







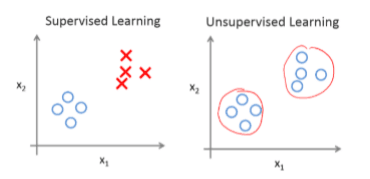
监督学习,如图表所示,这个数据集种每条数据都已经表明是阴性或阳性,即是良性或恶性肿瘤。所以,对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案是良性或恶性了。
在无监督学习中,我们已知的数据不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。无监督学习算法可能会把这些数据分成两个不同的簇,所以叫做聚类算法。
聚类应用的一个例子就是在谷歌新闻中(news.google.com)。谷歌新闻每天都在收集非常多的网络上的新闻内容,它再将这些新闻分组,组成有关联的新闻。所以谷歌新闻做的就是搜索非常多的新闻事件,自动地把它们聚类到一起,同一主题的新闻事件能显示到一起。

聚类算法和无监督学习算法同样还应用在很多其它问题上,例如基因学的理解应用。一个DNA微观数据的例子,基本思想是输入一组不同个体,对其中的每个个体,你要分析出它们是否有一个特定的基因。技术上,你要分析多少特定基因已经表达。所以这些颜色展示了相应的程度,即不同的个体是否有着一个特定的基因。你能做的就是运行一个聚类算法,把个体聚类到不同的类或不同类型的组(人)……
以上就是无监督学习,因为我们没有提前告知算法一些信息。我们只是说,这是一堆数据,我不知道数据里面有什么,不知道谁是什么类型,甚至不知道有哪些类型,这些类型是什么。但你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类。我没法提前知道哪些是哪些,因为我们没有给算法正确答案来回应数据集中的数据,这就是无监督学习。
无监督学习或聚类有着大量的应用,它应用于组织大型计算机集群。在大数据中心有大型的计算机集群,可以解决什么样的机器易于协同工作,如果能够让那些机器协同工作,就能让数据中心工作得更高效。第二种应用就是社交网络的分析。已知社交账号中好友的信息,能否自动地给出好友的分组呢?即每组里的人们彼此都熟识,认识组里的所有人。还有市场分割。许多公司有大型的数据库,存储消费者信息。能检索这些消费者数据集,自动地发现市场分类,并自动地把消费者划分到不同的细分市场中,才能自动并更有效地销售或不同的细分市场一起销售。这也是无监督学习,因为我们拥有所有的消费者数据,但我们没有提前知道是什么样的细分市场,以及分别有哪些我们数据集中的消费者,我们不知道谁是在一号细分市场,谁在二号细分市场等等。那我们就必须让算法从数据中发现这一切。无监督学习也可用于天文数据分析。这些聚类算法给出了令人惊讶、有趣、有用的理论,解释了星系是如何诞生的。这些都是聚类的例子,聚类只是无监督学习中的一种。

通过介绍鸡尾酒宴问题来引入另一种无监督学习算法。想象一下在宴会上,房间里坐着许多人同时在聊天。这么多人同时在聊天,声音彼此重叠。可能在这样的宴会中两个人同时在说话,我们放两个麦克风在房间中,这两个麦克风在两个地方,离说话人的距离不同,麦克风记录下不同的声音。虽然是同样的两个说话人,听起来像是两份录音被叠加到一起,或者是被归结到一起,产生了我们现在的录音。另外,这个算法还会区分出两个音频资源,这两个可以合成或合并成之前的录音。
无监督学习,它是学习策略,交给算法大量的数据,并让算法为我们从数据中找出某种结构。















07-08
 710
710
710
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









