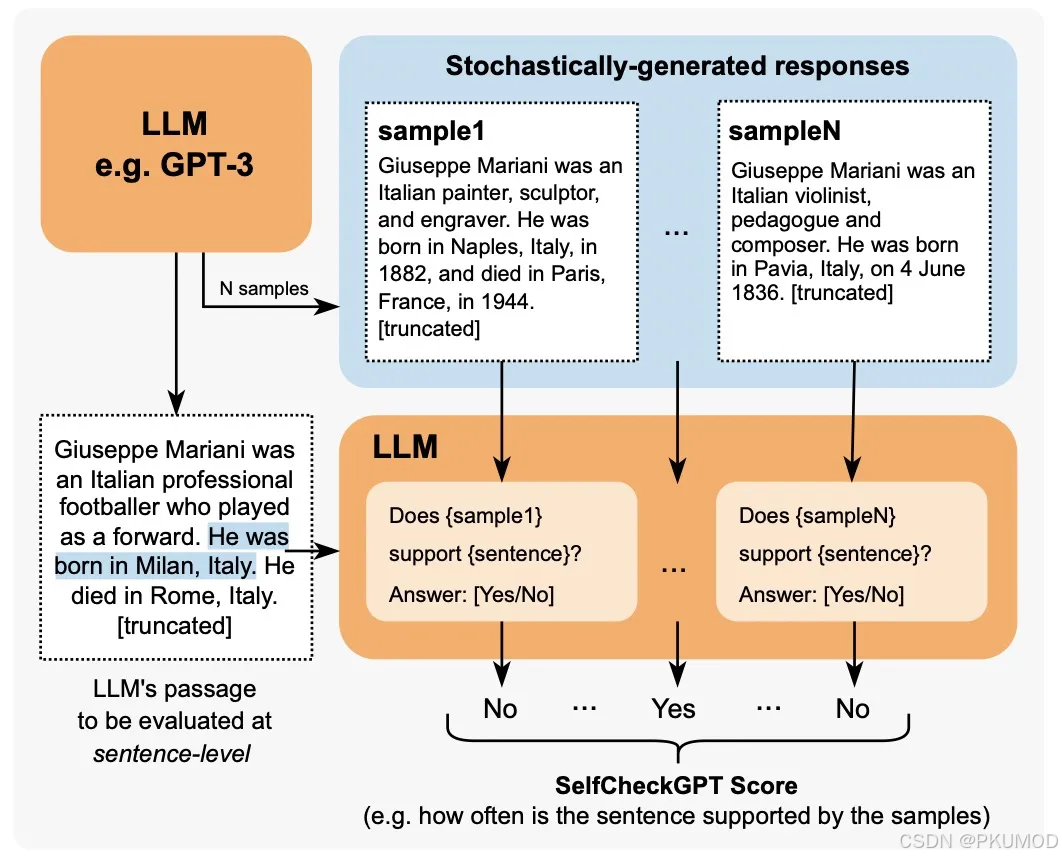
基于模型评价的方法相比上文的不确定性方法是一种黑盒方法,也就是不需要 token 级别的概率,只需要文本响应即可。SelfCheckGPT 有一种比较直观的动机,类似于 Google brain 所提出的 self-consistency 一样,如果大模型对于一个事实接受过训练,那么生成的响应会更加相似,分布也更加集中。而如果大模型对一个事实存在幻觉,则经过多次采样得到的结果可能会出现分歧,并且相互矛盾。那么,基于大模型对 query 采样多个响应,然后测量他们之间的一致性,就能用于探测幻觉。这种方式适用于检测句子级别的幻觉。
论文名:LM vs LM: Detecting Factual Errors via Cross Examination (2023.5) 11
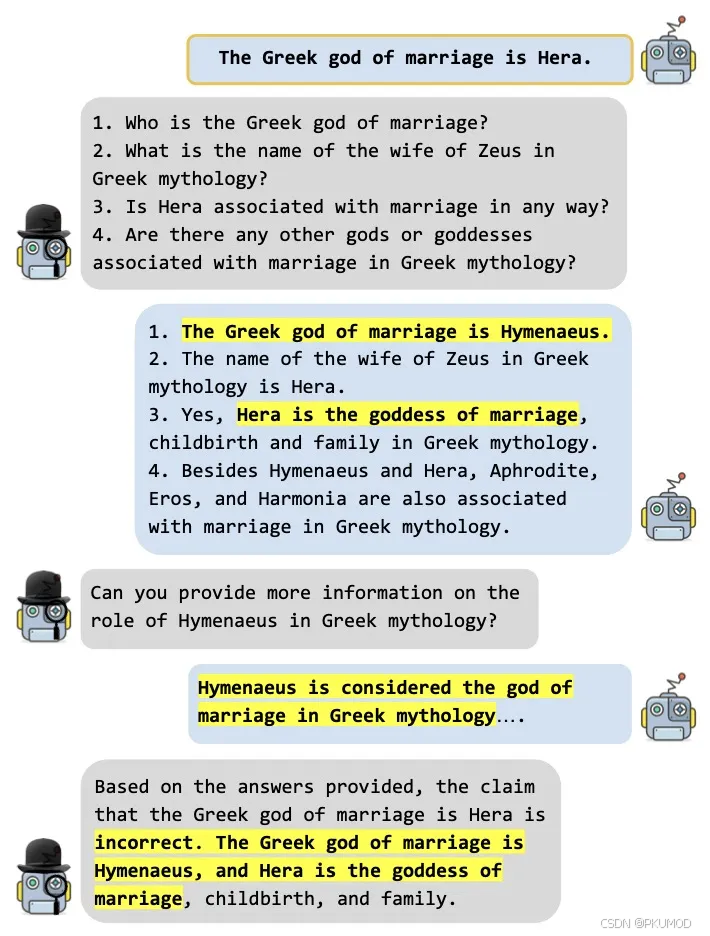
除了对单个模型采样的多个回复进行一致性验证外,也可以采用交叉检验机制来检测大模型生成内容中的幻觉。这项工作的目标是让一名基于大模型的 examiner 来评估另一个基于大模型的 examinee 提出的声明。在每一步中,examiner 提出问题,以找出与 examinee 最初的声明不一致的地方,而不一致现象可被视为 examinee 在其原始声明中的不确定性。这种多轮的问询一直持续到没有进一步的问题并且可以提供最终回答为止。此时的 examiner 将根据多个轮次的交互判断是否存在幻觉。
另一些工作则引入了更多的智能体 12,让多个智能体经过多轮的相互交流讨论以达成共识,并且在通信结构 13、智能风格 14 等角度进行了探索。因篇幅原因,此处不在赘述。
总结
本次论文分享围绕大模型幻觉的检测与消除中的分类器、不确定性度量、模型的评价能力共三个方面进行了调研与整理。对于未来的研究方向,笔者认为,在训练中可以通过知识图谱等可信知识源批量生成高质量数据,以及设计相关算法排除低质、有害的数据,防止幻觉通过训练引入大模型。在推理过程中则应当研究更为鲁棒的推理机制,在检索生成、思维链、辅助代码等基础上提出更为复杂的融合策略,提升大模型的可信度。
参考文献

欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
实验室开源产品图数据库gStore:
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore
Ye, Hongbin, et al. “Cognitive mirage: A review of hallucinations in large language models.” arXiv preprint arXiv:2309.06794 (2023). ↩︎
Huang, Lei, et al. “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.” arXiv preprint arXiv:2311.05232 (2023). ↩︎
Kojima, Takeshi et al. “Large Language Models are Zero-Shot Reasoners.” arXiv preprint arXiv:2205.11916 (2022). ↩︎
Zheng, Huaixiu Steven et al. “Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models.” arXiv preprint arXiv:2310.06117 (2023). ↩︎
Sprague, Zayne et al. “To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning.” arXiv preprint arXiv:2409.12183 (2024). ↩︎
Liu, Xiaoze et al. “Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs.” arXiv preprint arXiv:2404.00942 (2024). ↩︎
Baek, Jinheon et al. “Knowledge-Augmented Language Model Verification.” arXiv preprint arXiv:2310.12836 (2023). ↩︎
Varshney, Neeraj et al. “A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation.” arXiv preprint arXiv:2307.03987 (2023). ↩︎
Niu, Mengjia et al. “Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval.” arXiv preprint arXiv:2405.06545 (2024). ↩︎
Manakul, Potsawee et al. “SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models.” arXiv preprint arXiv:2303.08896 (2023). ↩︎
Cohen, Roi et al. “LM vs LM: Detecting Factual Errors via Cross Examination.” Conference on Empirical Methods in Natural Language Processing (2023). ↩︎
Du, Yilun et al. “Improving Factuality and Reasoning in Language Models through Multiagent Debate.” arXiv preprint arXiv:2305.14325 (2023). ↩︎
Yin, Zhangyue et al. “Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication.” Conference on Empirical Methods in Natural Language Processing (2023). ↩︎
Wang, Zhenhailong et al. “Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration.” North American Chapter of the Association for Computational Linguistics (2023). ↩︎

















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









