









Nature Machine Intelligence: 刘洋彧等利用神经常微分方程预测微生物代谢谱
Wang T, Wang X W, Lee-Sarwar K A, et al. Predicting metabolomic profiles from microbial composition through neural ordinary differential equations[J]. Nature Machine Intelligence, 2023, 5(3): 284-293.
1. 摘要

通讯作者: 哈佛大学医学院和布莱根女子医院刘洋彧老师
表征微生物群落的代谢特征对于理解其生物学功能及其对宿主或环境的影响至关重要。直接测量这些特征的代谢组学实验是困难和昂贵的,然而,量化微生物群落的物种组成的测序方法已经发展得很好,而且成本相对较低。能够从微生物组成预测代谢组谱的计算方法可以节省代谢组谱实验所需的大量时间。然而,尽管已有了一些研究成果,我们仍然缺乏一种预测能力强、普遍适用性强、可解释性好的计算方法。在这里,我们开发了一种基于最先进的深度神经网络模型家族的新方法- mNODE(Metabolomic profile predictor using Neural Ordinary
Differential Equations,即使用神经常微分方程的代谢组学预测器)。
- 我们展示了令人信服的证据,表明mNODE在预测人类微生物组和几种环境微生物组的代谢组学特征方面优于现有方法。
- 此外,在人类肠道微生物组的情况下,mNODE可以自然地纳入饮食信息,以进一步增强代谢组学谱的预测。
- 并且,mNODE的药敏分析使我们能够揭示微生物-代谢物的相互作用,这可以使用合成数据和真实数据进行验证。
本研究结果表明,mNODE是研究微生物组-饮食-代谢组关系的有力工具,有助于未来精准营养研究。
2. 引言
微生物群落的代谢活动在形成其生物学功能及其与宿主或环境的相互作用中起着重要作用。例如,人类肠道微生物群影响宿主生理的一个关键方式涉及小分子的产生[1,2,3]。
肠道内的微生物可以消化膳食纤维(即纤维素、半纤维素、木质素、果胶、粘液等不易消化的碳水化合物)[4],并最终产生重要的代谢物,如必需氨基酸[5]和短链脂肪酸[2],这些对人类健康至关重要[6,7,8]。微生物衍生的代谢物也直接或间接地影响血液代谢物[9,10]。研究发现,人类粪便代谢组中的代谢物与血液中检测到的代谢物有明显的重叠[9]。要了解并最终通过调节营养或益生菌给药来控制微生物群落,第一步是将微生物群落的代谢组学特征与其微生物组成联系起来。
代谢组谱的实验测量通常需要代谢组学技术,如LC-MS(液相色谱-质谱)或GC-MS(气相色谱-质谱)。然而,代谢组学实验是困难的,并且设备昂贵[11,12,13],缺乏自动化[14,15],以及有限的代谢物覆盖[11,16]。相比之下,通过扩增子或散弹枪宏基因组测序进行微生物组成的实验测量成本更低,更容易自动化,并提供良好的微生物覆盖率[17,18]。因此,与代谢组学数据相比,扩增子或散弹枪宏基因组测序数据更容易用于复杂的微生物群落。因此,需要开发一种基于微生物组成预测代谢谱的计算方法。此外,这种方法可以促进我们对微生物及其代谢物之间相互作用的理解。
为了实现这一目标,已经提出了许多计算方法,它们可以分为以下三类。
(1)基于参考的方法,如MAMBO[19]、MIMOSA[20]、Mangosteen[21]。
- 在MAMBO (Metabolomic Analysis of metagenomics using flux Balance Analysis and Optimization)中,参考微生物基因组被用来重建基因组尺度的代谢模型( genome-scale metabolic models, GEMs)。然后是宏基因组群落丰度剖面(即微生物组成)与GEMs的生物量生产相关(通过通量平衡分析获得)。最后,通过蒙特卡罗采样算法的多次迭代对相关性进行优化。
- MIMOSA(Model-based Integration of Metabolite Observations and Species Abundances)和Mangosteen((Metagenome-based Metabolome Prediction)都是基于参考的基因到代谢物预测方法。注意,所有这些基于引用的方法都严重依赖于查询数据库和gem的完整性和准确性。
(2)生态导向方法,其中微生物和代谢物的丰度都被视为代谢级联的最终产物,通过微生物群落的生态网络(即微生物的代谢物消耗和副产物生成反应)进行传播[22,23,24,25]。这些方法在很大程度上依赖于微生物群落生态网络的完整性和准确性。
(3)基于机器学习(ML)的方法,从配对的微生物组和代谢组数据集中训练,然后根据其微生物组成预测从未见过的微生物组样本的代谢特征,而不使用任何参考数据库或有关基因与代谢物之间关系的领域知识。各种ML技术,如弹性网络[26]、稀疏NED(Neural Encoder-Decoder)[27]、多层感知器[28]和word2vec[29]已被用于预测微生物组成的代谢谱。
尽管这些基于机器学习的方法规避了上述基于参考或生态导向方法的限制,并已被证明在各种情况下产生了有希望的结果,但这些基于机器学习的方法都没有利用最先进的深度神经网络模型,如神经常微分方程(NODE, Neural Ordinary Differential Equation)[30],因此它们的性能没有得到充分最大化。
作为一种新的深度神经网络模型家族,NODE在计算生物学中并没有得到广泛的应用。残差神经网络(ResNet, Residual neural network )是NODE的前身。作为ResNet最重要的特征,跳跃连接与ODE求解器中的欧拉步非常相似[31,32]。更具体地说,一个残差块可以看作是ODE语言中变量的一个小时间变化[31,32]。这种类比促进了NODE的发明[30]。NODE不像ResNet那样指定隐藏层的离散序列,而是使用神经网络参数化隐藏状态的导数,并使用ODE求解器计算输出。在某种意义上,NODE代表连续深度模型,具有常数内存成本,根据每个输入调整其评估策略,并且可以显式地以数值精度换取速度[30,33]。因此,可以用更少的参数获得更高的精度,而无需显式引入许多神经层[30,33]。
在这里,我们利用NODE的功能,提出了一种称为mNODE (Metabolomic profile predictor using Neural Ordinary Di (erential Equations))的计算方法来预测微生物组成的代谢组学特征。我们首先使用具有交叉喂养相互作用的微生物消费者-资源模型生成合成数据,以验证(1)mNODE 优于现有的基于ml的方法;(2)补充营养信息作为额外的输入变量,可以更准确地预测代谢组,特别是当样本之间的营养相似性较低时。然后,我们使用在真实微生物群落中收集的微生物组和代谢组数据,将mNODE与现有的基于机器学习的方法进行比较,发现mNODE优于所有现有的基于ml的方法。此外,我们还证明,通过将食物频率问卷中的食物概况作为额外输入,我们可以进一步提高mNODE的性能。此外,为了揭示微生物-代谢物的相互作用,我们使用mNODE进行了敏感性分析,以研究一种代谢物的预测浓度如何响应一种微生物物种相对丰度的扰动。我们清楚地证明,所有微生物-代谢物对的敏感性都可以用来准确预测微生物-代谢物相互作用,这些数据是由微生物消费者-资源模型生成的。最后,我们发现基因组证据有力地支持了人类肠道微生物组数据集中许多预测的微生物-代谢物相互作用。
基于机器学习方法预测微生物组的代谢谱的相关论文:
[26] Mallick, H. et al Predictive metabolomic profiling of microbial communities using amplicon or metagenomic sequences. Nature communications 10, 1–11 (2019).
[27] Le, V., Quinn, T. P., Tran, T. & Venkatesh, S. Deep in the bowel: highly interpretable neural encoder-decoder networks predict gut metabolites from gut microbiome. BMC genomics 21, 1–15 (2020).
[28] Reiman, D., Layden, B. T. & Dai, Y. Mimenet: Exploring microbiome-metabolome relationships using neural networks. PLoS Computational Biology 17, e1009021 (2021).
[29] Morton, J. T. et al Learning representations of microbe–metabolite interactions. Nature methods 16, 1306–1314 (2019).
神经常微分方程:
[30] Chen, R. T., Rubanova, Y., Bettencourt, J. & Duvenaud, D. Neural ordinary di↵erential equations. arXiv preprint arXiv:1806.07366 (2018).
3. 结果(Results)
3.1 mNODE概述
我们的目标是根据微生物组成和饮食的潜在可用信息来预测微生物群落的代谢组学特征。图1显示了两个训练场景的假设示例,当我们遵循相同的mNODE模型训练协议时:(1)不将饮食信息作为输入的一部分,(2)将饮食信息作为输入的一部分。本示范示例系统包括3种微生物、2种膳食项、4种代谢物和15个样本。10个样本用于训练集,其余的5个样本用于测试集(问题:模拟数据集是怎么生成的?为什么有效呢?)。我们想比较在输入和不输入饮食信息的情况下预测代谢组学特征的性能,以了解饮食信息的存在在多大程度上有助于我们的预测。对于具有配对微生物组和代谢组数据的给定样本集,我们将样本随机分成两个不重叠的集: 训练集和测试集。我们对训练集进行了5折交叉验证,以确定最大预测能力的最优超参数集(即隐藏层的维度和mNODE中L2正则化的权重参数)。在这里,对于每一种代谢物,我们都可以计算出在不同样品的预测浓度和实验观察浓度之间的斯皮尔曼相关系数(),以“ ρ \rho ρ”表示。任何计算方法(如mNODE)的总体预测能力都被评估为实验中测量的所有代谢物的平均SCC, ρ ˉ \bar \rho ρˉ。经过5次交叉验证后,我们在整个训练集上使用最优的超参数集对模型进行重新训练,然后使用这个训练好的模型对测试数据进行预测(图1c)。
由于微生物种类( N s N_s Ns)和代谢物( N m N_m Nm)的数量通常是不同的,因此不可能直接应用原始的NODE (neural ODE)架构[30],这需要输入和输出维度相等。在这里,我们利用多层感知器(MLP)在数据维度上的灵活性,并将MLP与NODE结合起来学习从输入(微生物组成)到输出(代谢物浓度)的映射。更具体地说,我们在在两个紧密连接的层之间引入NODE作为一个模块**(图1b)。我们的mNODE从一个密集连接的层开始(图1b中蓝色节点到灰色节点的实线),然后是一个非线性激活函数(双曲正切函数“tanh”)。密连接层将输入映射到维数为 N h N_h Nh的隐藏层。通过密连接层后,NODE模块对维数为 N h N_h Nh的隐藏空间(隐藏层中的神经元在图1b中表示为灰色节点)进行操作。在数学上,我们的NODE模块将 t = 0 t=0 t=0时刻的隐藏变量 x ( t = 0 ) ∈ R N h x(t=0) \in R^{N_h} x(t=0)∈RNh映射到它在 t = T t=T t=T时刻的状态 x ( t = T ) ∈ R N h x(t = T) \in R_{N_h} x(t=T)∈RNh, 遵循常微分方程 d x d t = f ( x ) \frac{dx}{dt}= f(x) dtdx=f(x),其中 f ( x ) f(x) f(x)由具有一个维数为 N h N_h Nh的隐藏层的可学习多层感知机近似(图1b,中间)**。最后,为了从隐藏变量中生成代谢组预测,我们引入了另一个完全连接的层(图1b中灰色节点到红色节点的实线)。在这项研究中,我们没有试图预测代谢组学特征随时间的变化; 相反,基本思想是使用NODE通过MLP对连续层建模其一阶导数来拟合函数,以减少内存和训练时间。采用L2正则化防止过拟合。总的来说,mNODE中有两个超参数需要校准:隐藏层的维度 N h N_h Nh和 L 2 L_2 L2正则化的权重参数。
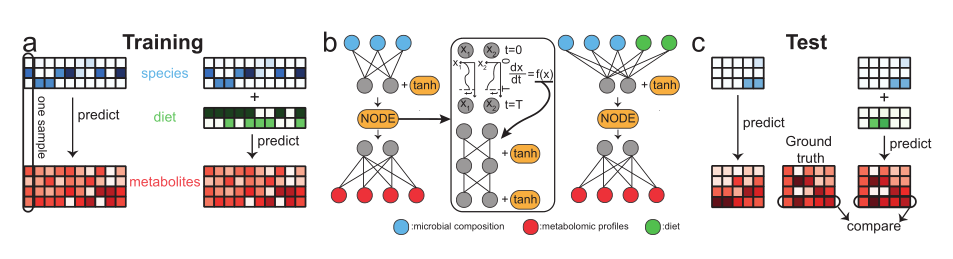
**图1:根据物种微生物组成和其他饮食信息预测代谢组学特征的mNODE工作流程。**在所有面板上,蓝色的阵列代表微生物组成。绿色数组表示饮食信息。红色阵列代表代谢组学特征。所有数组都没有丢失数据,所有数组中的白色立方体只是表示小值。总共有15个假设样本,3个物种,2种膳食项目和4种代谢物被用来说明这个想法。样本按2/1的比例分为训练集和测试集。**a. 训练集中的10个样本用于训练机器学习模型。**有两种方法可以预测代谢组学特征:一种不包括输入的饮食,另一种除了微生物组成外还包括饮食。**b. 两种训练方法的mNODE架构。**神经ODE是该体系结构的中间模块,它计算ODE的时间演化,ODE的一阶时间导数由具有一个隐藏层的MLP近似。灰节点表示mNODE隐藏层中的神经元。**c. 经过充分训练的mNODE可以对测试集中的代谢组学特征进行预测。**对于每种代谢物,计算其跨样本的预测概况和测试集中的真实概况之间的Spearman秩和相关系数,以量化其可预测性。
3.2 使用合成数据验证mNODE
为了验证mNODE,我们使用微生物消费者-资源模型(MiCRM, https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1006793) 生成了合成数据,该模型考虑了营养竞争和交叉喂养相互作用[34]。我们通过从元种群池中取样一组物种和从营养池中取样一组营养素来启动群落组装,然后收集稳态微生物物种相对丰度作为微生物组成和稳态营养浓度作为代谢组学特征,创建了每个独立的合成群落(“样本”)。具体来说,我们假设有一个包含10个物种的元种群池和一个包含10种营养素的营养池,所有营养素的营养供应率为预定。为了引入样本间的可变性,我们假设元种群池中的每个物种以物种采样概率 p s p_s ps被引入到每个样本中,营养池中的每种营养物质以其预定的供应率以营养物质采样概率 p n p_n pn被提供到同一生态系统中。在采样事件确定了最初引入的物种和营养物之后,模拟物种生长、营养物消耗和副产品产生的动态,直到系统达到稳定状态。从独立组装模拟中收集稳态下的物种相对丰度和营养浓度作为合成数据中的微生物组成和代谢组学特征(详见方法)。
为了探索mNODE是否比现有的基于机器学习的方法产生更好的代谢组预测,我们生成了300个样本,物种采样概率 p s = 0.5 p_s=0.5 ps=0.5,营养采样概率 p n = 0.6 p_n = 0.6 pn=0.6。我们将所有独立样本的20%(60个样本)作为测试数据集,而剩余的240个样本用作训练数据集。图2a1-a3通过3个指标显示了mNODE与以前基于ml的方法(MelonnPan[26]、sparse NED[27]、MiMeNet[28]和ResNet[35])之间的性能比较: (1) SCC的平均水平, ρ ˉ \bar \rho ρˉ (图2a1, b1, c1),(2)前5位SCC的平均水平, ρ ˉ 5 \bar \rho_5 ρˉ5 (图2a2, b2, c2), (3) SCC大于0.5的代谢物(与微生物消费者-资源模型中的营养物质相同)的数量, N ρ > 0.5 N_{\rho>0.5} Nρ>0.5(图2a3, b3, c3)。选择第一个性能指标来捕获总体性能,而选择最后两个指标来分别表征良好预测的代谢物的可预测性以及可以良好预测的代谢物的数量。我们发现,在所有三个性能指标中,mNODE比所有其他方法产生更好的预测。
之前的比较使用固定的训练样本量为240。我们想知道需要多少样本才能达到我们在这里研究的系统的最佳性能。为了保证模型性能在测试集上的测量一致,我们将保持在图2a1-a3中使用的相同的随机训练-测试分割,在保持测试集相同的情况下减少训练样本(通过对原始训练集进行一次包含240个样本的子采样),用更少的训练样本训练mNODE,并使用相同的包含60个样本的测试集来测量 ρ ˉ \bar \rho ρˉ。在输入不使用营养供给率的情况下,当训练样本量达到图2b1-b3中饱和实线所示的营养物数量 N r ( = 10 ) N_r(=10) Nr(=10)与微生物种类 N s ( = 10 ) N_s(=10) Ns(=10)之和的8倍时,性能达到饱和。相反,当输入中加入营养供给率时,训练样本量约为(Nr + Ns)的4倍(图2b1-b3中的饱和虚线)时,性能饱和,远低于不使用营养供给率的情况下所需的训练样本。此外,值得注意的是,在训练样本量为20的情况下,增加营养供给率比仅依靠训练样本量为240的微生物组成产生更好的性能(图2b1-b3)。【什么是营养供给率?营养供给率如何衡量?】
除了训练样本量导致的两种方法在代谢组学预测中的性能差异外,我们很自然地推测,性能差异也可能取决于样本间的营养相似性,因为营养变量信息较少可能会使它在鉴别代谢组谱时不那么有用。为了测试这一点,我们系统地调整营养采样概率 p n p_n pn,因为更高的 p n p_n pn意味着更多相似的营养供应。图221 -c3显示了三个性能指标如何随着 p n p_n pn的增加而变化。我们发现,当mNODE的输入中不包括养分供应率时,所有3个指标都随着 p n p_n pn从20%增加到100%而增加: (1)$\bar \rho 从 0.208 增加到 0.958 ; ( 2 ) 从0.208增加到0.958;(2) 从0.208增加到0.958;(2)\bar \rho_5$从0.398到0.992的变化;(3) N ρ > 0.5 N_{\rho >0.5} Nρ>0.5从0到10的变化。当输入中包括养分供应速率时,mNODE的性能在很大范围内的 p n p_n pn值始终很高。当 p n = 100 p_n = 100% pn=100时,不同样本中独立群落的养分供应率没有任何变化,因此养分供应率变得多余,这解释了为什么两种方法显示出相似的性能(图221 -c3中更接近的度量值)。
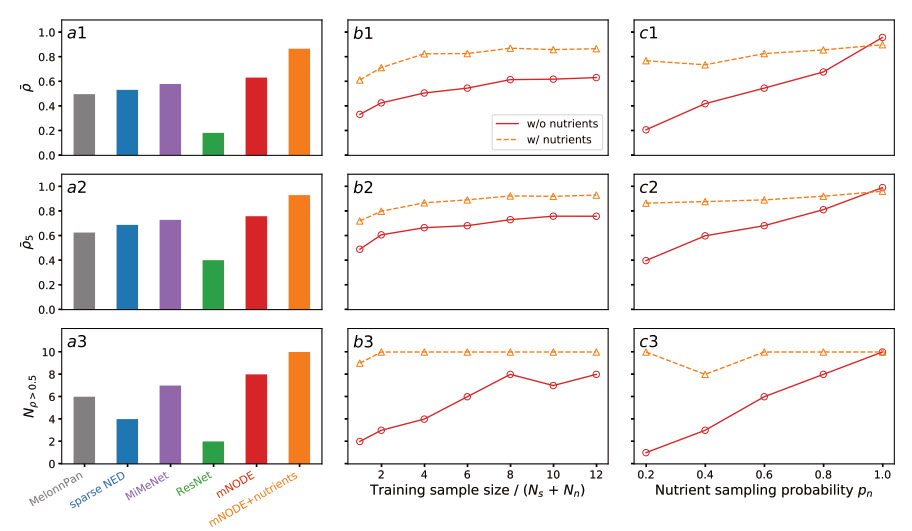
图2:微生物消费者-资源模型生成的合成数据对mNODE的模型比较和验证。mNODE的预测性能通过3个指标与其他方法进行比较:a1平均SCC (Spearman Correlation Coefficient) $\bar \rho $,a2前5名平均SCC ρ ˉ 5 \bar \rho_5 ρˉ5,以及a3 SCC大于0.5 代谢物的数量 N ρ > 0.5 N_{\rho > 0.5} Nρ>0.5。**b1-b3.**当养分采样概率(即外部提供的养分的比例)pn = 0.6,物种采样概率(即引入的物种的比例)ps = 0.5时,mNODE的预测性能作为训练样本量的函数。**c1-c3.**训练样本量为240,物种抽样概率 p s = 0.5 p_s = 0.5 ps=0.5时mNODE的预测性能。带圆圈的实线是在mNODE输入中不包括营养供给率(即微生物消费者-资源模型中的饮食)时的预测结果。带三角形的虚线是在mNODE输入中包含营养供给率时的预测结果。
3.3 mNODE在真实数据上的优越性能
在使用合成数据对mNODE进行验证后,我们使用实际数据对其进行了系统测试。总共有5个微生物组和代谢组配对的数据集进行了分析。这些数据集收集于不同环境中的微生物群落,如人类肠道[36,37,38,39,40]、人类血液[37,38,39,40]、土壤生物结皮[41]和人类肺部[23]。与我们在合成数据上使用的三个指标类似,在这里,我们基于平均SCC ρ ˉ \bar \rho ρˉ、前50名平均SCC ρ ˉ 50 \bar \rho_{50} ρˉ50以及SCC大于0.5的代谢物的数量(即 N ρ > 0.5 N_{\rho>0.5} Nρ>0.5)来评估模型的性能。我们从数据集PRISM + NLIBD开始,该数据集收集了CD(克罗恩病)患者、UC(溃疡性结肠炎)患者和健康个体的粪便样本[36]。这个基准数据集是独一无二的,因为存在两个IBD队列:一个来自马萨诸塞州总医院(PRISM)的155名成员队列和一个来自荷兰(NLIBD/LLDeep)的65名成员验证队列。按照相同的方案收集两个队列,并以相同的方式处理(详见方法和Franzosa等[36])。对于这个数据集,我们首先根据PRISM队列的5倍交叉验证结果选择了mNODE的超参数。然后,我们在整个PRISM队列中使用200个选定的超参数训练mNODE,并计算NLIBD队列代谢组的预测。图3a1-a3显示了5种方法在PRISM上经过训练后在测试集NLIBD上的表现。我们发现所有基于ml的方法中,mNODE有最高的$\bar \rho ( 0.294 ,而 M i M e N e t 为 0.191 ) ,最高的前 50 名的 (0.294,而MiMeNet为0.191),最高的前50名的 (0.294,而MiMeNet为0.191),最高的前50名的\rho ( 0.642 ,而 M i M e N e t 为 0.512 ) ,最高的 (0.642,而MiMeNet为0.512),最高的 (0.642,而MiMeNet为0.512),最高的N_{\rho > 0.5}$(93,而来自MiMeNet的是28)。此外,我们通过补充图S1中的散点图直接比较了带注释的代谢物。mNODE比目前最先进的ML方法:MiMeNet(补充图S1c)更好地预测了 76.8 % 76.8\% 76.8%的代谢物。如果我们只关注预测良好的代谢物(根据mNODE或MiMeNet,代谢物的$\rho $大于0.5),则 91.9 % 91.9\% 91.9%的代谢物由mNODE比由MiMeNet更好地预测(补充图S1d)。
为了检验mNODE的优越性能是否独立于微生物群落所在的环境,我们收集了另外4个数据集:(1) 172例囊性纤维化患者的肺痰样本[23],(2)连续5次润湿事件后的19例沙漠土壤生物痂样本[41],(3)340名参加VDAART215(维生素D产前哮喘减少试验)研究的3岁儿童的粪便样本[37,38,39,40],以及(4)340名参加VDAART研究的儿童的血浆样本[37,38,39,40]。不同方法在四个数据集上的系统比较如图3b-e所示。对于囊性纤维化患者的肺样本,mNODE提供了最高的$\bar \rho $ (0.526,而MiMeNet为0.402),最高的$\rho_{50} $ (0.817,而MiMeNet为0.636),以及 N ρ > 0.5 N_{\rho>0.5} Nρ>0.5(95,而MiMeNet为57)。对于沙漠土壤生物结皮样品,mNODE给出了最高的$\bar \rho ( 0.425 ,而 M i M e N e t 为 0.178 ) ,最高的 (0.425,而MiMeNet为0.178),最高的 (0.425,而MiMeNet为0.178),最高的\bar \rho_{50} $ (0.743,而MiMeNet为0.492), N ρ > 0.5 N_{\rho>0.5} Nρ>0.5(43,而MiMeNet为20)。对于VDAART中儿童的粪便样本和血浆样本,mNODE的预测效果要比MelonnPan [26]和sparse NED [27]好得多,并且其预测能力略好于MiMeNet (粪样的 $ \bar \rho 为 0.198 ,而来自 M i M e N e t 的为 0.192 ; 血浆样品的 为0.198,而来自MiMeNet的为0.192;血浆样品的 为0.198,而来自MiMeNet的为0.192;血浆样品的\bar \rho $为0.226,而来自MiMeNet的为0.200)。
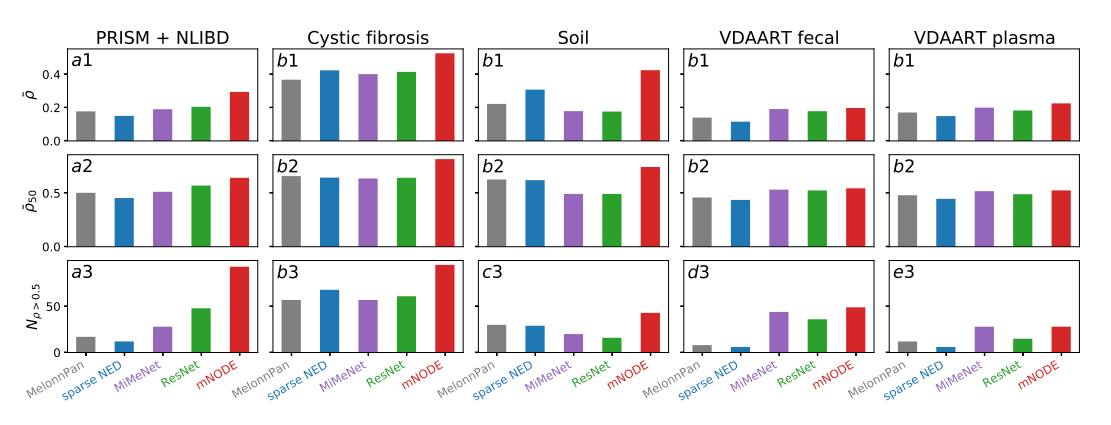
**图3:mNODE与现有方法在真实微生物群落数据集上的性能比较。**我们采用了3个指标来比较模型的性能:平均SCC ρ ˉ \bar \rho ρˉ、前50名平均SCC ρ ˉ 50 \bar \rho_{50} ρˉ50和SCC大于0.5 N的代谢物的数目 N ρ > 0.5 N_{\rho > 0.5} Nρ>0.5。除PRISM和NLIBD数据集[36]外,所有数据集[36、23、41、37、38、39、40]均按80/20的比例随机分为训练集和测试集。a1-a3方法在PRISM训练和NLIBD测试后的表现[36]。b1-b3方法对囊性纤维化患者肺标本数据的性能分析[23]。c1-c3. 5次润湿事件后土壤生物结皮数据处理方法的性能[41]。**d1-d3.**方法对3岁儿童粪便样本数据的处理效果[37,38,39,40]。**e1-e3.**方法对3岁儿童血浆数据的处理效果[37,38,39,40]。
3.4 食物谱进一步改善了代谢组预测
VDAART数据的一个独特之处在于记录了3岁和6岁儿童的食物消费频率。食物频率问卷(FFQ)通常用于记录一段时间内的食品和饮料消费[42,43,44,45]。该问卷由有限的食品和饮料列表组成,其中有不同的选择答案,揭示了在特定时间间隔内消费的典型频率,例如在过去的一年中每周吃西兰花的频率。FFQ有多种形式,如哈佛威利特FFQ[42]和NHANES(国家健康和营养检查调查)FFQ[43,44,45]。在VDAART中,FFQ遵循并略微修改了学龄前儿童87项经验证的FFQ[46]。具体来说,VDAART中的FFQ在36个月季度婴儿随访问卷中作为一个章节出现[39]。随后,我们根据每种记录在案的食物的营养成分,将他们的食物消费频率转换为营养概况。这种转换依赖于FNDDS(美国农业部饮食研究食品和营养数据库)[47]数据库,该数据库对食品和饮料中营养成分的详细含量进行编码。
有了这些饮食信息,我们就可以回答这样一个问题:肠道微生物组成、食物消耗和营养摄入中,哪一个因素对儿童粪便样本和血浆样本的代谢组学特征影响最大? 为了解决这个问题,我们以5种不同的方式对mNODE进行了训练(仅使用食品概况、仅使用营养概况、仅使用微生物组成、仅使用食品概况的微生物组成和仅使用营养概况的微生物组成作为mNODE的输入),然后比较了它们在预测能力方面的差异。在所有预测粪便或血浆样本代谢组学特征的方法中,单独使用食物特征或营养特征的方法产生的性能几乎同样差**(图4)。将营养特征作为额外输入添加到微生物组成中对其性能几乎没有影响,其性能与仅使用微生物组成的性能没有太大差异(图4)**。当不包含营养信息时,由额外的营养信息预测的代谢物的$\bar \rho ( 0.205 ) 略大于 0.198 ,而添加额外的营养信息时, (0.205)略大于0.198,而添加额外的营养信息时, (0.205)略大于0.198,而添加额外的营养信息时,N_{\rho >0.5 } 为 41 ,小于没有添加营养信息时的 49 。类似地,对于血浆样品,有营养谱预测的代谢物的 为41,小于没有添加营养信息时的49。类似地,对于血浆样品,有营养谱预测的代谢物的 为41,小于没有添加营养信息时的49。类似地,对于血浆样品,有营养谱预测的代谢物的\bar \rho ( 0.219 ) 比没有营养谱预测的 0.226 略小,有营养谱预测的 (0.219)比没有营养谱预测的0.226略小,有营养谱预测的 (0.219)比没有营养谱预测的0.226略小,有营养谱预测的N_{\rho > 0.5 }$为32, 比没有营养谱时的28略大。微生物组成和食品概况的结合似乎是最成功的方法,正如在3个指标和2种数据类型(或环境)中始终如一的最佳性能所表明的那样。这表明,个体之间食物消耗的差异可能有助于我们更好地预测代谢组学特征。添加食物概况可能比添加营养概况更有帮助的一个原因是配对样本间营养特征的布雷-柯蒂斯差异远低于食物特征(补充图S2)。
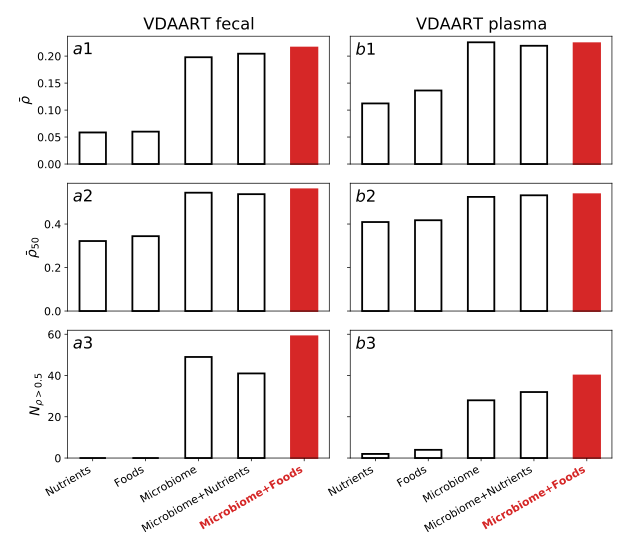
**图4:输入数据类型(微生物组成、食物概况和营养概况)不同组合时mNODE的性能。**使用5种不同的组合:仅食品、仅营养成分、仅微生物成分、含微生物成分的食品和含微生物成分的营养成分。我们采用了3个指标来比较模型的性能:平均SCC $\bar \rho $、前50名平均SCC ρ ˉ 50 \bar \rho_{50} ρˉ50和SCC大于0.5的代谢物的数目 N ρ > 0.5 N_{\rho>0.5} Nρ>0.5。所有数据集按照80/20的比例随机分为训练集和测试集。a. 3岁儿童粪便样本数据的方法表现[37,38,39,40]。b. 方法对3岁儿童血浆样本数据的处理效果[37,38,39,40]。
3.5 推断微生物与代谢物的相互作用
虽然深度学习模型通常能产生更好的预测,因为它们能更好地近似任何函数,但它们仍然缺乏可解释性,因此由于它们的“黑箱”性质,它们在生物学上的见解很少。为了解决这种缺乏可解释性的问题,我们为mNODE提出了一种扰动方法,通过测量基于代谢物浓度对微生物相对丰度等输入扰动的响应的“敏感性”来破译微生物与代谢物之间的关系。 我们的方法与之前开发的LIME(局部可解释的模型不可知论解释)相似,但比LIME更简单[48,49]。为了揭示物种 i i i对代谢物的影响,我们对训练良好的mNODE对物种 i ( x i ) i(x_i) i(xi)的相对丰度进行了少量 Δ x i \Delta x_i Δxi的扰动,重新预测了代谢物的浓度,并测量了与原始预测的偏差(我们将偏差记为 Δ y α \Delta y_{\alpha} Δyα)。我们将代谢产物 α \alpha α对物种 i i i的敏感性定义为 s α i = Δ y α Δ x i s_{\alpha i } = \frac{\Delta y_{\alpha}}{\Delta x_i} sαi=ΔxiΔyα(图5a)。 s α i s_{\alpha i} sαi的符号反映了物种 i i i对代谢物 α \alpha α的影响。例如,$s_{\alpha i} < 0 意味着物种 意味着物种 意味着物种i 的丰度越高,代谢产物的预测浓度越低,这可能意味着物种 的丰度越高,代谢产物的预测浓度越低,这可能意味着物种 的丰度越高,代谢产物的预测浓度越低,这可能意味着物种i 可以消耗代谢产物 可以消耗代谢产物 可以消耗代谢产物\alpha 。同样, 。同样, 。同样,s_{\alpha i} > 0 可能对应于物种 可能对应于物种 可能对应于物种i 的代谢物 的代谢物 的代谢物\alpha 的产生。关于如何计算 的产生。关于如何计算 的产生。关于如何计算s_{\alpha i}$的更多技术细节, 请参见方法部分。
为了验证所提出的敏感性测量是否可以破译微生物-代谢物消耗和生产相互作用,我们首先在图2a1-a3中使用的合成数据上测试了这一想法,并计算了所有微生物-代谢物对的敏感性(图5b)。合成数据非常适合验证敏感性方法,因为我们可以直接将敏感性矩阵(图5b)与微生物消费者-资源模型中的真实消费相互作用(图5c)和生产相互作用(图5d)进行比较。从视觉上很明显,图5c中的许多真实的相互作用在敏感度矩阵(susceptibility matrix)中被正确地显示出来(在图5b中用红色表示)。为了系统地比较敏感度矩阵与真实的消耗相互作用,我们将所有微生物-代谢物对分为**(1)有消耗相互作用和(2)没有根据分类阈值进行消耗相互作用**。只有敏感性低于 s t h r e s s_{thres} sthres的微生物-代谢物对才会被认为是预测的消耗相互作用。降低这样的阈值,只会将敏感性相对较小(即负值远离零)的微生物-代谢物对视为消耗相互作用的预测。我们将阈值从敏感性的最小值逐渐增加到最大值,对每个阈值执行分类任务,计算所有阈值的TP (True-Positive)率和FP (False-Positive)率,并测量ROC (Receiver Operating Characteristic)曲线的AUC (Area Under Curve)。同样的分类程序可以应用于推断生产相互作用,只有大的敏感性值才会被归类为生产相互作用。我们发现,对于合成数据,敏感性可以预测性能良好的消耗相互作用(AUC = 0.95)和性能良好的生产相互作用(AUC = 0.69)。了解生产相互作用的不准确预测是否是由于它们与消费相互作用的重叠(即一种代谢物可以同时被一个物种消耗和产生;更多细节见方法),我们设计了一个MiCRM(微生物消费者-资源模型),该模型具有特定物种的副产物产生,并且在消费和生产相互作用之间没有重叠(更多细节见补充信息)。当生产交互与消费交互不重叠时,生产交互的预测能力几乎等同于消耗交互的预测能力(图S3e)。
我们最终将验证的敏感性方法应用于所有实际数据集,并将所有数据集的敏感性值作为补充数据/表提供。在这里,我们专注于数据集PRISM + NLIBD,因为人类成年人的肠道微生物组已经得到了更广泛的研究。为此,我们将研究重点放在了胆汁酸代谢上,胆汁酸代谢被研究得比较充分[50,51,52,53,54],并被证明与胃肠道癌症[53]和IBD[55,56]等人类胃肠道疾病有关。我们仔细选择了与胆酸盐和鹅脱氧胆酸盐的初级、共轭和次级形式相关的代谢物。 Heinken等人基于肠道微生物群的基因组对800多种肠道微生物菌株的胆汁酸代谢进行了系统评估[54]。为了检验基于我们的易感性矩阵推断的相互作用是否具有基因组证据,我们搜索了一些具有大易感性绝对值的微生物-代谢物对。拟杆菌vulgatus ATCC 8482对胆酸盐和鹅脱氧胆酸盐有较高的阳性敏感性。这一点得到了基因组证据的支持,即普通拟杆菌ATCC 8482含有bsh(胆盐水解酶)基因,该基因编码bsh酶,负责将偶联的初级胆汁酸解结为初级胆汁酸胆酸盐和鹅脱氧胆酸盐[50,54]。同样,毛螺科细菌5 1 57FAA对脱氧胆酸盐和石胆酸盐具有较大的正敏感性,其基因组中存在bai通路,可将初级胆汁酸胆酸盐和鹅脱氧胆酸盐分别转化为次级胆汁酸脱氧胆酸盐和石胆酸盐[54]。值得注意的是,Lachnospiraceae细菌中其他菌株对脱氧胆酸盐和石胆酸盐的敏感性值并不大,基因组证据表明Lachnospiraceae细菌5 1 63F AA和Lachnospiraceae细菌8 1 57F AA基因组中不存在bai通路[54]。敏感性值接近于零可能意味着微生物和代谢物之间没有相互作用。例如,与易感矩阵中的其他条目相比,唾液链球菌(Streptococcus salivarius)的所有易感度都更接近于零,其基因组中确实不包含与胆汁酸代谢相关的基因[54]。
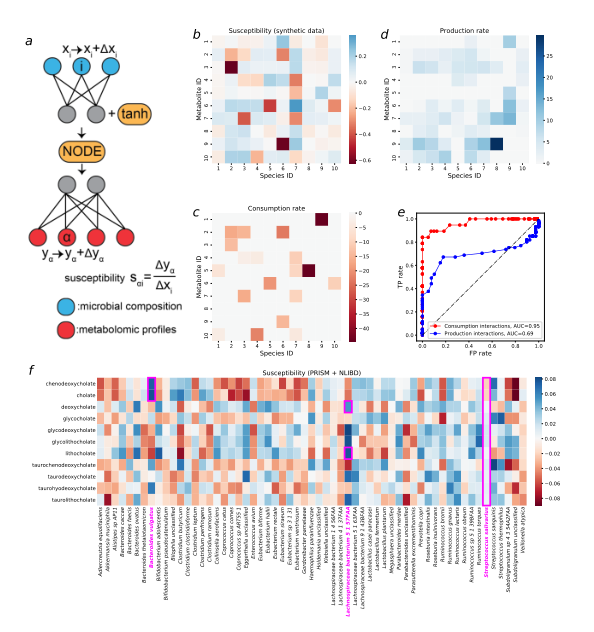
图5:利用代谢产物浓度对经过良好训练的mNODE微生物组成的敏感性,在合成和真实数据(PRISM+NLIBD)上推断微生物与代谢产物的相互作用。 a. 代谢物浓度 α ( y α ) \alpha(y_{\alpha}) α(yα)对物种 i ( x i ) i (x_i) i(xi)相对丰度的敏感性,记为 s α i s_{\alpha i} sαi,定义为代谢物浓度变化 α ( Δ y α ) \alpha (\Delta y_{\alpha}) α(Δyα)与物种相对丰度的扰动量 i ( Δ x i ) i(\Delta x_i) i(Δxi)之比。**b. 图2a1-a3中使用的合成数据中所有微生物-代谢物对的敏感性值。c. 合成数据中的真值消耗矩阵和相应的速率。**所有的消耗率都显示为负值,以便与图b进行比较。**d. 合成数据中的真值生产矩阵和相应的速率。**关于如何获得生产矩阵的详细信息可以在补充信息中找到。e基于TP率和FP率的ROC(受试者工作特征)曲线,通过设置不同的相互作用分类敏感性阈值获得TP率和FP率。f. 图3a1-a3中PRISM + NLIBD[36]中所有微生物代谢物对的敏感性值。
4. 讨论
了解微生物群落的功能需要对其代谢活动进行分析。代谢组学(如LC-MS)应用于许多微生物群落,通常描述微生物代谢的最终产物;未完全消耗的代谢物和微生物进一步产生的代谢物共同构成了可在非靶向代谢组学中测量的代谢组。由于昂贵的设备和费力的人工管理,代谢组学比宏基因组学或16S测序要昂贵得多。
能够利用微生物组成预测代谢物水平的计算方法,是一种更经济有效的方法,可以量化代谢物浓度在样品中的分布。此外,这样的模型可能有助于我们更好地理解微生物和代谢物的相互作用。在这项研究中,我们开发了mNODE方法,它比几乎所有以前开发的方法都能产生更好的代谢组预测。此外,我们通过将食品概况与微生物组成作为mNODE的输入。最后,我们发现mNODE通过敏感性分析在合成数据和人类数据集(PRISM+NLIBD)上准确地推断出微生物与代谢物的相互作用。在未来,如果有更多的组学数据,如宏转录组和宏蛋白质组,它们也可以很容易地作为mNODE的输入,以研究每种数据类型在预测代谢组中的相对重要性。
NODE通过**“展开unrolling”**近似动力系统一阶时间导数的隐式层,将过去120年来发展良好的ODE求解技术与深度学习相结合。正因为如此,研究人员对使用NODE架构解决动态系统问题的可能性越来越感兴趣。例如,最近Dutta等人表明,NODE可以为不同流体动力学的各种演化问题生成解,并进一步提供了外推的良好潜力[33]。另一种尝试是使用NODE来学习基于传统生态模型生成的时间序列数据的生态和进化过程[57]。微生物群落是一个动态系统,其中微生物主要通过代谢产物的消耗和副产物代谢产物的产生来相互作用[58,34]。定期提供给微生物群落的营养物质(如肠道微生物组饮食中的膳食纤维)或连续提供给微生物群落的营养物质(如趋化剂中的营养通量)可被微生物消耗并通过微生物的代谢转化为其他副产物。实验测量的不同时间微生物群落样品宏基因组和代谢组可以看作是相应时间微生物丰度和代谢物浓度的谱图。
因此,我们期望利用具有正确输入数据类型的NODE框架来确定微生物群落动态及其代谢将产生更好的性能。在许多输入数据类型中,我们认为饮食/营养信息是重要的一种。然而,目前通过FFQ记录饮食信息的方法存在一些局限性[59]。一方面,由于FFQ只调查了食用一种食物的频率,而不是每餐食用每种食物的数量,因此在消费量上出现了系统误差。当然,对于FFQ来说,记录每顿饭的精确食物消费信息是具有挑战性的,因为它通常会询问一段时间内的习惯饮食一段很长的时间,如一周、一个月或一年每餐食物摄入量的数字记录可能会减轻这种错误[59]。另一方面,FFQ缺乏关于食品品牌和食品制备的详细信息。由于有限的营养项目和缺乏详细的营养成分,当FFQs中的食物概况转换为营养概况时,也会出现类似的问题。例如,转换数据库中的膳食纤维包含所有类型的纤维。但是不同的微生物对不同纤维和多糖的消耗能力和速率是不同的[60,61]。对一组全面的食物进行详细的代谢组学分析可能对精确营养的进步很重要[62]。
我们注意到,无论采用何种计算方法,从肺部[23]和土壤[41]收集的微生物群落的预测精度都高于人类肠道微生物组(即PRISM + NLIBD[36]和VDAART[37,38,39,40])。肺样本的平均Spearman相关系数$\bar \rho $ (mNODE为0.526,MiMeNet为0.402)远高于VDAART粪便样本(mNODE为0.198,MiMeNet为0.192)。**这表明,一些微生物组的代谢组谱比其他微生物组的代谢组谱更难预测,我们怀疑这是由于输入维度(如微生物分类群的数量)和输出维度(如代谢组谱中代谢物的数量)之间的比例存在差异。**例如,对于肺样本[23],微生物分类群的数量(1119)远远大于代谢物的数量(168)。作为对比,在PRISM + NLIBD的粪便样本中,微生物类群的数量(200)远少于代谢物的数量(8848)。这一比较显示了推断人类肠道微生物组的代谢组谱的复杂性。人类肠道微生物组的两个数据集仍然具有不同的预测性能;PRISM + NLIBD的平均Spearman相关系数 ρ ˉ \bar \rho ρˉ(mNODE为0.294)略高于VDAART粪便样品的平均Spearman相关系数$\bar \rho $(mNODE为0.198)。我们认为这可能是由于在VDAART中调查的儿童可能没有像PRISM + nlibd中调查的成人那样具有完善的肠道微生物组。
值得注意的是,我们的mNODE方法非常通用,这使得它很容易应用于其他生物学问题,其中系统的动力学起着至关重要的作用。例如,可以应用该模型框架从宏基因组等组学数据中预测一种组学数据类型,如宏转录组和宏蛋白质组。对于许多细菌,如金黄色葡萄球菌和枯草芽孢杆菌,在基因的表达DNA转化为mRNAs及其进一步转化为蛋白质是一个受到严格调控的动态过程[63]。由于蛋白质水平比基因组信息更能反映微生物的代谢活动,如果我们能设计一个模型来预测宏基因组的宏蛋白质组,我们可能离揭示微生物群落的功能更近了一步。此外,微生物基因组与其蛋白质组之间的这种联系可能使我们能够预测微生物的表型,如它们在不同环境中的特定生长率(如果环境数据可用)。
5. 方法
5.1 数据集
**PRISM + NLIBD粪便样本。**该数据集由一项关于IBD患者粪便微生物组和代谢组样本的研究报告[36]。该研究涉及两个队列。第一个个体横断面队列是由PRISM (MGH IBD研究前瞻性登记)研究收集的。该队列包括68名克罗恩病(CD)患者,53名溃疡性结肠炎(UC)患者和34名健康对照。第二个研究队列(NLIBD/LLDeep)是在荷兰独立收集的,包括20名CD患者,23名UC患者和22名健康对照。按照相同的方案收集了两个队列的粪便样本425,然后以相同的方式对微生物组和代谢组进行了描述和分析。通过四种LC-MS(液相色谱-质谱)代谢组学方法,共获得了200个微生物类群,8848个独特的代谢物。在8848种独特的代谢物中,有466种被注释。在所有机器学习任务中,PRISM中与个体相关的所有数据(微生物组成和代谢组学谱)都被用作训练集,外部验证队列NLIBD/LLDeep被用作测试集。
**囊性纤维化肺样本。**一项研究收集了172名患者的所有肺痰样本,研究化学梯度如何驱动微生物组结构的转变和代谢物产生的模式[23]。通过16S rRNA基因测序确定了1119种微生物特征,并通过液相色谱-质谱(LC-MS/MS)和气相色谱-质谱(GC-MS)代谢组学生成了168种代谢物谱。对于所有的机器学习任务,使用80/20的训练测试分割,随机状态设置为42,以保证公平的比较。
**沙漠土壤生物结皮样品。**Swenson等人描述了四个演替阶段的生物地壳是如何被弄湿的,并在每个阶段的五个时间点进行采样[41]。采用散弹枪宏基因组测序方法测定了466个优势类群的单拷贝基因标记。液相色谱-质谱(LC/MS)土壤代谢组学鉴定出85种代谢物在湿润和演替阶段至少变化了两倍。所有模型都使用80/20训练测试分割,随机状态设置为42。
**VDAART儿童粪便样本、血浆样本和FFQ数据。**VDAART(维生素D产前哮喘减少试验)是一项产前补充维生素D以预防哮喘和喘息的试验[37,38]。收集340例3岁儿童的粪便和血浆样本。16S rRNA基因测序鉴定了粪便样品中209个微生物类群的微生物组谱[40]。用Skewer进行引物和接头的修剪。使用Qiime2进行嵌合体检查和过滤[64]。读段使用Qiime2[65]中实现的DADA2去噪。如前所述,粪便和血液样本的代谢组学特征是通过使用超高效液相色谱-质谱法(UPLC-LC/MS)生成的[66,40,39]。已知化学实体的鉴定是基于与纯化标准品的代谢组学库条目的比较,基于色谱性质和质谱。粪便样品中检测到1298种代谢物,血液样品中检测到1064种代谢物。此外,我们从36个月季度婴儿随访问卷中提取了他们的饮食信息,该问卷记录了儿童食用食物的频率[39]。研究人员对儿童饮食进行了评估,父母完成了一份修改版的半定量的87项食物频率问卷(FFQ),该问卷先前在学龄前儿童中得到了验证[46]。食物频率表可以使用FNDDS(美国农业部的饮食研究食物和营养数据库)进一步转换为营养概况,该数据库用于将消耗的食物和饮料转换为克数并确定其营养价值。所有340个孩子被分成火车组或测试组,比例为80/20,随机状态组为42。
5.2 mNODE模型
NODE(神经常微分方程)是一种结合显式层和隐式层的深度学习方法,其中隐藏层的状态由普通方程描述。我们的mNODE在中间引入NODE作为一个模块。
- 数据处理:CLR(中心对数比)转换应用于微生物丰度和代谢物浓度。
- 模型细节:3连接模块的体系结构包括: (1)一个完全连接层映射的输入(如微生物组成)与维度 N h N_h Nh紧随其后隐藏层的激活函数,(2)神经常微分方程模块[30]一阶时间导数的近似由与隐层维度 N h N_h Nh一样的one-hidden-layer MLP实现, 和(3)一个完全连接隐藏层的映射到输出(即代谢组配置文件)。假设使用权重参数㼿进行L2正则化以防止过拟合。
- 训练方法:使用Adam优化器[67]进行梯度下降。如果验证/测试集上的损失在过去20个epoch内开始增加,则训练停止。判断增加的判据是看过去20个迭代的损失增加的次数(即第i历元的损失减去第i-1历元的损失大于0)是否大于12。
- 激活函数:双曲正切函数tanh。
- 超参数选择:根据训练集上5次交叉验证的结果 (即, 平均Spearman的秩相关系数)选择两个超参数: 隐藏层的维度 N h N_h Nh和 L 2 L_2 L2惩罚与权重参数$\lambda 。 。 。N_h 从 [ 32 , 64 , 128 ] 中选取, 从[32,64,128]中选取, 从[32,64,128]中选取,\lambda 从 从 从[10{-4},10{-3},10^{-2}]$中选取。
5.3 通过敏感性推断微生物与代谢物的相互作用
训练有素的mNODE以所有物种的相对丰度(物种 i i i的相对丰度用 x i x_i xi表示)作为输入,并生成代谢物浓度的预测(代谢物 α \alpha α的浓度用 y α y_{\alpha} yα表示)。对于训练集中的样本 m m m,将所有 i i i的 x i ( m ) x_i^{(m)} xi(m)作为训练后的mNODE的输入向量,mNODE可以预测所有代谢物的浓度 y α ( m ) y_{\alpha}^{(m)} yα(m)。为了研究物种 i i i对特定样本 m m m的代谢物$\alpha 的影响,我们将 的影响,我们将 的影响,我们将x^{(m)}i 设置为物种 设置为物种 设置为物种i 在样本 在样本 在样本\bar x{i} 中相对丰度的平均值,同时保持 中相对丰度的平均值,同时保持 中相对丰度的平均值,同时保持x^{(m) }_{j \neq i} 的值不变,从而对 的值不变,从而对 的值不变,从而对x^{(m)}_i 进行扰动。因此,物种 进行扰动。因此,物种 进行扰动。因此,物种i$的扰动量为 Δ x i ( m ) = x ˉ i − x i ( m ) \Delta x_i^{(m)} = \bar x_i - x_i^{(m)} Δxi(m)=xˉi−xi(m) 。这个微生物相对丰度的扰动载体被提供给经过训练的mNODE,以重新生成代谢物浓度 y α ( m ) + Δ y α ( m ) y_{\alpha}^{(m)}+\Delta y_{\alpha}^{(m)} yα(m)+Δyα(m) , 其中 Δ y α ( m ) \Delta y_{\alpha}^{(m)} Δyα(m) 是当mNODE使用扰动输入向量时与mNODE使用未扰动输入向量时新预测的代谢物浓度的偏差。对于样品 m m m,代谢产物$\alpha 对物种 对物种 对物种i$的敏感性可定义为 s α i ( m ) = Δ y α ( m ) Δ x i ( m ) s_{\alpha i }^{(m)} = \frac{\Delta y_{\alpha}^{(m)}}{\Delta x_i^{(m)}} sαi(m)=Δxi(m)Δyα(m)。为了适当地考虑所有训练样本,我们对样本的敏感性进行平均,得到代谢产物 α \alpha α对物种 i i i的总体敏感性 s α i = ∑ m s α i ( m ) N t r a i n s_{\alpha i}=\frac{\sum_ms_{\alpha i}^{(m)}}{N_{train}} sαi=Ntrain∑msαi(m),其中 N t r a i n N_{train} Ntrain为训练集中的样本数量。
5.4 统计数据
为了计算整个研究中的相关系数,我们使用了Spearman的秩相关系数。无论我们在哪里使用P值,我们都在方法中解释了我们是如何计算它们的,因为对于研究中的所有此类测量,我们从头开始计算相关的零分布。所有统计测试均使用Python编程语言(版本3.7.3)、Julia编程语言(版本1.6.2)和Jupyter Notebook(版本6.1)中的标准数值和科学计算库进行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









