







目录
Out-of-distribution detection in classifiers via generation
前言
本次专栏中继续介绍一种OOD样本的生成方法,在该篇文章中,作者将OOD样本划分成两大类别,也就是我们之前一直讲的ID流形之外的简单OOD样本与ID流形边缘的困难OOD样本。这两个概念就是源于本篇我们要介绍的文章。然后,文章的名字依旧非常长,甚至直白到很难给它一个合适的缩写。
Out-of-distribution detection in classifiers via generation
论文链接:https://arxiv.org/pdf/1910.04241.pdf
Motivation
在上一次的专栏中,我们介绍过一个生成OOD边缘样本的方法,而在本文中,作者更进一步,首先将OOD样本分成两类:其一是分布在ID数据流形之外的样本,其二是分布在ID数据流形边缘的样本。针对这两类OOD样本,作者分别提出了对应的生成方法,并结合ID数据和这些得到的OOD数据,训练一个二分类器,从而判断数据是否是OOD。通过这样直接分类的方法来提升OOD检测的能力就是本文想要实现的,而最大的贡献或者说难点就在于如何对应生成这两类样本。
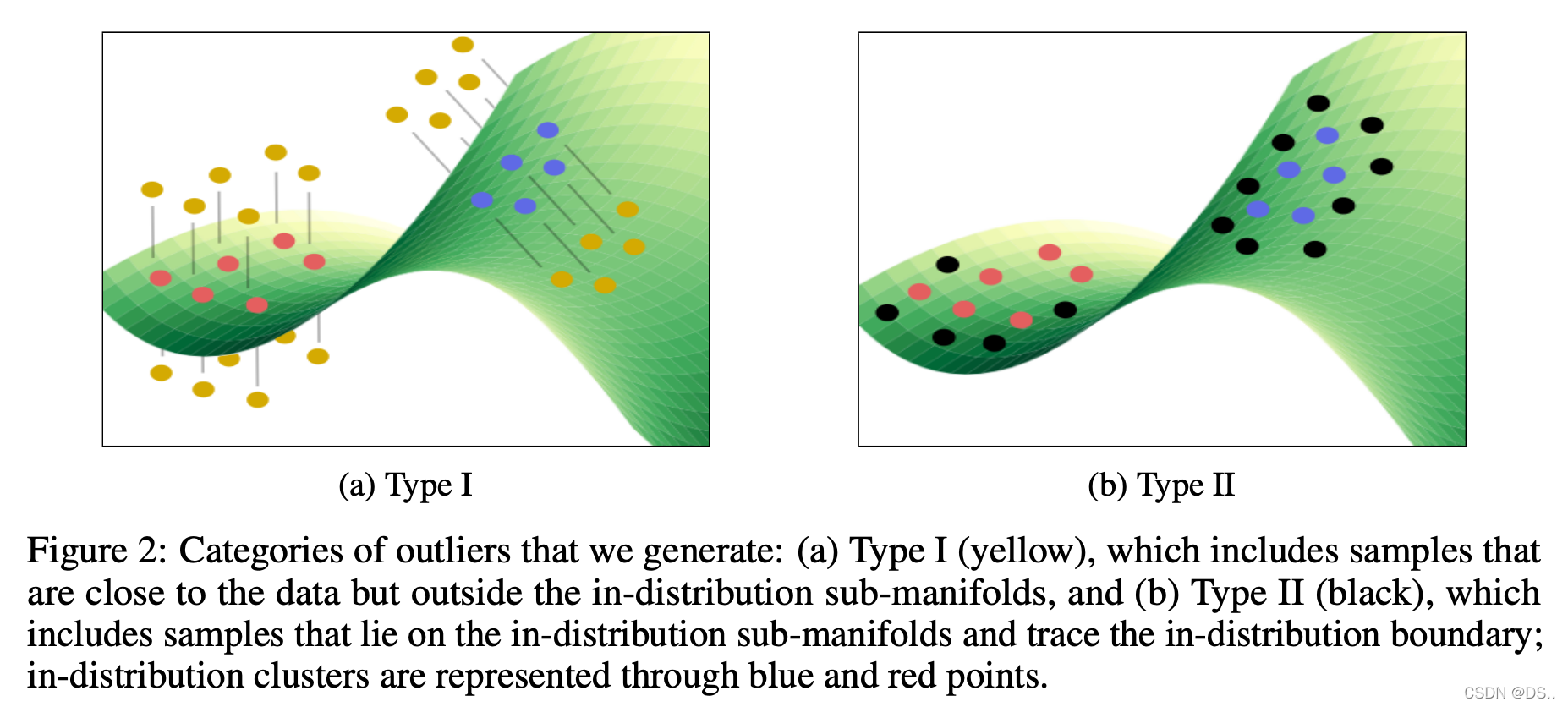
上面的示意图展示了作者提到的两类OOD样本点分布状态:一类分布在ID数据流形之外,另一类分布在ID数据流形的边缘。下面四幅图是作者生成的真实数据集上两类样本的效果图:

接下来,我们详细说明文章中如何生成这两类样本。
Approach
作者首先训练了一个自编码器。用来表示编码器,它将输入图像映射到隐空间,得到特征向量,可以表示为:
。用
来表示解码器,它将隐空间向量映射为重构图像,可以表示为:
。
生成第一类OOD样本:
首先介绍如何获得第一类样本,也就是分布在ID数据流形之外的OOD数据。
对于任意的输入样本,通过
可以获得对应的特征向量,进一步利用
可以得到重构图像。这里,如果将输入图像沿着与
处梯度垂直的方向推出一段距离,那么得到的
将不在ID数据的流形上,这样我们就获得了第一类OOD数据。
在获得梯度方向后,我们要沿着与梯度方向垂直的方向去移动,也就是的零空间。零空间指的就是与
垂直的向量构成的空间。文章中用
来表示。对任意的
,都可以使得输入图像远离ID数据流形:
生成第二类OOD样本:
作者使用马氏距离来衡量样本到ID数据分布的距离。对于任意的输入,我们通过编码器
将其映射到特征空间或者叫做隐空间。另一方面,我们也可以获得所有训练的ID数据在隐空间的特征表示,从而计算出均值向量
与特征的协方差矩阵
,有了这两个参数,就可以计算任意输入样本到ID数据特征分布的马氏距离:
根据上述平方马氏距离,就可以判断一个特征向量是否远离ID数据的特征分布。从而,我们可以在空间中采样随机噪声,然后计算其与ID特征分布的马氏距离,若大于某个阈值,则为ID分布的边缘,对应生成的样本可以看作是OOD样本,也就是分布在ID数据边缘的样本。
训练分类器:
有了第一类OOD数据和第二类OOD数据,再结合原始的ID数据,我们可以很容易的训练一个二分类器,分类器输出的置信度结果可以用于计算AUROC和AUPR。下面给出作者在MNIST还有Fashion-MNIST上的实验结果:
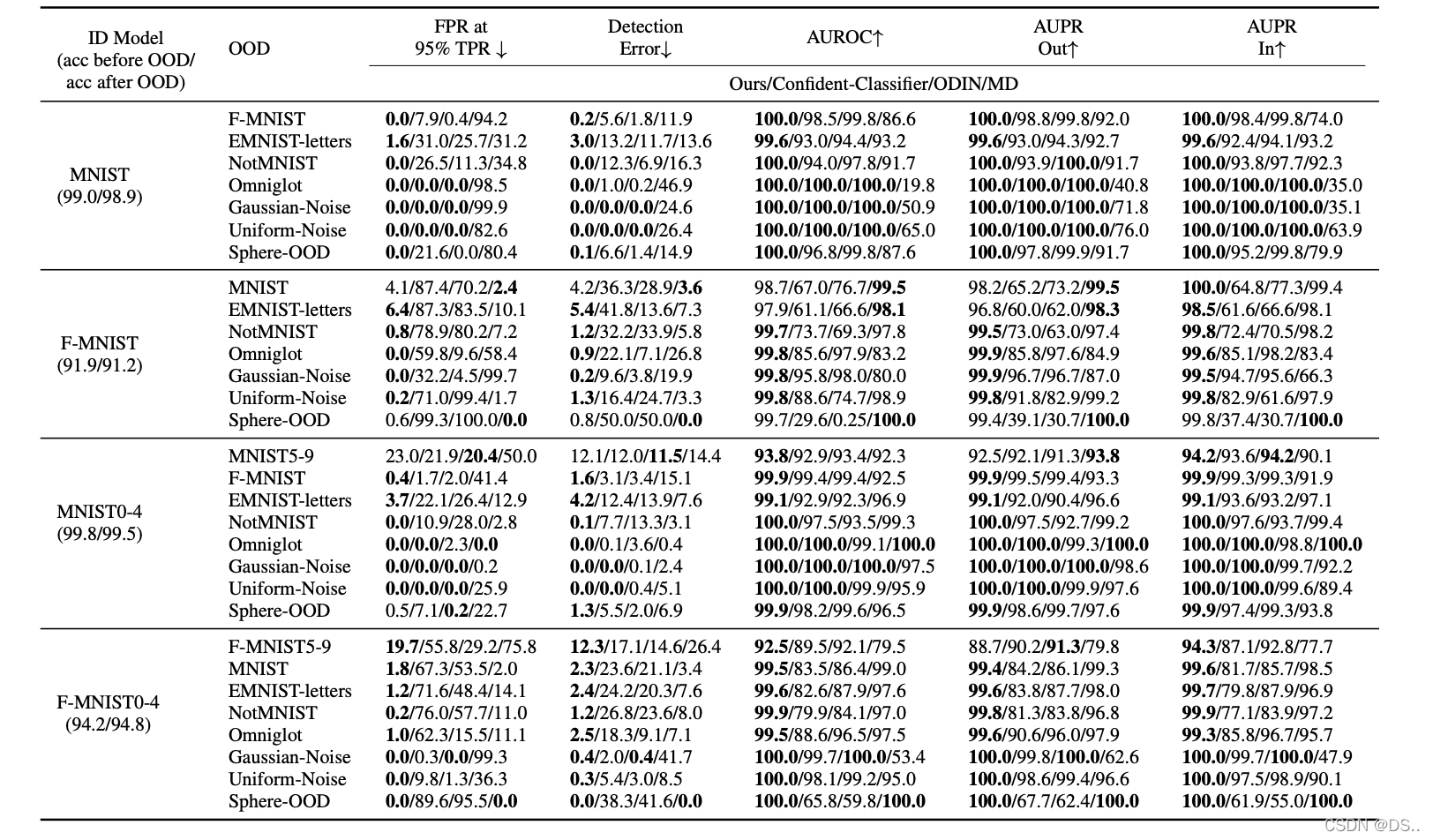
总之从实验结果来看,本文中提出的方法要比之前的好一些。
Discussion
通过这一次专栏以及上一期专栏,我们可以看到引入人工生成的OOD样本对于提升OOD检测的性能是有帮助的。另外,这两次专栏中提到的生成方法,最大的也是共同的缺陷就在于图像生成困难,在MNIST或者是Fashion-MNIST等小数据集上效果还不错,但是对于ImageNet或者是LSUN等大尺寸图像,就比较难以应用。可以考虑使用图像特征进行辅助判断,在下面的这篇文章中,作者就是从特征角度出发,很好的提升了OOD检测的效果,链接如下:
https://arxiv.org/pdf/2112.11648.pdf

















 27
27

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









