










 本文介绍了在ACL2021的论文中,提出了一种名为MLM-phonetics的模型,它将拼音特征整合到BERT预训练和微调中,解决中文拼写纠错难题。模型通过检测和纠正模块,利用语音信息提高纠错准确度,尤其针对发音相似字符错误。实验结果显示,MLM-phonetics在SIGHAN评测中达到SOTA性能。
本文介绍了在ACL2021的论文中,提出了一种名为MLM-phonetics的模型,它将拼音特征整合到BERT预训练和微调中,解决中文拼写纠错难题。模型通过检测和纠正模块,利用语音信息提高纠错准确度,尤其针对发音相似字符错误。实验结果显示,MLM-phonetics在SIGHAN评测中达到SOTA性能。
论文解读:Correcting Chinese Spelling Errors with Phonetic Pre-training(ACL2021)
中文拼写纠错CSC任务具有挑战性,目前的SOTA方法是仅使用语言模型,或将语音信息作为外部知识;本文将提出一种新的端到端的CSC模型,将phonetic(拼音)特征融入到预训练和微调部分:
- 我们在预训练阶段,每次随机将某个token替换为sound-alike的词;
- 提出adaptive weighted联合训练detection和correction。
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | MLM-phonetics |
| 2 | 所属领域 | 自然语言处理、中文拼写纠错 |
| 3 | 研究内容 | 中文拼写纠错 |
| 4 | 核心内容 | BERT应用 |
| 5 | GitHub源码 | |
| 6 | 论文PDF | https://aclanthology.org/2021.findings-acl.198.pdf |
一、动机
- 本文我们关注中文拼写纠错。中文字符需要借助拼音等信息。83%的错误均来自于发音相似的字符;
- 语言模型用于生成流利的句子,语音特征可以防止模型产生发音偏离原始单词的预测;、
The language model is used to generate fluent sentences and the phonetic features can prevent the model from producing predictions whose pronunciation deviates from that of the original word
- 模型虽然可以将错误的字进行纠错,虽然纠错后的语法层面上没有问题,但可能两个字的发音没有相关性。例如“的语”希望纠正为“德语”,但如果纠正为“英语”则不太合适;
二、方法
模型包含两个模块:
- detection module:喂入一个句子,该模块将预测每个token是错误的概率;
- correction module:同时结合每个字符的word embedding和pinyin embedding,并使用detection module预测的概率作为权重,进行纠错;
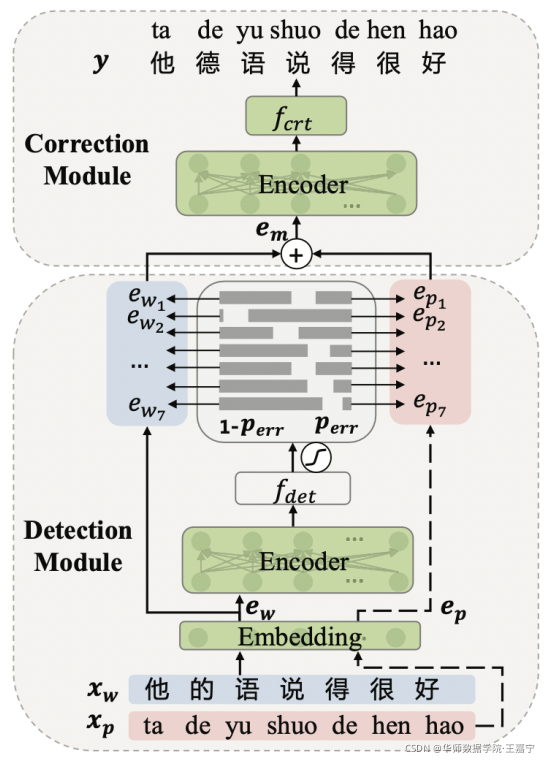
1、模型架构
(1)Detection Module
该模块用于判断句子中的token是否可能是错误的,采用0-1标签进行标注。
公式:
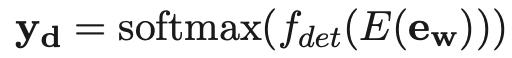
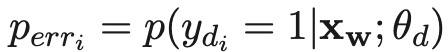
(2) Correction Module
根据预测的概率值,对word embedding和pinyin embedding进行加权求和
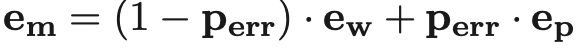
最后输出:
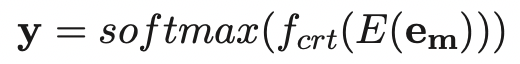
备注:
- 该模型架构与SoftMasked Bert思路一致,只不过SoftMasked Bert引入的是[MASK] embedding,而本文则是pinyin embddding;
- 如上图,Embedding层、Encoder层和Correction Network参数均由MLM-phonetics初始化(见下文)
2、Joint Fine-tuning
训练时,Detection Network和Correction Network联合训练:
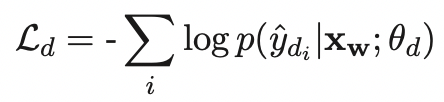
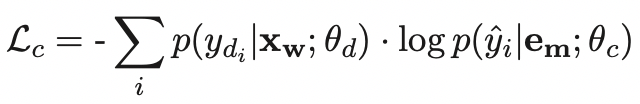
- 第一个loss表示detection module,预测每个token是否是错误的,使用cross entropy loss;
- 第二个loss表示correction module,预测每个token的真实词。对于每个token,使用 p ( y d i ∣ x w ; θ d ) p(y_{d_i}|\mathbf{x}_{\mathbf{w}};\theta_d) p(ydi∣xw;θd)(Detection Module预测该位置ground-truth的概率)作为权重;
3、Pre-training MLM-phonetics
传统的MLM预训练时,是将[MASK]喂入句子,并预测对应的词;而CSC则是喂入一个带有错误token的句子,并预测对应的正确的词,因此两者输入的分布有所区别;
因此,本文提出基于MLM提出MLM-phonetic,即除了随机替换[MASK]以外,还根据pinyin的相似的其他token进行替换。随机替换规则如图所示:
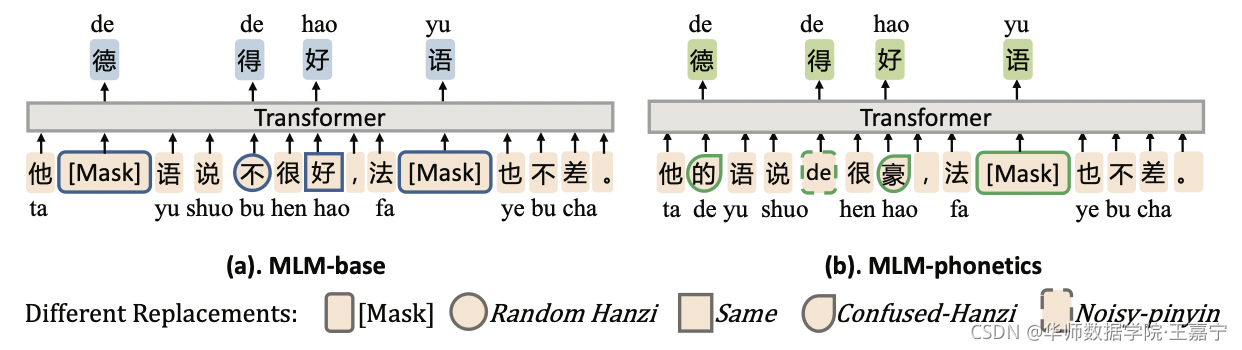
在MLM-phonetics中,由20%的token将进行替换,其中:
- 40%将随机替换为[MASK];
- 30%将随机替换为noisy-pinyin(pinyin token);
- 30%将随机替换为confused-Hanzi(通过pinyin构建混淆集);
四、实验
在SIGHAN13、14和15测试集上测试的结果如下图:
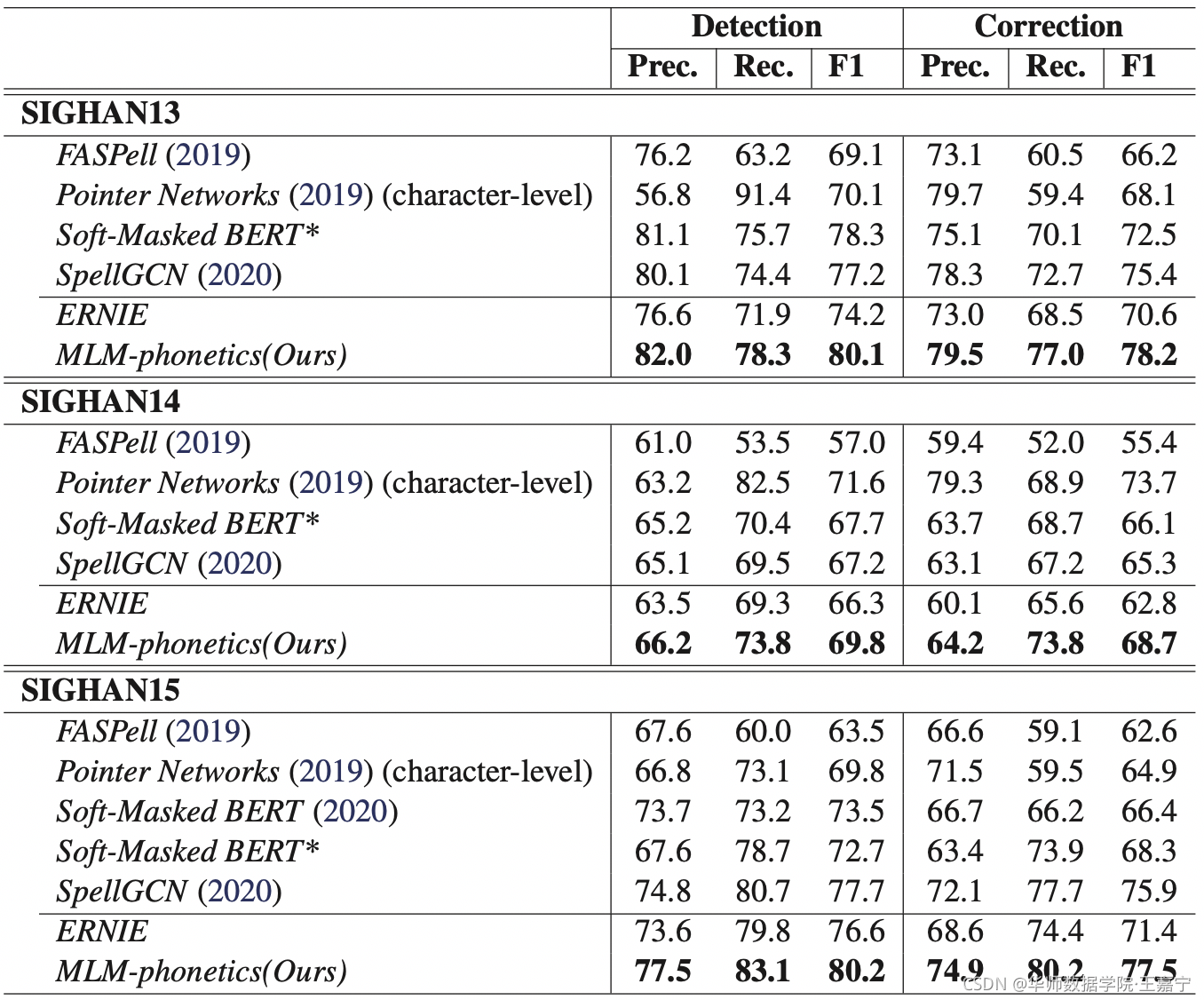
可以看出,相比其他模型,MLM-phonetic达到SOTA性能。


















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











