







FPGA Verilog 并行全比较算法(大点数)
排序算法的意义:
排序是一种重要的数据运算,传统的排序方法主要靠软件串行方式实现,包括冒泡法、选择法、计数法等,这些算法大多采用循环比较,运算费时,实时性差。不能满足工程上越来越高的实时性要求。FPGA由于其优秀的并行运算能力,充分利用这种能力可在短短数个周期内完成大点数(如256点)的排序任务。
算法介绍:
并行全比较算法时一种以FPGA的资源换取排序时间的算法。一组数据,先进行两两之间的比较,每两个数比较都会得到一个比较结果。可以根据两数的大小定义输出排序结果0或1。对这些比较结果进行求和计算得到积分通过积分可以进行排序。由于所有数的两两之间的比较都在硬件内同时进行,只需一个时钟的时间,即可得到比较结果,再加上比较结果的和加等计算时间,几个时钟周期,就实现了数字序列的排序。
算法优势:
在网上能找到的并行全比较算法,大多数时小点数的并行全比较算法。通过多个if-else判断,来进行对比和积分。但面对大点数的全比较并行算法,这种方式并不可行(笔者最初写了一个256点全比较算法,用这种方式写出来比较部分有6W多行,最终是通过写脚本输出文本来完成的)。本文采用了for循环的方法,同时采用二维数组作为积分表,来进行运算。通过三个周期可以完成排序。
算法流程
在缓存存满了之后,先进行数据的一一对比和计分。
case (mst_exec_state)
ranking:
if(cacu_flag)
begin
for(temp_j=0;temp_j<255;temp_j=temp_j+1) //对比
begin
for(temp_i=temp_j+1;temp_i<256;temp_i=temp_i+1)
begin
//#5;
if(save_data[temp_j]>save_data[temp_i])
begin
state[temp_j][temp_i]<=1;
end
else
begin
state[temp_i][temp_j]<=1;
end
end
end
mst_exec_state <= adding;
endstate[temp_j][temp_i]是一个二维数组。
如果data[temp_j]大于data[temp_i],state[temp_j][temp_i]置一。最后求和的时候data[1]的积分就是对state[1][i]求和。

图示为data2>data1>data0
求和部分:
adding:
if(cacu_flag)
begin
for(temp_j=0;temp_j<256;temp_j=temp_j+1) //求和
begin
for(temp_i=0;temp_i<256;temp_i=temp_i+1)
begin
sum[temp_j] = state[temp_j][temp_i] + sum[temp_j];
end
end
mst_exec_state <= saving;
end按照积分排序。
saving:
if(cacu_flag)
begin
for(temp_j=0;temp_j<256;temp_j=temp_j+1) //输入对应位置
begin
output_data[sum[temp_j]] <= save_data[temp_j];
end
out_data_i <=0;
output_flag <=1;
cacu_flag <=0;
dat_num <=0;
mst_exec_state <= ranking;
clear_state<=1;
endsum所有的积分最终就是对应数字应该在的位置 output_data[sum[temp_j]] ,同时这种写法已经考虑到了一组数据中有几个相等的数字的情况,两个数字相等,会给后面的数字计分加1.
所有代码和TB
代码
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2018/08/21 15:40:50
// Design Name:
// Module Name: rank
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module rank(
input wire aclk, //模块输入时钟
input wire aken, //模块中断信号
input wire [7:0] in_data, //输入信号数据
input wire ready,
output reg valid,
output reg [7:0] out_data //输出信号数据
);
reg [7:0] state [255:0][255:0]; //比较大小记录寄存器
reg [7:0] sum [255:0]; //比较大小记录求和
reg [7:0] save_data [255:0]; //输入数据存储
reg [7:0] output_data [255:0]; //输出数据缓存
reg cacu_flag = 0; //计算比较标志位
reg output_flag = 0; //输出信号标志位
reg clear_state = 0; //清除内存标志位
//一些计数变量
integer out_data_i = 0;
integer dat_num = 0;
integer temp_i = 0;
integer temp_j = 0;
integer clear_i = 0;
integer clear_j = 0;
parameter [1:0] ranking = 2'b00, // This is the initial/idle state
adding = 2'b01, // This state initializes the counter, ones
// the counter reaches C_M_START_COUNT count,
// the state machine changes state to INIT_WRITE
saving = 2'b10;
reg [1:0] mst_exec_state;
initial $readmemh("C:/Users/74339/Desktop/vivado_code/ranking/int.txt",sum);
always@(posedge aclk) //清理内存逻辑控制
begin
if(clear_state)
begin
for(clear_i=0;clear_i<256;clear_i=clear_i+1)
begin
for(clear_j=0;clear_j<256;clear_j=clear_j+1)
begin
state[clear_i][clear_j]<=0;
end
sum[clear_i] <=0;
end
clear_state <= 0;
end
end
always@(posedge aclk) //计算开始逻辑控制
begin
if(dat_num>255)
begin
cacu_flag <= 1;
valid <= 0;
end
else
begin
valid <= 1;
end
end
always@(posedge aclk) //输入控制信号逻辑
begin
if(valid&ready)
begin
save_data[dat_num] <= in_data;
dat_num <= dat_num + 1;
end
end
always@(posedge aclk)
begin
if(!aken)
begin
clear_state <= 1;
dat_num <= 0;
valid <= 0;
cacu_flag <= 0;
out_data <= 8'h00;
mst_exec_state <= ranking;
end
else
begin
case (mst_exec_state)
ranking:
if(cacu_flag)
begin
for(temp_j=0;temp_j<255;temp_j=temp_j+1) //对比
begin
for(temp_i=temp_j+1;temp_i<256;temp_i=temp_i+1)
begin
//#5;
if(save_data[temp_j]>save_data[temp_i])
begin
state[temp_j][temp_i]<=1;
end
else
begin
state[temp_i][temp_j]<=1;
end
end
end
mst_exec_state <= adding;
end
adding:
if(cacu_flag)
begin
for(temp_j=0;temp_j<256;temp_j=temp_j+1) //求和
begin
for(temp_i=0;temp_i<256;temp_i=temp_i+1)
begin
sum[temp_j] = state[temp_j][temp_i] + sum[temp_j];
end
end
mst_exec_state <= saving;
end
saving:
if(cacu_flag)
begin
for(temp_j=0;temp_j<256;temp_j=temp_j+1) //输入对应位置
begin
output_data[sum[temp_j]] <= save_data[temp_j];
end
out_data_i <=0;
output_flag <=1;
cacu_flag <=0;
dat_num <=0;
mst_exec_state <= ranking;
clear_state<=1;
end
endcase
end
end
always@(posedge aclk)
begin
if(output_flag)
begin
out_data <= output_data[out_data_i];
out_data_i <= out_data_i + 1;
end
end
always@(posedge aclk)
begin
if(out_data_i>=256)
begin
out_data_i <= 0;
output_flag <= 0;
end
end
endmoduleTB
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer:
//
// Create Date: 2018/08/21 17:14:18
// Design Name:
// Module Name: rank_TB
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////
module rank_TB;
reg aken;
reg aclk = 0;
reg [7:0] in_data = 0;
reg ready;
wire valid;
wire [7:0] out_data;
rank uut(
.aclk(aclk),
.aken(aken),
.in_data(in_data),
.ready(ready),
.valid(valid),
.out_data(out_data)
);
reg[11:0] mem0_re[700:0];
integer temp_i = 0;
initial $readmemh("C:/Users/74339/Desktop/vivado_code/ranking/data.txt",mem0_re);
always #5 aclk <= !aclk;
always @(posedge aclk)
begin
ready <= 1;
if(ready&&ready)
begin
in_data <= mem0_re[temp_i];
temp_i <= temp_i+1;
end
end
initial
begin
aken <=0 ;
#30;
aken <= 1;
end
endmodule仿真结果:
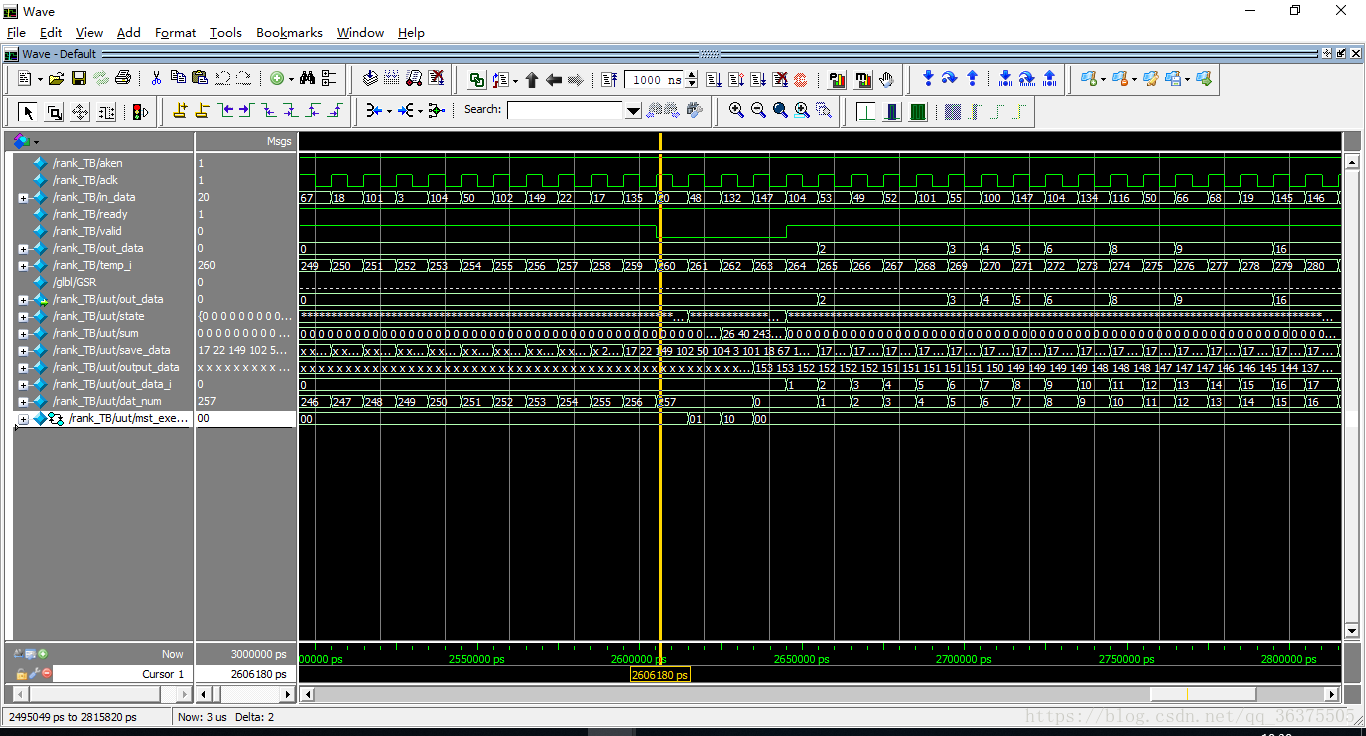
可以看到,在缓存存满了之后,一个周期开始进行计分,一个周期求和,之后就可以输出啦。
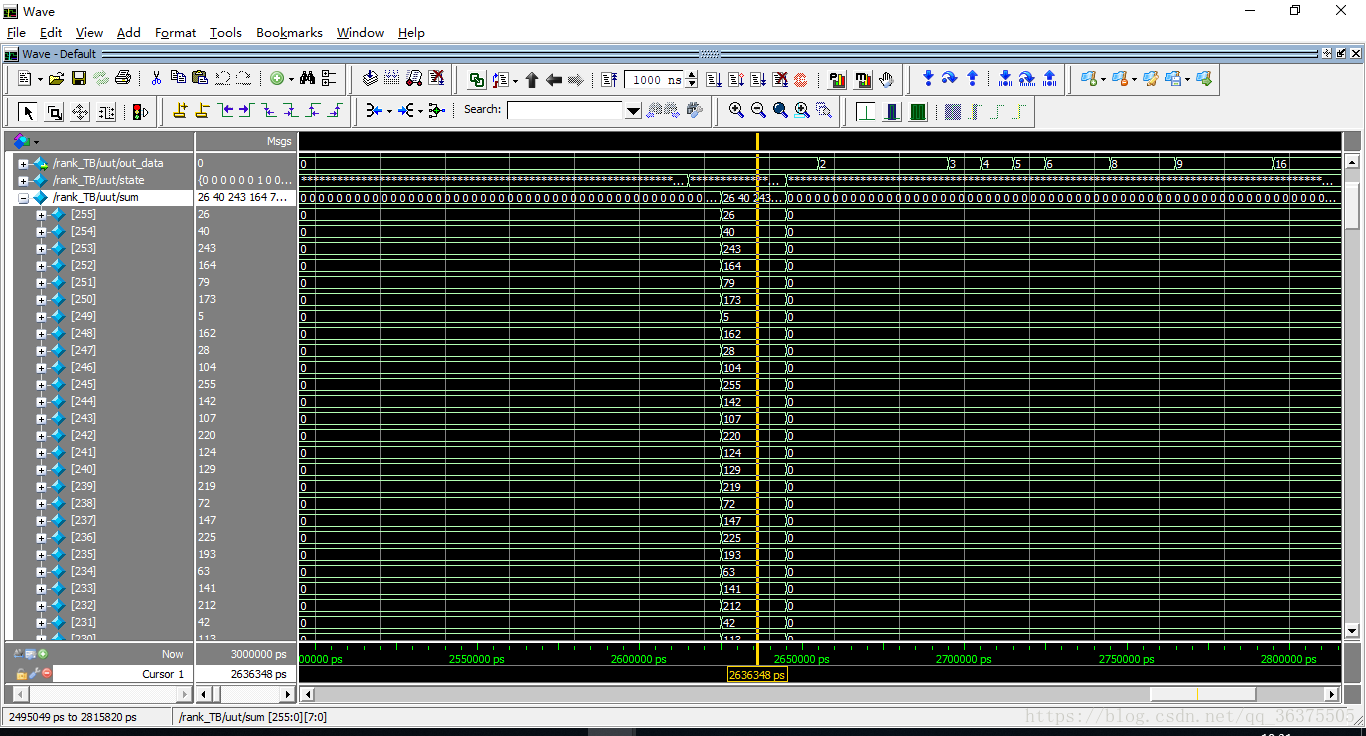
各个数对应的积分。
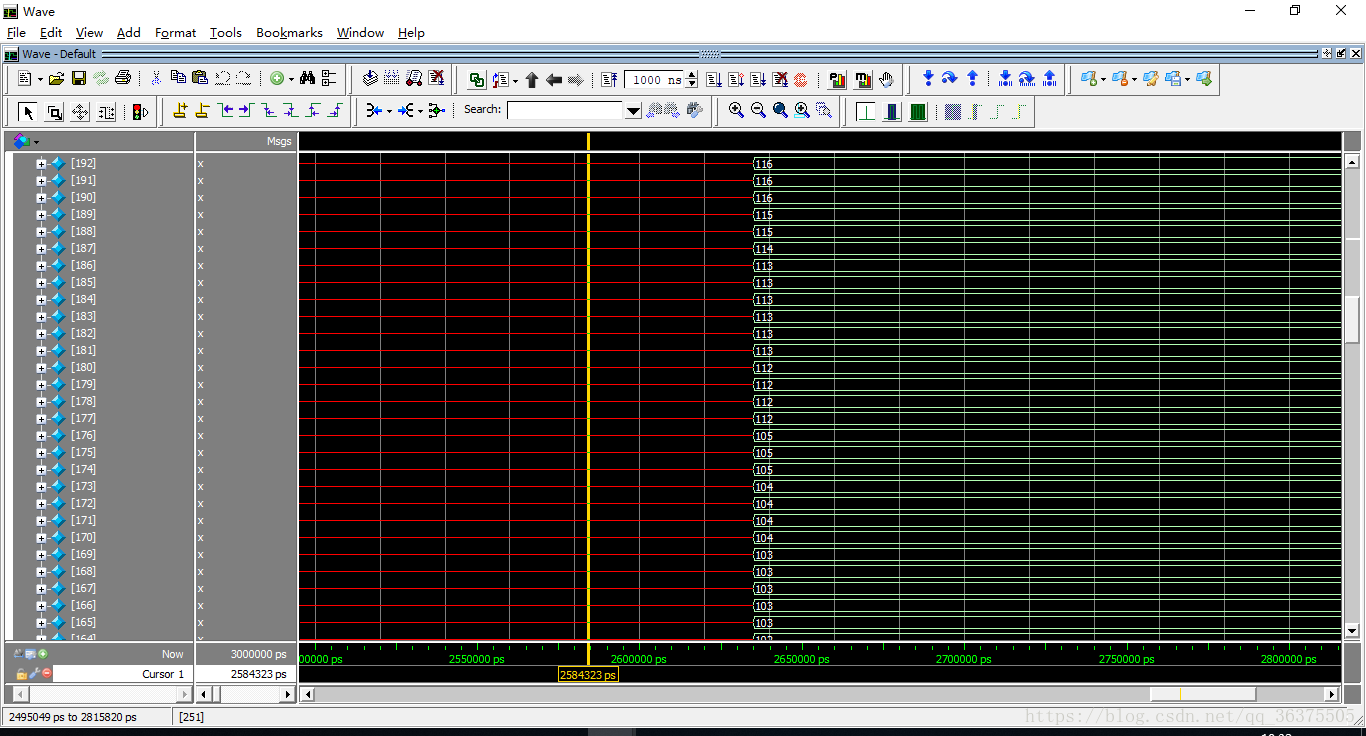
排序之后的数。可以看到已经考虑过了数字相等的情况。

















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









