






CCPD数据集
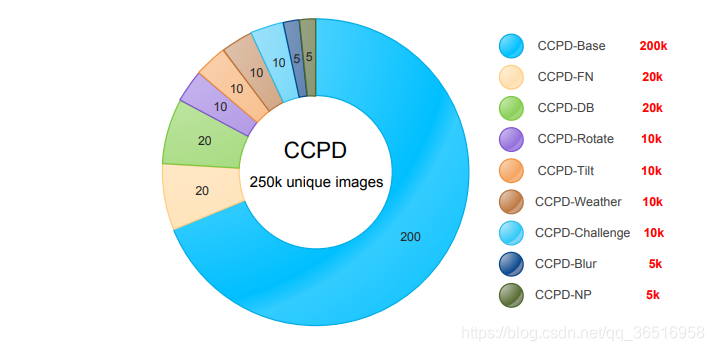
这个数据集十分之大,大概有30W张车牌图片,是在合肥这座城市进行的数据采集。我们根据文件的标签把车牌图片裁剪出来,以便于后面的CRNN训练。

那么我们来看一下数据的标签 ,以025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg为例
这一长串的图片名其中包含了车牌图片
025代表车牌图片占整个图片的比例
154&383_386&473代表车牌左上角和右下角的坐标值
386&473_177&454_154&383_363&402代表车牌的四个坐标值
0_0_22_27_27_33_16代表车牌号码
provinces = [“皖”, “沪”, “津”, “渝”, “冀”, “晋”, “蒙”, “辽”, “吉”, “黑”, “苏”, “浙”, “京”, “闽”, “赣”, “鲁”, “豫”, “鄂”, “湘”, “粤”, “桂”, “琼”, “川”, “贵”, “云”, “藏”, “陕”, “甘”, “青”, “宁”, “新”, “警”, “学”, “O”]
alphabets = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’,
‘X’, ‘Y’, ‘Z’, ‘O’]
ads = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’,‘Y’, ‘Z’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘O’]
那么第一个provinces就是“皖”,第二个alphabets就是’A’,后面的就是“V006R”
合起来就是皖AV006R
那么我们怎么根据以上的标签来对图片进行裁剪呢?
首先需要产生一个txt文本来记录所有图片名
gettex.py主要用来生成txt文本
import os
p="C:/ccpd2019/CCPD2019/ccpd_base/"
data = os.listdir(p)
filename="C:/pytorch/crnn.pytorch-master/data_create/mytxtfile.txt"
file = open(filename,'a')
for i in range(len(data)):
s = str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
file.write(s)
file.close()
print("保存文件成功");

然后在这个txt文本中随机选取一些图片,我主要取得是中间的一部分,倾斜程度比较小
cropped.py主要用来对图片进行裁剪
import cv2
import os
def new_label(old_label):
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙",
"京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂",
"琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学",
"O"]
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
# code 2
char_dict = {"京": 0, "沪": 1, "津": 2, "渝": 3, "冀": 4, "晋": 5, "蒙": 6, "辽": 7, "吉": 8, "黑": 9, "苏": 10,
"浙": 11, "皖": 12, "闽": 13, "赣": 14, "鲁": 15, "豫": 16, "鄂": 17, "湘": 18, "粤": 19, "桂": 20,
"琼": 21, "川": 22, "贵": 23, "云": 24, "藏": 25, "陕": 26, "甘": 27, "青": 28, "宁": 29, "新": 30,
"0": 31, "1": 32, "2": 33, "3": 34, "4": 35, "5": 36, "6": 37, "7": 38, "8": 39, "9": 40,
"A": 41, "B": 42, "C": 43, "D": 44, "E": 45, "F": 46, "G": 47, "H": 48, "J": 49, "K": 50,
"L": 51, "M": 52, "N": 53, "P": 54, "Q": 55, "R": 56, "S": 57, "T": 58, "U": 59, "V": 60,
"W": 61, "X": 62, "Y": 63, "Z": 64}
car_code2 = ""
for i, number in enumerate(old_label.split("_")):
if i == 0:
car_origin_number = provinces[int(number)]
else:
car_origin_number = ads[int(number)]
# car_code2.append(char_dict[car_origin_number])
car_code2+=str(car_origin_number)
return car_code2
f=open('train.txt', encoding="utf-8")
txt=[]
for line in f:
txt.append(line.strip())
path="C:/ccpd2019/CCPD2019/ccpd_base/"
path_new=[]
car_code2=[]
for i in range(len(txt)):
path_new=os.path.join(path,txt[i])
img=cv2.imread(path_new)
img_name = path_new
iname = img_name.rsplit('/', 1)[-1].rsplit('.', 1)[0].split('-')
old_label=iname[-3]
old_label=new_label(old_label)
[leftUp, rightDown] = [[int(eel) for eel in el.split('&')] for el in iname[2].split('_')]
cropped=img[leftUp[1]:rightDown[1],leftUp[0]:rightDown[0]]
pic = cv2.resize(cropped, (240, 80), interpolation=cv2.INTER_CUBIC)
imagename = "images/" + str(old_label) + ".jpg"
# cv2.imwrite(imagename, cropped)
cv2.imencode('.jpg', pic)[1].tofile(imagename)
print(i);
最后我们得到

数据处理完,就可以送入CRNN模型进行训练了。


















 1731
1731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











