







什么是检索增强的生成模型
LLM 固有的局限性
- LLM 的知识不是实时的
- LLM 可能不知道你私有的领域/业务知识
检索增强生成
RAG(Retrieval Augmented Generation)顾名思义,通过检索的方法来增强生成模型的能力。
类比:你可以把这个过程想象成开卷考试。让 LLM 先翻书,再回答问题。
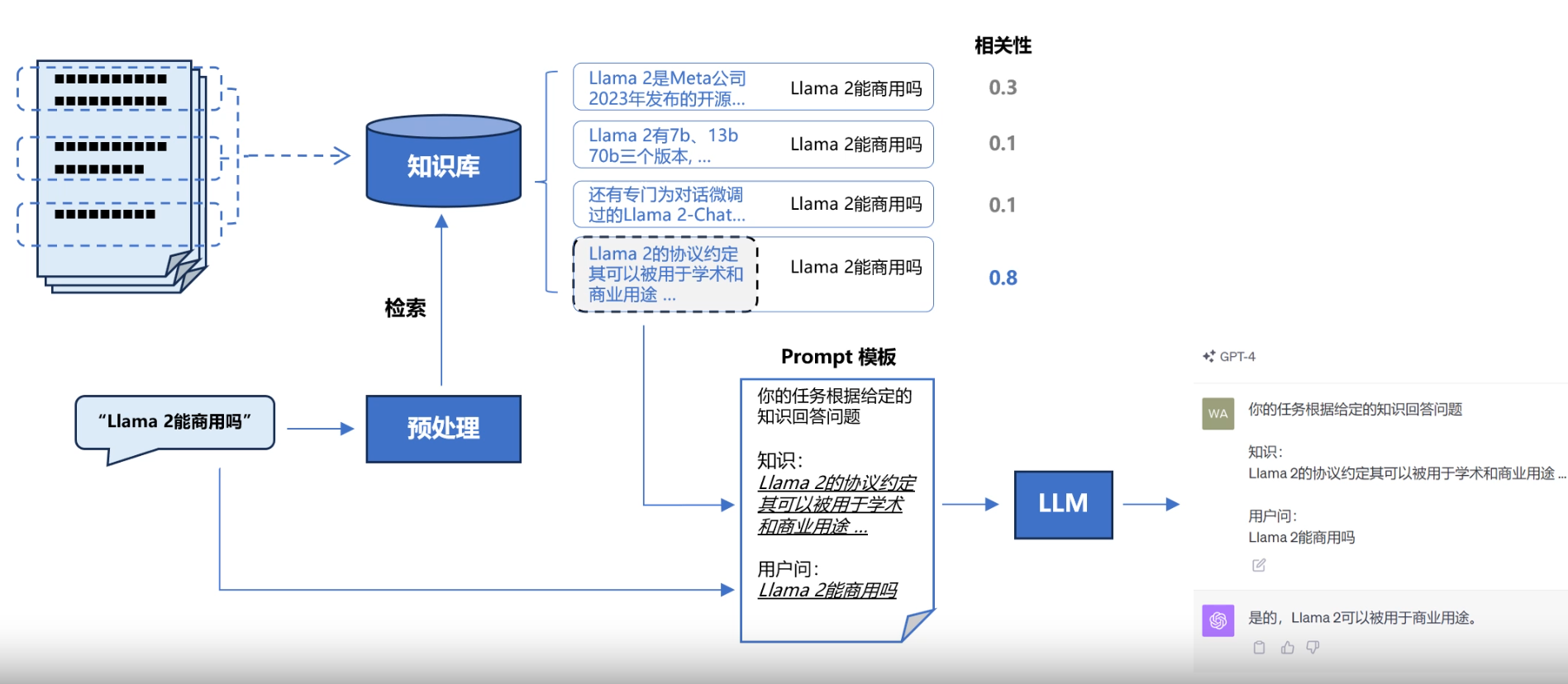
RAG 系统的基本搭建流程
搭建过程:
-
文档加载,并按一定条件切割成片段
-
将切割的文本片段灌入检索引擎
-
封装检索接口
-
构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
RAG Pipeline 初探
user_query = "how many parameters does llama 2 have?"
# 1. 检索
search_results = search(user_query, 2)
# 2. 构建 Prompt
prompt = build_prompt(prompt_template, context=search_results, query=user_query)
print("===Prompt===")
print(prompt)
# 3. 调用 LLM
response = get_completion(prompt)
print("===回复===")
print(response)
===Prompt===
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
已知信息:
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.§
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based onour human evaluations for helpfulness and safety, may be a suitable substitute for closed source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
用户问:
how many parameters does llama 2 have?
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
===回复===
Llama 2有7B, 13B和70B参数的变体。
关键字检索的局限性
同一个语义,用词不同,可能导致检索不到有效的结果。属于一种硬匹配
# user_query="Does llama 2 have a chat version?"
user_query = "Does llama 2 have a conversational variant?"
search_results = search(user_query, 2)
for res in search_results:
print(res+"\n")
# user_query="Does llama 2 have a chat version?"
user_query = "Does llama 2 have a conversational variant?"
search_results = search(user_query, 2)
for res in search_results:
print(res+"\n")
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.§
variants of this model with 7B, 13B, and 70B parameters as well.
向量检索
文本向量(Text Embeddings)
- 将文本转成一组浮点数:每个下标 𝑖,对应一个维度
- 整个数组对应一个 𝑛 维空间的一个点,即文本向量又叫 Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
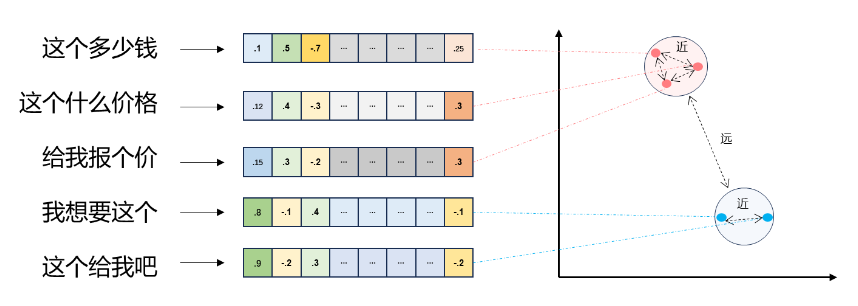
向量间的相似度计算
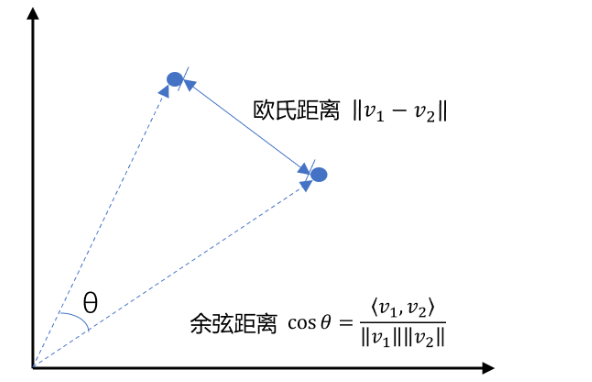
最常见的用余弦距离
# query = "国际争端"
# 且能支持跨语言
query = "global conflicts"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Query与自己的余弦距离: {:.2f}".format(cos_sim(query_vec, query_vec)))
print("Query与Documents的余弦距离:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print()
print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec)))
print("Query与Documents的欧氏距离:")
for vec in doc_vecs:
print(l2(query_vec, vec))
Query与自己的余弦距离: 1.00
Query与Documents的余弦距离:
0.7622376995981268
0.7564484035029613
0.7426558372998222
0.7077987135264396
0.7254230492369406
Query与自己的欧氏距离: 0.00
Query与Documents的欧氏距离:
0.6895829747071623
0.6979278474290739
0.7174178392255148
0.7644623330084925
0.7410492267209755
向量数据库
向量数据库,是专门为向量检索设计的中间件
澄清几个关键概念:
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
-
向量数据库的意义是快速的检索:
向量数据库是设计用来高效存储和检索向量数据的系统。这些向量通常是高维数据的数学表示,可以代表图像、文本或任何其他类型的复杂数据。向量数据库通过使用高效的索引结构(如KD树、球树、倒排索引等)来优化近似最近邻(ANN)查询,即快速找出与给定向量最相似的向量。这种快速检索功能使得向量数据库非常适用于推荐系统、图像识别、自然语言处理等应用,其中需要快速匹配和检索大量高维数据。 -
向量数据库本身不生成向量,向量是由 Embedding 模型产生的:
向量数据库专注于存储和检索向量,而不负责生成这些向量。向量的生成通常由专门的模型完成,这些模型称为嵌入模型(Embedding Models)。例如,在文本处理中,模型如BERT或Word2Vec可以将文本转换为数值向量,这些向量捕获了文本的语义特征。在图像处理中,如ResNet等深度学习模型可用于生成图像的特征向量。生成的向量随后被存储在向量数据库中,用于后续的检索和分析任务。 -
向量数据库与传统的关系型数据库是互补的,不是替代关系:
向量数据库和传统的关系型数据库(如MySQL、PostgreSQL等)各有其优势和适用场景。关系型数据库优秀于处理结构化数据(如表格数据),支持复杂的查询语言(如SQL),并提供事务性支持、一致性和持久性保证。相反,向量数据库则专门用于处理和检索高维向量数据。在实际应用中,根据需求经常同时使用这两种数据库。例如,在一个推荐系统中,可能会使用向量数据库来处理和检索用户和商品的嵌入向量,以找到相似的商品或用户;同时使用关系型数据库来管理用户的账户信息、交易记录等结构化数据。
综上,向量数据库提供了一种专门针对高维数据检索的优化解决方案,而其与传统数据库的结合使用可以在保证数据管理的多样性和效率方面发挥更大的潜力。
向量数据库服务
Server 端
chroma run --path /db_path
Client 端
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', port=8000)
主流向量数据库功能对比
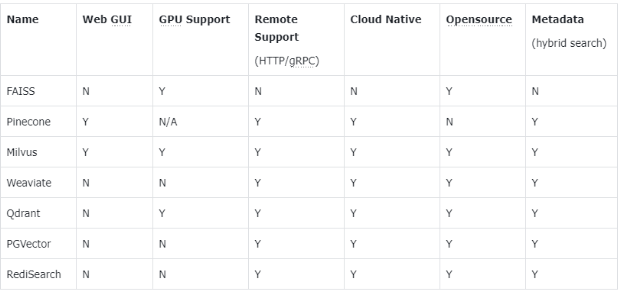
- FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
- Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/
- Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
- Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
- Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
- PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
- RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
基于向量检索的 RAG
class RAG_Bot:
def __init__(self, vector_db, llm_api, n_results=2):
self.vector_db = vector_db
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query, self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(
prompt_template, context=search_results['documents'][0], query=user_query)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
# 创建一个RAG机器人
bot = RAG_Bot(
vector_db,
llm_api=get_completion
)
user_query = "llama 2有多少参数?"
response = bot.chat(user_query)
print(response)
llama 2有7B, 13B, 和70B参数。
如果想要换个国产模型
import json
import requests
import os
# 通过鉴权接口获取 access token
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": os.getenv('ERNIE_CLIENT_ID'),
"client_secret": os.getenv('ERNIE_CLIENT_SECRET')
}
return str(requests.post(url, params=params).json().get("access_token"))
# 调用文心千帆 调用 BGE Embedding 接口
def get_embeddings_bge(prompts):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/embeddings/bge_large_en?access_token=" + get_access_token()
payload = json.dumps({
"input": prompts
})
headers = {'Content-Type': 'application/json'}
response = requests.request(
"POST", url, headers=headers, data=payload).json()
data = response["data"]
return [x["embedding"] for x in data]
# 调用文心4.0对话接口
def get_completion_ernie(prompt):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions_pro?access_token=" + get_access_token()
payload = json.dumps({
"messages": [
{
"role": "user",
"content": prompt
}
]
})
headers = {'Content-Type': 'application/json'}
response = requests.request(
"POST", url, headers=headers, data=payload).json()
return response["result"]
# 创建一个向量数据库对象
new_vector_db = MyVectorDBConnector(
"demo_ernie",
embedding_fn=get_embeddings_bge
)
# 向向量数据库中添加文档
new_vector_db.add_documents(paragraphs)
# 创建一个RAG机器人
new_bot = RAG_Bot(
new_vector_db,
llm_api=get_completion_ernie
)
user_query = "how many parameters does llama 2 have?"
response = new_bot.chat(user_query)
print(response)
Llama 2拥有7B、13B和70B三种不同参数量的版本。同时,根据已知信息,虽然还训练了34B的版本,但这个版本并没有发布。所以,Llama 2具体拥有的参数量取决于您使用的是哪一个版本。
OpenAI 新发布的两个 Embedding 模型
2024 年 1 月 25 日,OpenAI 新发布了两个 Embedding 模型
- text-embedding-3-large
- text-embedding-3-small
其最大特点是,支持自定义的缩短向量维度,从而在几乎不影响最终效果的情况下降低向量检索与相似度计算的复杂度。
通俗的说:越大越准、越小越快。 官方公布的评测结果:

model = "text-embedding-3-large"
dimensions = 128
# query = "国际争端"
# 且能支持跨语言
query = "global conflicts"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = get_embeddings([query], model=model, dimensions=dimensions)[0]
doc_vecs = get_embeddings(documents, model=model, dimensions=dimensions)
print("向量维度: {}".format(len(query_vec)))
print()
print("Query与Documents的余弦距离:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print()
print("Query与Documents的欧氏距离:")
for vec in doc_vecs:
print(l2(query_vec, vec))
向量维度: 128
Query与Documents的余弦距离:
0.33398035655745417
0.3530581001937585
0.3139780154086699
0.2137349345799671
0.12878899474455177
Query与Documents的欧氏距离:
1.1541400966944355
1.1374901586221358
1.171342807713185
1.2540056518268037
1.3200083334660306
扩展阅读:这种可变长度的 Embedding 技术背后的原理叫做 Matryoshka Representation Learning

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









