









论文解读:Global Attention Decoder for Chinese Spelling Error Correction(ACL2021)
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | GAD |
| 2 | 所属领域 | 自然语言处理、中文拼写纠错 |
| 3 | 研究内容 | 中文拼写纠错 |
| 4 | 核心内容 | Global Attention Decoder |
| 5 | GitHub源码 | |
| 6 | 论文PDF | https://aclanthology.org/2021.findings-acl.122.pdf |
一、动机
- 根据先前工作统计, 中文拼写纠错CSC任务中,有83%的错误来自于相似的发音,48%的错误来自于相似的字形;
- 先前的CSC方法可以分为基于语言模型和基于Seq2Seq;
- 几乎所有最近的CSC工作都使用了Confusion Set(混淆集);
- 先前的方法预测每一个字符或词均只关注可能存在错误信息的局部上下文,至今,还没有工作被提出用于缓解噪声的影响
Previous methods predict each character or word based on its local context that may has noisy information (other errors). So far, no method has been proposed to alleviate the impact of this noisy information.
因此:
- 我们提出使用BERT,基于confusion set的替换策略(BERT CRS),以拉近BERT与CSC两个任务之间的距离
- 提出新的Global Attention Decoder(GAD),并学习到全局的上下文标注信息以避免噪声带来的影响;
二、方法
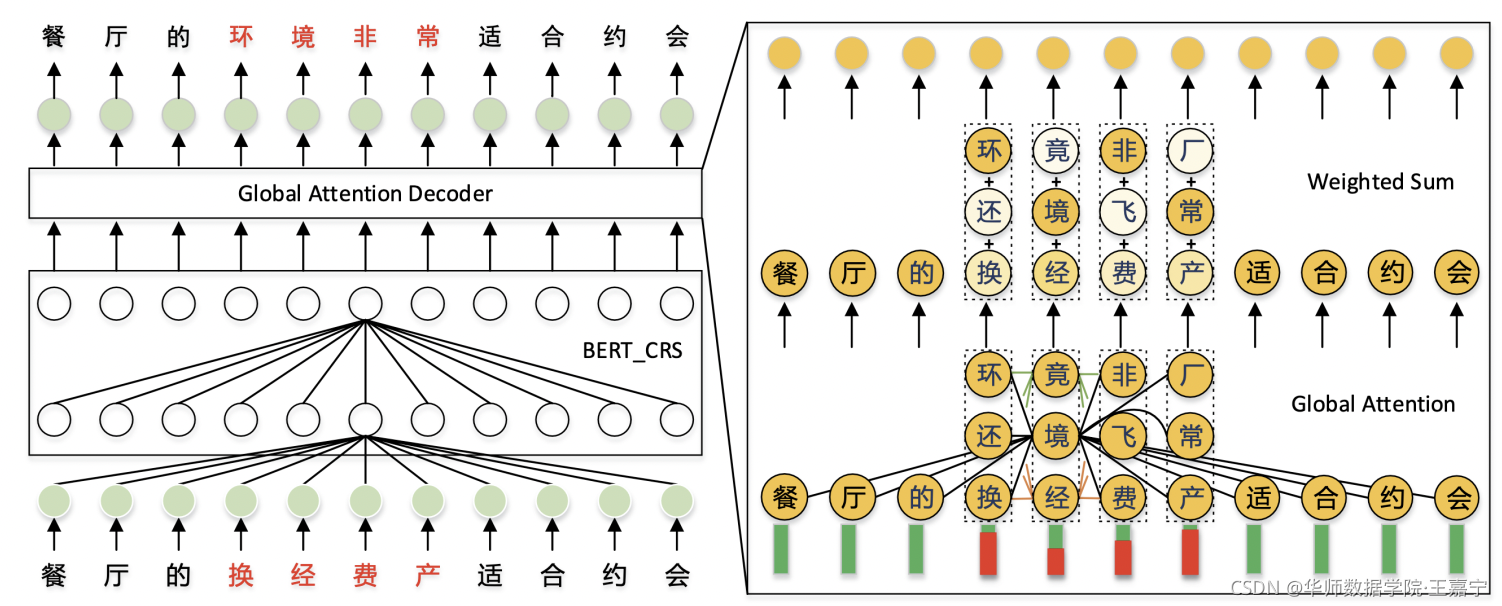
主体架构如上图所示,在进行纠错时,主要进行两个步骤:
- 给定一个待纠错的中文字符序列, 首先通过BERT_CRS模块(下文介绍)获得每个字符的表征向量, 其次通过decision network将其映射为0-1序列,其中0表示当前的字符是正确的,1表示当前的字符是错误的;
- 在BERT_CRS之上,添加Global Attention Decoder(GAD)模型,其融入额外的候选字符,以避免局部上下文的错误信息;
2.1 BERT_CRS
BERT_CRS是一种带有 C onfusion set guided R eplacement S trategy的BERT模型。具体描述为:
- 去除了NSP任务,并添加一个decision network(用于判断当前位置是否是错误的)
- 参考MacBERT,除了随机替换为[MASK],还引入基于confusion set的替换策略,即对于某个字符,随机从confusion set中替换字音或字形相似的字符;
- 对于输入的序列,23%的字符随机替换,这些替换的字符中,35%不替换,30%从confusion set中替换,30%则替换为[MASK],5%则从词表中随机替换一个字符。
2.2 Global Attention Decoder(GAD)
动机: 因为BERT的每一层Transformer,对于某一个token的representation,都是对所有的上一层的token representation进行加权求和,由于存在错误的token,导致这部分的噪声信息也被进行了加权,因此会对CSC模型产生影响。因此,作者提出GAD模型,即对每一层Transformer,计算attention时,还要考虑错误token对应的confusion set中高置信度的其他token。
基于confusion set的高置信度候选token:
对于一个长度为 n n n 的句子,对于每一个位置的字符,其根据confusion set将可以得到一组候选字符: c = { c 1 , c 2 , ⋯ , c n } c = \{c_1, c_2, \cdots , c_n\} c={c1,c2,⋯,cn}。假设对于第 i i i 个位置的字符可能是错误的,因此该错误的字符将会引入噪声信息,因此可以对该位置根据阈值 t t t 预先获得一组置信度较高的字符集:

Global Attention
在原始的Transformer结构基础上,新增一个Globa Attention结构,如下图所示:

该结构主要目标是提取错误token对应的若干候选token的语义信息,以弱化由于错误token带来的噪声。
在每一层,除了融入上一层的表征 V V V 外,还将融入候选字符集 C C C 的信息:
- 对于候选字符集,每个字符使用BERT_CRS获得word embedding,然后一同喂入到Add&Norm 层;

- 任意两个字符之间的global attention计算方式:

即需要计算第 i i i 个字符的第 j j j 个候选字符与第 p p p 个字符的第 q q q 个候选字符之间的attention,再对所有的候选字符进行加权求和,得到 G A i j \mathbf{GA}_{ij} GAij 表示是第 i i i 个字符的第 j j j 个候选字符的表示。
最后,对于每一个位置的字符,对其所有候选字符进行加权求和:

三、实验
数据集选择SIGHAN13、SIGHAN14和SIGHAN15三个常用中文纠错数据集,统计信息如下:

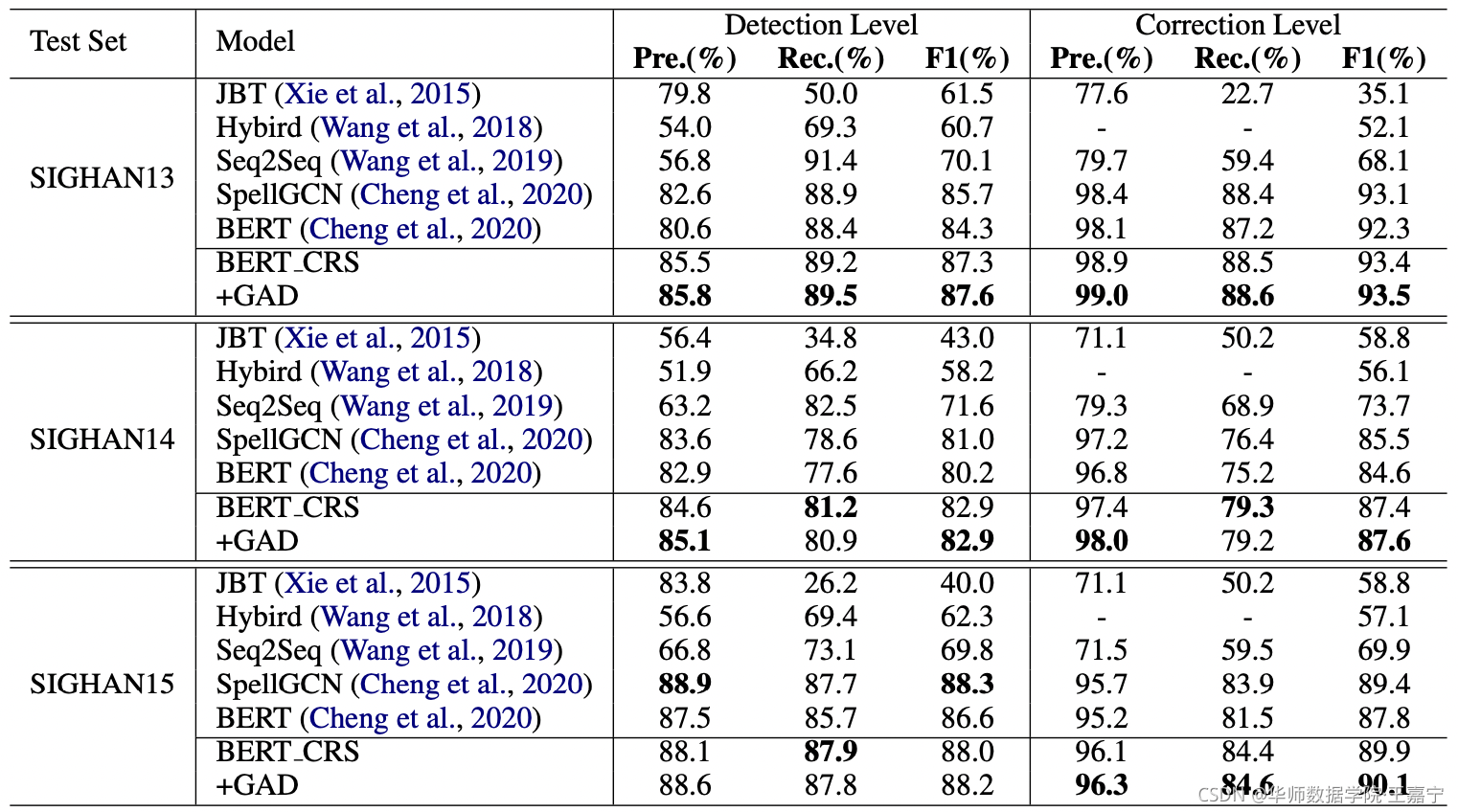
作者提供了sentence-level和character-level上对于三个不同测试集上的结果,如下图所示:
(1)sentence-level实验结果:
(2)character-level实验结果:
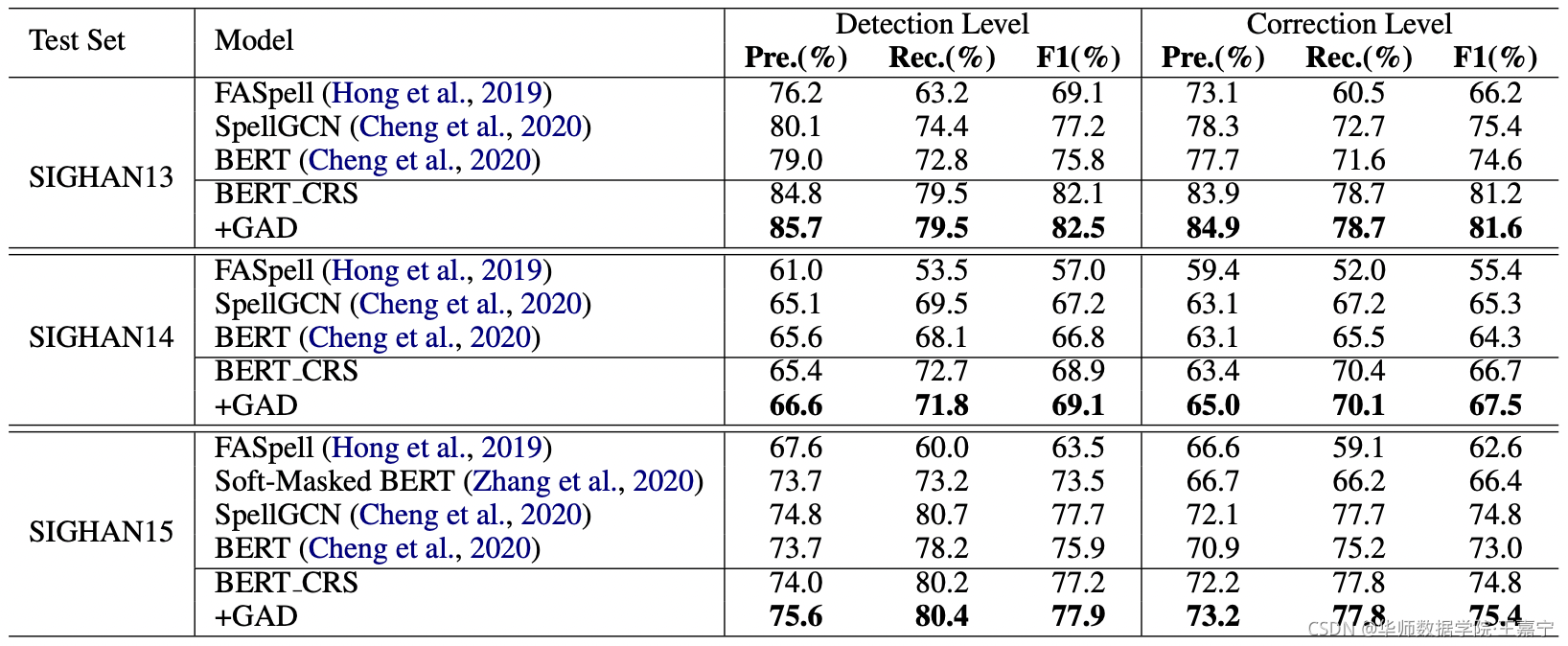
可以发现,BERT_CRS以及加入的GAD模块在所有数据集上均达到SOTA性能。


















 6405
6405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











