







Fast R-CNN相当于是在RCNN跟SPPNet的基础的又进行了改进,速度精度增加。
引用流程图
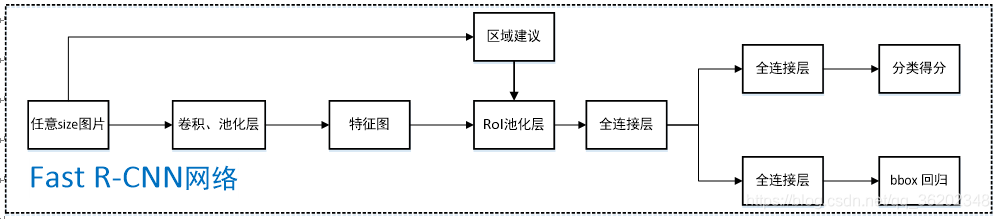
首先它延续了SPPNet的金字塔最大值池化层,置于网络最后一个卷积层,相当于简化版的SPP,因为只有一层金字塔,(AlexNet即pool5, 6 * 6),目的是保证输入Rol(建议框)h * w 后,经过 [h/H, w/W] 最大值池化, 输出统一大小H * W,对应之后的全连接层配置;
其次,针对RCNN对SS算法提取的2k个候选框都要丢进CNN里算,耗时间又麻烦, Fast rcnn跟SPPNet一样,直接将图片先丢进去,算出来整张图的feature map,然后通过映射关系,得到Rol建议框对应的feature map,再输入Rol pooling layer;
最后, 针对RCNN与SPPNet多阶段的任务,又要训练SVM,完了还要训练回归器,麻烦的不行,太耗时间,Fast cnn将这俩合在一块做,从 Rol pooling layer 出来以后,经过原来的两个全连接层,开始分叉,一个是 fc + softmax 输出,用于类别判断, 另一个是 fc +bbox回归, 用于精修物体框的位置。 同时,采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度(这块没咋看,回头细看)。
还有一点, 是在训练的样本数据方面(引用):
在SPP-NET跟RCNN中,微调采用RoI-centric sampling,从所有图片的所有RoI中均匀取样,由于BP需要计算每一个RoI感受野的卷积层,通常会覆盖整个图像,这样就会导致速度太慢,只能微调后面的全连接层,无法同时微调前面的卷积层。
而Fast R-CNN采用image-centric sampling,每个mini-batch由N个图片(N=2)中的R个Proposal(R=128)组成,同一图像的RoI共享计算和内存,这种方式比从128张不同图片中提取1个Proposal的方式快64倍,可以同时微调卷积层和全连接层,注意,实验发现太浅层的卷积层不需要微调,可以减少训练时间,而且mAP基本没有差别。
流程图(引用):
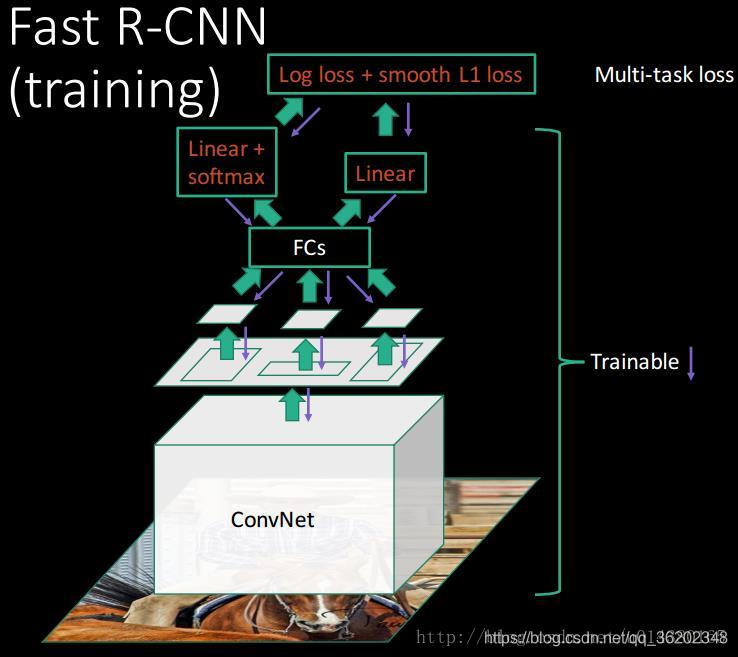
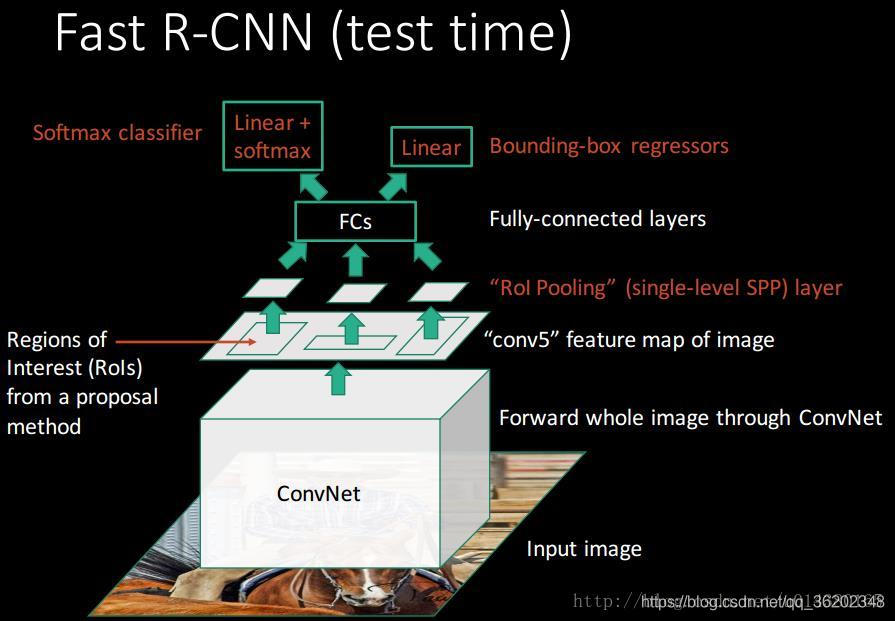
参考:
https://blog.csdn.net/qq_14839543/article/details/54425051#commentBox 译文
https://blog.csdn.net/hust_lmj/article/details/78974348 系列总结
https://www.cnblogs.com/CodingML-1122/p/9043124.html 写的挺好
https://blog.csdn.net/shenxiaolu1984/article/details/51036677
https://blog.csdn.net/xg123321123/article/details/53067518
https://blog.csdn.net/u014380165/article/details/72851319














 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









