






广义线性模型glmmTMB包
广义线性混合模型glmmTMB(generalized linear mixed models)官方文档: https://glmmtmb.github.io/glmmTMB/articles/mcmc.html
Mollie E. Brooks, Kasper Kristensen, Koen J. van Benthem, Arni Magnusson, Casper W. Berg, Anders Nielsen, Hans J. Skaug, Martin Maechler and Benjamin M. Bolker (2017). glmmTMB Balances Speed and Flexibility Among Packages for Zero-inflated Generalized Linear Mixed Modeling. The R Journal, 9(2), 378-400. https://glmmtmb.github.io/glmmTMB/index.html
中文博客(R语言glmnet包拟合广义线性模型): https://blog.csdn.net/qq_27390023/article/details/122656396
截止2022年8月:累计引用3840次。
文章目录
1. 简介与快速开始
glmmTMB是一个建立在 Template Model Builder(https://github.com/kaskr/adcomp)自动分化引擎上的R包,用于拟合广义线性混合模型及其延伸。主要特点包括:
- 包括的分布:高斯分布、二项分布、β-二项分布、泊松分布、负二项分布(NB1和NB2参数化)、Conway-Maxwell-Poisson、广义的泊松、γ、β和Tweedie分布;以及零截断泊松、零截断Conway-Maxwell-Poisson,广义泊松、广义负二项分布。
?family glmmTMB提供了现有的列表,包含参数化的详情。 - 连接的函数:log, logit, probit, complementary log-log, inverse, identity
- 具有固定和随机效应成分的零膨胀;基于截断 Poisson/NB的栏架模型。
- 单个或多个(嵌套或交叉)随机效果
- offsets
- 分散的固定效应模型
- 对角、复合对称或非结构化随机效应的方差-协方差矩阵;一阶自回归(AR1)方差结构
为了有效使用glmmTMB,你应该充分熟悉广义线性模型(generalized linear mixed models,GLMMs), 而这又需要你熟悉:(i)广义线性模型(例如逻辑回归、二项回归、泊松回归的特殊形式);(ii) "现代"混合模型(通过最大化边际似然而不是操作平方和来工作)。关于广义线性模型的详情可参考glmmTMB官方文档。
为了用glmmTMB拟合一个模型,你需要:
- 指定条件效应模型(通过标准的R公式符号)。
- 指定随机效应模型,在
nlme和lme4包通用的符号中。 - 通过指定
family来选择错误分布。通常可以指定binomial、gaussian、poisson和Gamma等。
2. 准备工作
加载需要的包:
library("glmmTMB")
library("bbmle") ## for AICtab
library("ggplot2")
## cosmetic
theme_set(theme_bw()+ theme(panel.spacing=grid::unit(0,"lines")))
来自Zuur et al. (2009)和最终来自Roulin and Bersier(2007)的数据,量化了在提供食物的父母到来之前不同巢穴中猫头鹰(猫头鹰雏鸟)之间的数量,这是食物处理(被剥夺或饱食)、父母的性别和到达时间的函数。记录来自巢的呼叫的总数量,以及总孵化数量,后者被用作允许使用泊松响应的偏移量。
> print(Owls[0:5, ])
Nest FoodTreatment SexParent ArrivalTime SiblingNegotiation BroodSize NegPerChick logBroodSize
1 AutavauxTV Deprived Male 22.25 4 5 0.8 1.609438
2 AutavauxTV Satiated Male 22.38 0 5 0.0 1.609438
3 AutavauxTV Deprived Male 22.53 2 5 0.4 1.609438
4 AutavauxTV Deprived Male 22.56 2 5 0.4 1.609438
5 AutavauxTV Deprived Male 22.61 2 5 0.4 1.609438
> print(colnames(Owls))
[1] "Nest" "FoodTreatment" "SexParent" "ArrivalTime"
[5] "SiblingNegotiation" "BroodSize" "NegPerChick" "logBroodSize"
> print(dim(Owls))
[1] 599 8
> print(summary(Owls))
Nest FoodTreatment SexParent ArrivalTime SiblingNegotiation BroodSize
Oleyes : 52 Deprived:320 Female:245 Min. :21.71 Min. : 0.00 Min. :1.000
Montet : 41 Satiated:279 Male :354 1st Qu.:23.11 1st Qu.: 0.00 1st Qu.:4.000
Etrabloz : 34 Median :24.38 Median : 5.00 Median :4.000
Yvonnand : 34 Mean :24.76 Mean : 6.72 Mean :4.392
Champmartin: 30 3rd Qu.:26.25 3rd Qu.:11.00 3rd Qu.:5.000
Lucens : 29 Max. :29.25 Max. :32.00 Max. :7.000
(Other) :379
NegPerChick logBroodSize
Min. :0.000 Min. :0.000
1st Qu.:0.000 1st Qu.:1.386
Median :1.200 Median :1.386
Mean :1.564 Mean :1.439
3rd Qu.:2.500 3rd Qu.:1.609
Max. :8.500 Max. :1.946
##Nest FoodTreatment SexParent ArrivalTime SiblingNegotiation(兄弟姐妹之间的谈判)
#BroodSize:窝的大小。
#NegPerChick:每只雏鸟之间的协商/谈判。
#logBroodSize:窝大小的记录。
由于重复测量相同的巢,巢被用作一种随机效应。该模型可表示为零膨胀广义线性混合模型(zero-inflated generalized linear mixed model, ZIGLMM)。
数据集的各种小操作:(1)通过每只雏鸟的平均协商来重新排序鸟巢,以达到绘图的目的;(2)添加logBroodSize变量(用于offset);(3)重命名响应变量,缩写其中一个输入变量。
Owls <- transform(Owls,
Nest=reorder(Nest,NegPerChick),
NCalls=SiblingNegotiation,
FT=FoodTreatment)
在构建模型之前,我们应该探索数据,例如通过各种方式来绘图,但是这是关于glmmTMB的教程,而不是数据可视化教程…… 此处仅进行基本展示:
p1 <- ggplot(Owls,aes(x=FT, y=NCalls)) +
geom_point()+
geom_violin(alpha=0.5) +
geom_boxplot(width=0.2)
print(p1)
p2 <- ggplot(Owls,aes(x=ArrivalTime, y=NCalls)) +
geom_point()
print(p2)
p3 <- ggplot(Owls,aes(x=SexParent, y=NCalls)) +
geom_point()+
geom_violin(alpha=0.5) +
geom_boxplot(width=0.2)
print(p3)
p4 <- ggplot(Owls,aes(x=log(BroodSize), y=NCalls)) +
geom_point()
print(p4)
p5 <- ggplot(Owls,aes(x=Nest, y=NCalls)) +
geom_point() +
theme(axis.text.x = element_text(size=10, angle=30, hjust = 1, family="serif"))
print(p5)
pdf("Owls_show.pdf", width=16, height=4)
img = cowplot::plot_grid(p1, p2, p3, p4, p5, nrow = 1, rel_widths = c(4,4,4,4,8))
print(img)
dev.off()
现在开始拟合模型:
最基础的glmmTMB拟合——将具有单个零膨胀参数的零膨胀泊松模型用于所有的观测(ziformula~1)。(排除零通胀是glmmTMB的默认值:要明确地排除它,请使用ziformula~0)
**补充:**Zero-inflated models are applied to situations in which target data has relatively many of one value, usually zero, to go along with the other observed values. They are two-part models, a logistic model for whether an observation is zero or not, and a count model for the other part.
fit_zipoisson <- glmmTMB(NCalls~(FT+ArrivalTime)*SexParent+
offset(log(BroodSize))+(1|Nest),
data=Owls,
ziformula=~1,
family=poisson)
结果如下:
> summary(fit_zipoisson)
Family: poisson ( log )
Formula: NCalls ~ (FT + ArrivalTime) * SexParent + offset(log(BroodSize)) + (1 | Nest)
Zero inflation: ~1
Data: Owls
AIC BIC logLik deviance df.resid
4015.6 4050.8 -1999.8 3999.6 591
Random effects:
Conditional model:
Groups Name Variance Std.Dev.
Nest (Intercept) 0.1294 0.3597
Number of obs: 599, groups: Nest, 27
Conditional model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.53995 0.35656 7.123 1.05e-12 ***
FTSatiated -0.29111 0.05961 -4.884 1.04e-06 ***
ArrivalTime -0.06808 0.01427 -4.771 1.84e-06 ***
SexParentMale 0.44885 0.45002 0.997 0.319
FTSatiated:SexParentMale 0.10473 0.07286 1.437 0.151
ArrivalTime:SexParentMale -0.02140 0.01835 -1.166 0.244
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Zero-inflation model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.05753 0.09412 -11.24 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
2.1 使用零膨胀负二项分布(NB2)来拟合
我们还可以尝试标准的零膨胀负二项分布模型,默认是"NB2"参数(
v
a
r
i
a
n
c
e
=
μ
(
1
+
μ
/
k
)
variance=\mu(1+\mu / k)
variance=μ(1+μ/k)。使用R中定义的家族(Poisson, binomial, Gaussian), 你可以像在?glm中指定它们一样,来指定家族函数自身,或者家族函数调用的结果:例如family="poisson", family=poisson, family=poisson(), and family=poisson(link="log")都是允许的并且等价的。某些基础R中没有定义的额外家族(包括nbinom2和nbinom1)可以被用相同的方式指定。另外,对于glmmTMB中实现的但是glmmTMB中没有提供函数的家族,你应该应该family为一个包括family和link元素的列表,例如:family=list(family="nbinom2",link="log")。(为了能够从拟合中检索Pearson(方差比例)残差,您还需要指定一个方差variance分量;可查看?family_glmmTMB)。
fit_zinbinom <- update(fit_zipoisson,family=nbinom2)
结果为(AIC和BIC的解释:https://zhuanlan.zhihu.com/p/142489599):
> print(summary(fit_zinbinom))
Family: nbinom2 ( log )
Formula: NCalls ~ (FT + ArrivalTime) * SexParent + offset(log(BroodSize)) + (1 | Nest)
Zero inflation: ~1
Data: Owls
AIC BIC logLik deviance df.resid
3418.3 3457.8 -1700.1 3400.3 590
Random effects:
Conditional model:
Groups Name Variance Std.Dev.
Nest (Intercept) 0.06029 0.2455
Number of obs: 599, groups: Nest, 27
Dispersion parameter for nbinom2 family (): 2.3
Conditional model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.07026 0.76413 4.018 5.87e-05 ***
FTSatiated -0.40904 0.13544 -3.020 0.00253 **
ArrivalTime -0.09087 0.03092 -2.939 0.00329 **
SexParentMale -0.39679 0.97448 -0.407 0.68388
FTSatiated:SexParentMale 0.16240 0.16278 0.998 0.31842
ArrivalTime:SexParentMale 0.01315 0.03943 0.334 0.73873
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Zero-inflation model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.2782 0.1223 -10.45 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
>
2.2 使用NB1来拟合
另外,我们还可以使用NB1拟合(方差为
ϕ
μ
\phi \mu
ϕμ)。
fit_zinbinom1 <- update(fit_zipoisson,family=nbinom1)
结果为:
> print(summary(fit_zinbinom1))
Family: nbinom1 ( log )
Formula: NCalls ~ (FT + ArrivalTime) * SexParent + offset(log(BroodSize)) + (1 | Nest)
Zero inflation: ~1
Data: Owls
AIC BIC logLik deviance df.resid
3350.8 3390.3 -1666.4 3332.8 590
Random effects:
Conditional model:
Groups Name Variance Std.Dev.
Nest (Intercept) 0.1384 0.3721
Number of obs: 599, groups: Nest, 27
Dispersion parameter for nbinom1 family (): 4.95
Conditional model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.71401 0.83484 4.449 8.64e-06 ***
FTSatiated -0.90691 0.13989 -6.483 9.00e-11 ***
ArrivalTime -0.11883 0.03422 -3.472 0.000516 ***
SexParentMale 0.40633 1.05342 0.386 0.699702
FTSatiated:SexParentMale 0.26146 0.17400 1.503 0.132930
ArrivalTime:SexParentMale -0.01894 0.04326 -0.438 0.661557
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Zero-inflation model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.3594 0.3486 -6.767 1.31e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
2.3 将log(brood_size)作为偏移量
放松呼叫总数与窝数严格成比例的假设(即使用log(brood_size)),将后者作为偏移量:
fit_zinbinom1_bs <- update(fit_zinbinom1,
. ~ (FT+ArrivalTime)*SexParent+
BroodSize+(1|Nest))
结果为:
> print(fit_zinbinom1_bs)
Formula: NCalls ~ FT + ArrivalTime + SexParent + BroodSize + (1 | Nest) +
FT:SexParent + ArrivalTime:SexParent
Zero inflation: ~1
Data: Owls
AIC BIC logLik df.resid
3349.603 3393.555 -1664.801 589
Random-effects (co)variances:
Conditional model:
Groups Name Std.Dev.
Nest (Intercept) 0.3607
Number of obs: 599 / Conditional model: Nest, 27
Dispersion parameter for nbinom1 family (): 4.91
Fixed Effects:
Conditional model:
(Intercept) FTSatiated ArrivalTime SexParentMale
4.2895 -0.9039 -0.1194 0.4171
BroodSize FTSatiated:SexParentMale ArrivalTime:SexParentMale
0.1982 0.2599 -0.0192
Zero-inflation model:
(Intercept)
-2.314
我们进行的每一次改变都可以改进拟合——改变分布提升幅度最大,而改变窝大小的作用左右轻微的变化(1 AIC unit)。
> AICtab(fit_zipoisson,fit_zinbinom,fit_zinbinom1,fit_zinbinom1_bs)
dAIC df
fit_zinbinom1_bs 0.0 10
fit_zinbinom1 1.2 9
fit_zinbinom 68.7 9
fit_zipoisson 666.0 8
2.4 Hurdle models(栅栏模型)
与零膨胀模型相比,栅栏模型将零计数和非零结果视为两个完全独立的类别,而不是将零计数结果视为结构零和抽样零的混合。
glmmTMB包含截断泊松和负二项式族,因此可以适合栅栏模型。
fit_hnbinom1 <- update(fit_zinbinom1_bs,
ziformula=~.,
data=Owls,
family=truncated_nbinom1)
结果为:
> print(summary(fit_hnbinom1))
Family: truncated_nbinom1 ( log )
Formula: NCalls ~ FT + ArrivalTime + SexParent + BroodSize + (1 | Nest) +
FT:SexParent + ArrivalTime:SexParent
Zero inflation: ~.
Data: Owls
AIC BIC logLik deviance df.resid
3291.8 3366.5 -1628.9 3257.8 582
Random effects:
Conditional model:
Groups Name Variance Std.Dev.
Nest (Intercept) 0.03396 0.1843
Number of obs: 599, groups: Nest, 27
Zero-inflation model:
Groups Name Variance Std.Dev.
Nest (Intercept) 0.8478 0.9208
Number of obs: 599, groups: Nest, 27
Dispersion parameter for truncated_nbinom1 family (): 3.27
Conditional model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.62750 0.76987 4.712 2.46e-06 ***
FTSatiated -0.32851 0.12604 -2.606 0.00915 **
ArrivalTime -0.06940 0.03061 -2.268 0.02335 *
SexParentMale 0.97923 0.96838 1.011 0.31192
BroodSize 0.07388 0.04535 1.629 0.10330
FTSatiated:SexParentMale 0.06794 0.15453 0.440 0.66017
ArrivalTime:SexParentMale -0.04126 0.03965 -1.041 0.29795
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Zero-inflation model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -5.41108 2.24298 -2.412 0.01585 *
FTSatiated 1.83269 0.34745 5.275 1.33e-07 ***
ArrivalTime 0.21911 0.08470 2.587 0.00968 **
SexParentMale -2.09849 3.01009 -0.697 0.48571
BroodSize -0.46633 0.17773 -2.624 0.00869 **
FTSatiated:SexParentMale 0.28656 0.47136 0.608 0.54322
ArrivalTime:SexParentMale 0.05706 0.11710 0.487 0.62606
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
比较AIC:
> AICtab(fit_zipoisson,fit_zinbinom,
+ fit_zinbinom1,fit_zinbinom1_bs,
+ fit_hnbinom1)
dAIC df
fit_hnbinom1 0.0 17
fit_zinbinom1_bs 57.8 10
fit_zinbinom1 59.0 9
fit_zinbinom 126.5 9
fit_zipoisson 723.9 8
2.5 采样时间
为了获得glmmTMB相对于lme4(R语言中最常用的混合模型包,https://github.com/lme4/lme4/),我们尝试了一些标准问题,通过克隆原始数据集(复制多个副本并将它们粘在一起)来扩大数据集。
图1显示了重复 Contraception(避孕)数据集1到40次的结果(1934个观察结果,随机效应分组水平为60个水平)。glmmADMB足够慢(单个数据副本约1分钟),所以我们没有尝试复制很多。对于这个问题,glmmTMB平均比glmer快2.3倍。
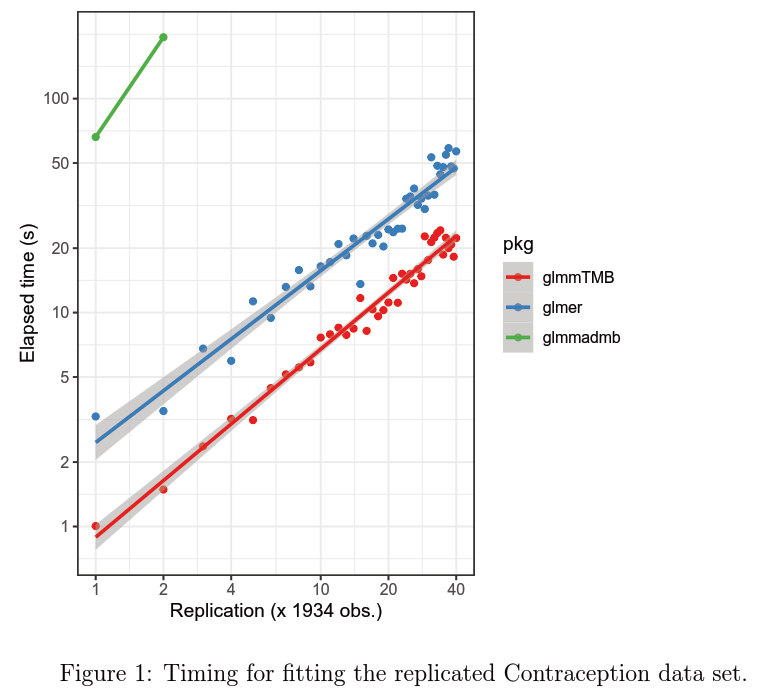
图2显示了InstEval数据集的等效计时,尽管在本例中,由于原始数据集很大(73421个观测结果),我们对数据集进行子采样,而不是克隆它:在本例中,优势是相反的,lmer大约快5倍。
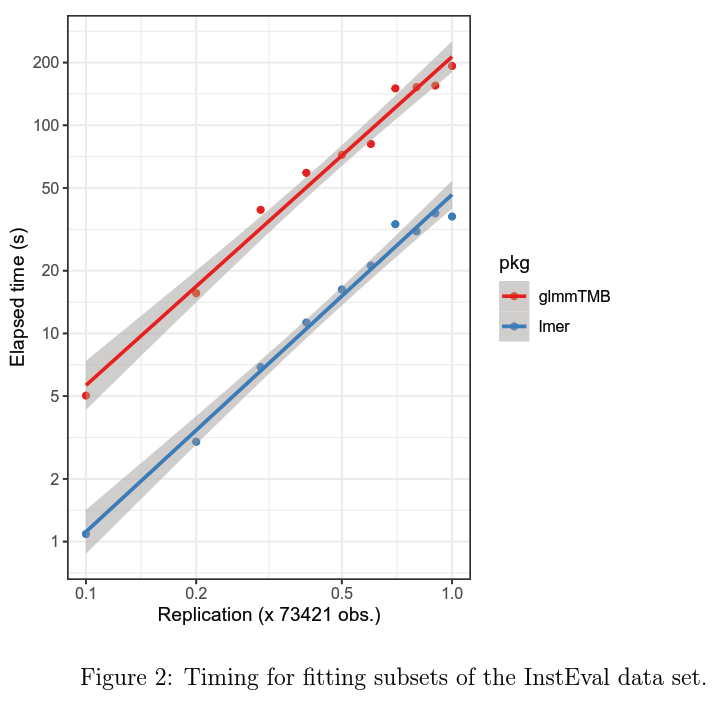
总的来说,我们预计glmmTMB相对于lme4的优势是:(1)更大的灵活性(零通胀等);(2)对于具有大量“顶级”参数(固定效应加随机效应方差-协方差参数)的GLMMs(广义线性模型),速度更快。相比之下,lme4对于LMMs(线性混合模型)应该更快(对于最大速度,您可能想要检查Julia的MixedModels.jl包);Lme4较为成熟,目前对模型结果的诊断检测和方法更加丰富,包括下游的包。

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









