







【论文速递】ECCV2022 - 开销聚合与四维卷积Swin Transformer_小样本分割
【论文原文】:Cost Aggregation with 4D Convolutional Swin Transformer for Few-Shot Segmentation
获取地址:https://arxiv.org/pdf/2207.10866.pdf
博主关键词: 小样本学习,语义分割,Transformer,聚合
推荐相关论文:
【论文速递】CVPR2022 - 学习 什么不能分割:小样本分割的新视角
- https://blog.csdn.net/qq_36396104/article/details/128658168
摘要:
本文提出了一种新的开销聚合网络,称为体积聚合Transformer(VAT),用于小样本分割。Transformer的使用可以通过对全局接受域的自注意力而有利于相关映射聚合。但是,用于Transformer处理的相关映射的标记化可能是有害的,因为标记边界上的不连续减少了标记边缘附近可用的本地上下文,并减少了归纳偏差。 为了解决这个问题,我们提出了一个4D卷积Swin Transformer ,其中高维Swin Transformer之前是一系列小核卷积,将局部上下文传递给所有像素,并引入卷积归纳偏差。我们还通过在金字塔结构中应用transformers来提高聚合性能 ,在金字塔结构中,较粗级别的聚合引导较细级别的聚合。然后,在查询的外观嵌入的帮助下,在后续的解码器中过滤变压器输出中的噪声。有了这个模型,一种新的最先进的技术在小样本分割被设置为所有的标准基准。结果表明,VAT在语义对应方面也达到了最先进的性能,其中开销聚合也起着核心作用。代码和训练过的模型可以在https://seokju-cho.github.io/VAT/上找到。
简介:
语义分割是一项基本的计算机视觉任务,旨在为图像中的每个像素标记相应的类。在深度神经网络和包含ground-truth分割注释的大规模数据集的帮助下,这一方向已经取得了实质性进展[37,46,3,4,61]。然而,手动标记按像素划分的地图需要大量的劳动,因此很难添加新的类。为了减少对标记数据的依赖,人们越来越关注小样本分割[49,55],其中只有少数支持图像及其相关掩码被用于预测查询图像的分割。
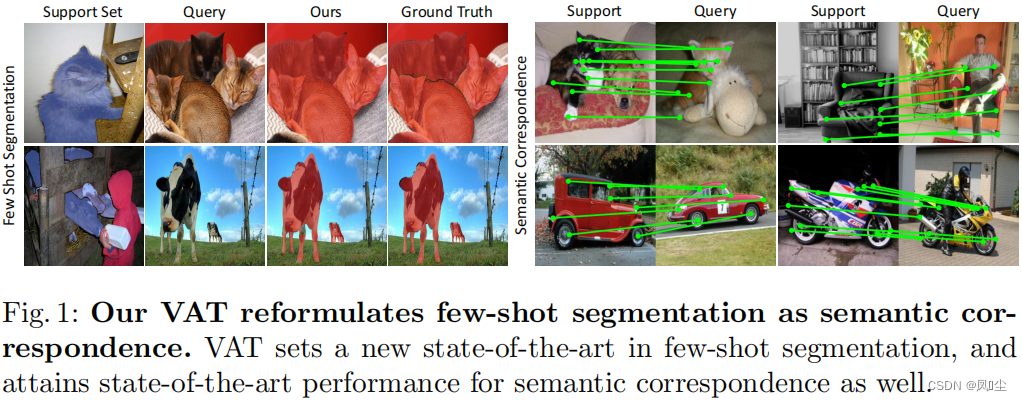
小样本分割的关键是有效利用少的支持样本。许多工作尝试从样本中提取原型模型,并将其用于与查询的特征比较[58,10,35,78]。然而,这种方法忽略了支持特征和查询特征之间像素级的成对关系或特征的空间结构,可能会导致次优结果。
为了解释这种关系,我们观察到,小样本分割可以重新表述为语义对应,其目的是在语义相似的图像之间找到像素级对应,这些图像可能包含大量的类内外观和几何变化[13,14,43]。 最近的语义对应模型[50,25,51,53,42,44,34,65,41]遵循了特征提取、开销聚合和流量估计的经典匹配管道[54,47]。在开销聚合阶段,匹配分数被细化以产生更可靠的对应估计,这是特别重要的,也是许多研究的焦点[53,42,52,22,34,29,41,6]。最近CATs[6]提出使用视觉transformers[11]进行开销聚合,但其对输入令牌数量的二次复杂度限制了其适用性。它还忽视了匹配成本的空间结构,这可能会损害其绩效。
在小样本分割领域,也有一些方法试图通过交叉注意(cross-attention)[83]或图注意(graph attention)[81,68,75]来精炼特征,从而利用成对信息。然而,它们只依赖原始相关图,而不聚合匹配分数。因此,它们的对应可能会因重复的模式或背景杂散而产生歧义[50,25,27,65,17]。为了解决这个问题,HSNet[40]使用4D卷积聚合匹配分数,但其有限的接受字段阻止了远程上下文聚合,并且由于使用固定内核而缺乏适应输入内容的能力。
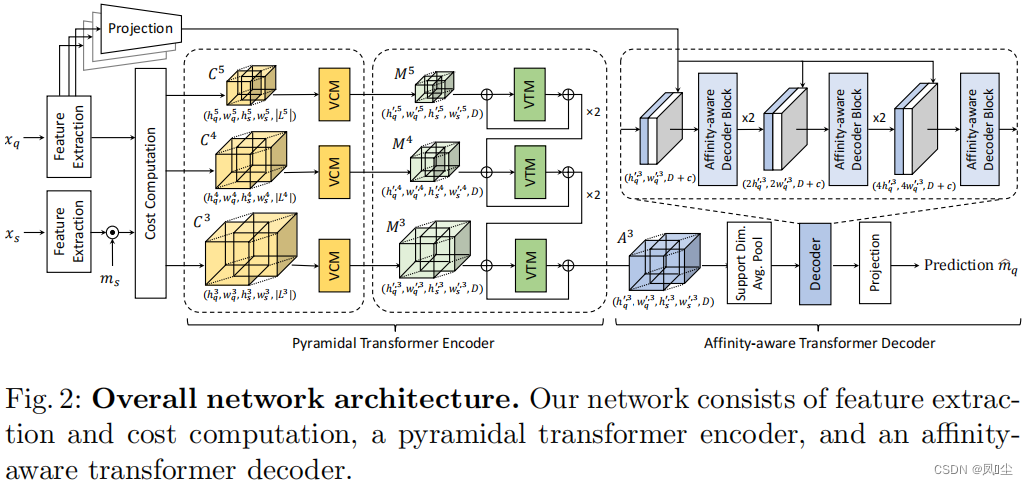
在本文中,我们介绍了一种新的开销聚合网络,称为Volumetric aggregation with Transformer (VAT),它通过提出的4D卷积Swin Transformer解决了小样本分割任务。 具体来说,我们首先扩展Swin Transformer[36]及其补丁嵌入模块,以处理高维相关映射。通过引入4D卷积来进一步扩展补丁嵌入模块,缓解了补丁嵌入引起的问题,即补丁边界附近有限的局部上下文和低归纳偏差。高维补丁嵌入模块被设计为一系列重叠的小核卷积,为每个像素带来局部上下文信息,并赋予卷积归纳偏差。为了进一步提高性能,我们使用金字塔结构组合我们的体系结构,该结构将较粗级别上的聚合相关映射作为较细级别上的额外输入,从而提供分层指导。然后,我们的亲和感知解码器以一种利用查询外观嵌入给出的更高分辨率空间结构的方式细化聚合匹配分数,并最终输出分割掩码预测。
我们在几个基准上证明了该方法的有效性[55,31,30]。我们的工作在所有的基准上都达到了最先进的性能,用于few-shot分割,甚至用于语义对应,突出了开销聚合对这两个任务的重要性,并显示了其一般匹配的潜力。我们还包括消融研究,以证明我们的设计选择。
【社区访问】
 【论文速递 | 精选】
【论文速递 | 精选】
 阅读原文访问社区
阅读原文访问社区















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











