







Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning

Github:https://github.com/YuxiXie/MCTS-DPO
一、动机
大语言模型在偏好对齐环节可以提高模型的性能。目前有诸多工作尝试将偏好对齐通过迭代的形式进行改进:
It involves a cycle that begins with the current policy, progresses through the collection and analysis of data to generate new preference data, and uses this data to update the policy
目前有一些工作尝试这种迭代式对齐:
- Reinforced self-training (rest) for language modeling
- Large language models can self-improve
- Self-rewarding language models
在强化学习生态中,一个典型的工作AlphaZero就是采用这种迭代式的训练,其通过结合神经网络、强化学习以及蒙特卡洛树搜索(MCTS)实现这个迭代式过程。
然而在强化学习中,MCTS是一个N-step自举法,即对整个trajectory进行多步Reward计算。然而在大模型中,如何使用这种N-step自举法?目前很多preference pair都是站在样本(instance-lever)层面进行打标的,这会导致损失一些细节信息,对于MCTS这种需要以step层面进行学习的方式会不友好。
Conventionally, preference data is collected at the instance level. The instance-level approach employs sparse supervision, which can lose important information and may not optimally leverage the potential of MCTS in improving the LLMs
二、方法
本文提出一种迭代式的DPO算法,通过MCTS算法来抽取偏好数据,并用迭代式地训练Policy模型。整个流程大致如下所示:
- 首先初始化一个policy模型 π θ ( 0 ) \pi_{\theta^{(0)}} πθ(0),以及一个prompt数据集 D P \mathcal{D}_{\mathcal{P}} DP;
- 在第 i i i次迭代时,先采样一组prompt,并使用上一轮的policy模型 π θ ( i − 1 ) \pi_{\theta^{(i-1)}} πθ(i−1)为每个prompt生成若干个response;
- 使用一个不断进化的Reward标准来抽取偏好数据 D i \mathcal{D}_i Di;
- 基于这个新的偏好数据,训练新的policy模型 π θ ( i ) \pi_{\theta^{(i)}} πθ(i);
这一过程比较类似于online版本的DPO偏好训练。

在抽取偏好数据时,采用MCTS算法,将instance-level的偏好转换为step-wise。
2.1 MCTS获得 Step-wise偏好数据
假设
x
x
x为prompt,
s
t
s_t
st表示大模型生成推理过程中reasoning chain中的前
t
t
t步,
a
a
a表示从
s
t
s_t
st进入下一个时刻
s
t
+
1
s_{t+1}
st+1的动作,换句话说
a
a
a表示当前时刻要执行的推理步骤(动作)。
为此,当前所有可能的推理步骤(动作空间)可以表示为
π
θ
(
a
∣
x
,
s
t
)
\pi_{\theta}(a|x, s_t)
πθ(a∣x,st)。MCTS会根据当前已知的状态预测未来N步骤之后的奖励情况,例如预测下一最佳推理状态可表示为:
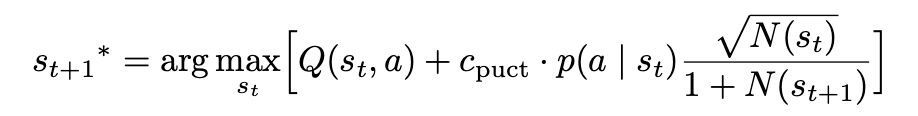
其中
Q
(
s
t
,
a
)
Q(s_t, a)
Q(st,a)表示基于当前已有的reasoning chain,完成当前的推理
a
a
a后会得到的Reward奖励值。
N
(
s
t
)
1
+
N
(
s
t
+
1
)
\frac{\sqrt{N(s_t)}}{1+N(s_{t+1})}
1+N(st+1)N(st)则用于平衡探索(exploring)与利用(exploiting)之间的关系,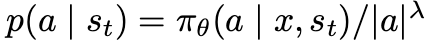 。
。
- 探索:更多地试探其他可能的推理路径;
- 利用:取奖励最大的动作 a a a作为下一步的推理。
为了确保在树搜索过程中,在搜索过程中,采用Self-evaluation。evaluation的模板
prompt
eval
\text{prompt}_{\text{eval}}
prompteval如下所示:

基于这个evaluation prompt
prompt
eval
\text{prompt}_{\text{eval}}
prompteval,让当前的额policy模型充当一个evaluator,对当前前
t
t
t步骤的推理结果
s
t
s_t
st进行预测,得到一个score:
C ( s t ) = π θ ( A ∣ prompt e v a l , x , s t ) \mathcal{C}(s_t)=\pi_{\theta}(\text{A}|\text{prompt}_{eval}, x, s_t) C(st)=πθ(A∣prompteval,x,st)
Self-evaluation相关工作:Decomposition enhances reasoning via self-evaluation guided decoding.
另外,如果大模型生成的
s
t
s_t
st在格式上完成了推理(即整个生成已经完成)且正确,那么记作
O
(
s
t
)
=
1
\mathcal{O}(s_t)=1
O(st)=1,若未完成则为0,若推理结果错误则为-1。
为此,可以得到一个Reward打分函数:
R ( s t ) = O ( s t ) + C ( s t ) R(s_t) = \mathcal{O}(s_t) + \mathcal{C}(s_t) R(st)=O(st)+C(st)
当整个树搜索完成扩张(Expand)之后,后面需要进行回溯(Backup),更新公式如下:
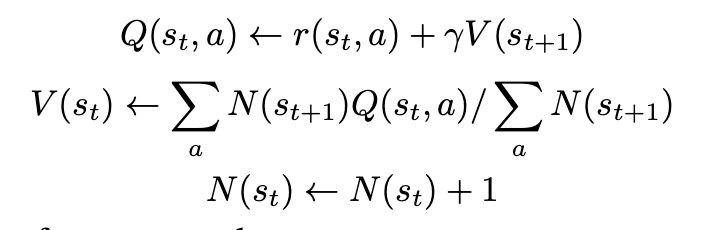
其中
N
(
s
t
)
N(s_t)
N(st)是一个计数器。
假设整棵树的深度为
T
T
T,即reasoning chain最多有
T
T
T个步骤。在每个步骤时
t
∈
[
1
,
T
]
t\in[1, T]
t∈[1,T],都将会构建一个pair,其中正样本为具有最高
Q
Q
Q值的路径,负样本则为具有最低
Q
Q
Q值的路径。因此,最终可以获得
T
T
T个pair。
2.2 迭代式DPO
考虑到偏好数据中可能会存在噪声,此时采用conservation version DPO
参考文献:A note on dpo with noisy preferences & relationship to ipo.
conservation version是指对于一些可能是噪声的偏好数据,将 ( y w > y l ) (y_w>y_l) (yw>yl)逆转为 ( y l > y w ) (y_l>y_w) (yl>yw)。
定义一个标签平滑系数:
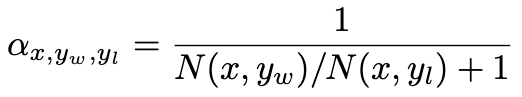
DPO中两个偏好样本之间的Reward差为:
h π θ y w , y l = log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) − log π θ ( y l ∣ x ) π r e f ( y l ∣ x ) h^{y_w, y_l}_{\pi_{\theta}}=\log{\frac{\pi_{\theta}(y_w|x)}{\pi_{ref}(y_w|x)}} - \log{\frac{\pi_{\theta}(y_l|x)}{\pi_{ref}(y_l|x)}} hπθyw,yl=logπref(yw∣x)πθ(yw∣x)−logπref(yl∣x)πθ(yl∣x)
那么,loss定义为:
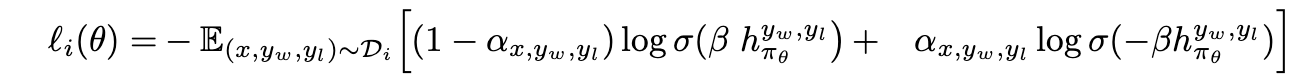
相当于一部分
(
y
w
,
y
l
)
(y_w, y_l)
(yw,yl)会被反转。
三、实验
基座模型:Mistral-7B,
基座模型进行SFT训练,训练数据为:https://huggingface.co/datasets/akjindal53244/Arithmo-Data
训练设备:4台A100(40G)
训练细节:

数据集:
- GSM8K、MATH
- ARC、CSQA、OpenBookQA、AI2Science
实验结果:
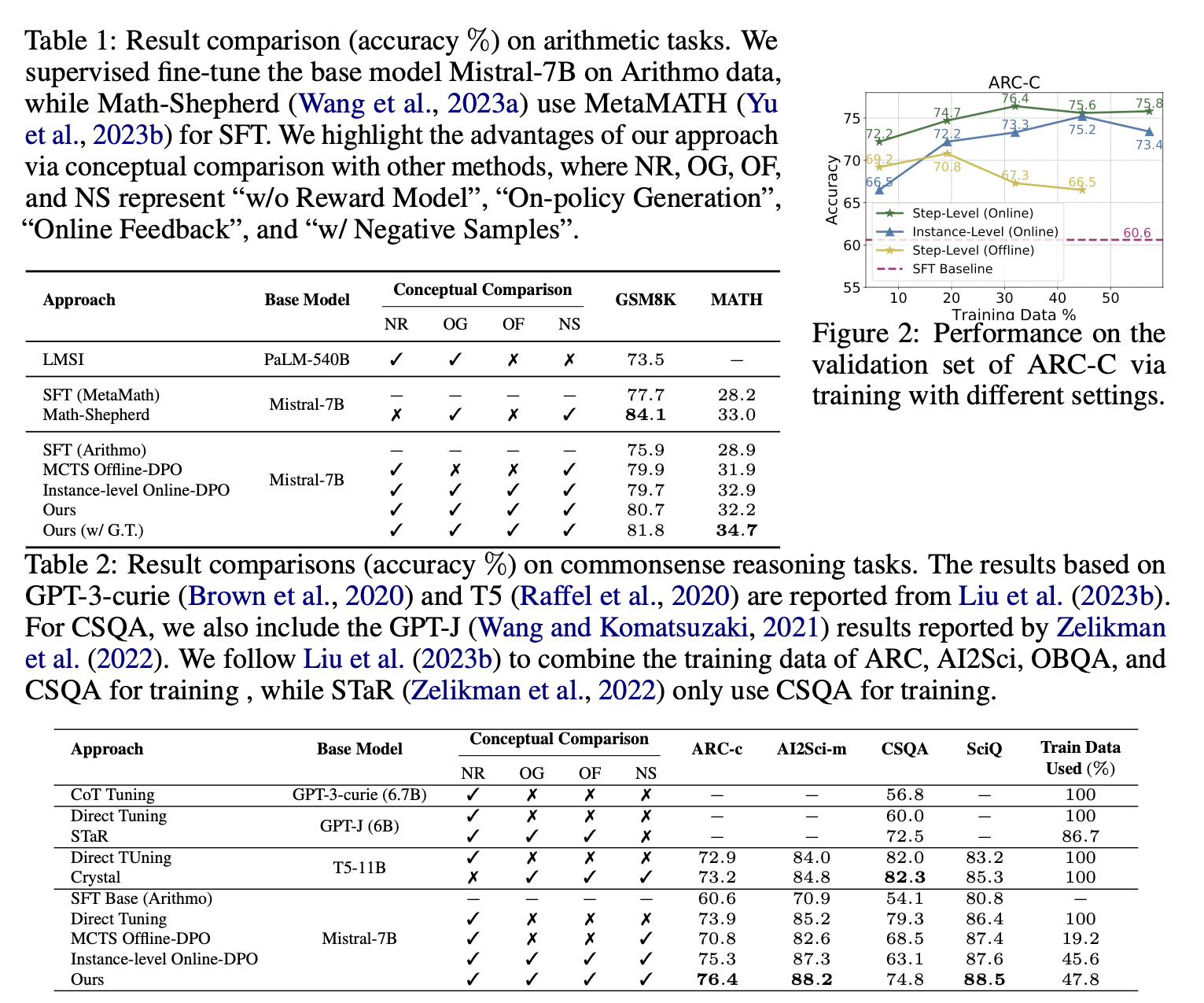


















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











